 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMG-Bench: A New Challenging Benchmark for Skeleton-based Online Micro Hand Gesture Recognition
Dec 18, 2025Online micro gesture recognition from hand skeletons is critical for VR/AR interaction but faces challenges due to limited public datasets and task-specific algorithms. Micro gestures involve subtle motion patterns, which make constructing datasets with precise skeletons and frame-level annotations difficult. To this end, we develop a multi-view self-supervised pipeline to automatically generate skeleton data, complemented by heuristic rules and expert refinement for semi-automatic annotation. Based on this pipeline, we introduce OMG-Bench, the first large-scale public benchmark for skeleton-based online micro gesture recognition. It features 40 fine-grained gesture classes with 13,948 instances across 1,272 sequences, characterized by subtle motions, rapid dynamics, and continuous execution. To tackle these challenges, we propose Hierarchical Memory-Augmented Transformer (HMATr), an end-to-end framework that unifies gesture detection and classification by leveraging hierarchical memory banks which store frame-level details and window-level semantics to preserve historical context. In addition, it employs learnable position-aware queries initialized from the memory to implicitly encode gesture positions and semantics. Experiments show that HMATr outperforms state-of-the-art methods by 7.6\% in detection rate, establishing a strong baseline for online micro gesture recognition. Project page: https://omg-bench.github.io/
See You Soon: Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image
Feb 05, 2023Reconstructing interacting hands from a single RGB image is a very challenging task. On the one hand, severe mutual occlusion and similar local appearance between two hands confuse the extraction of visual features, resulting in the misalignment of estimated hand meshes and the image. On the other hand, there are complex interaction patterns between interacting hands, which significantly increases the solution space of hand poses and increases the difficulty of network learning. In this paper, we propose a decoupled iterative refinement framework to achieve pixel-alignment hand reconstruction while efficiently modeling the spatial relationship between hands. Specifically, we define two feature spaces with different characteristics, namely 2D visual feature space and 3D joint feature space. First, we obtain joint-wise features from the visual feature map and utilize a graph convolution network and a transformer to perform intra- and inter-hand information interaction in the 3D joint feature space, respectively. Then, we project the joint features with global information back into the 2D visual feature space in an obfuscation-free manner and utilize the 2D convolution for pixel-wise enhancement. By performing multiple alternate enhancements in the two feature spaces, our method can achieve an accurate and robust reconstruction of interacting hands. Our method outperforms all existing two-hand reconstruction methods by a large margin on the InterHand2.6M dataset. Meanwhile, our method shows a strong generalization ability for in-the-wild images.
Can Shuffling Video Benefit Temporal Bias Problem: A Novel Training Framework for Temporal Grounding
Aug 05, 2022
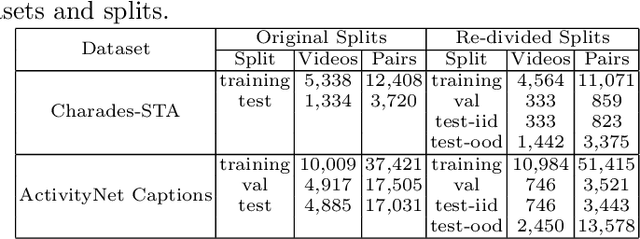
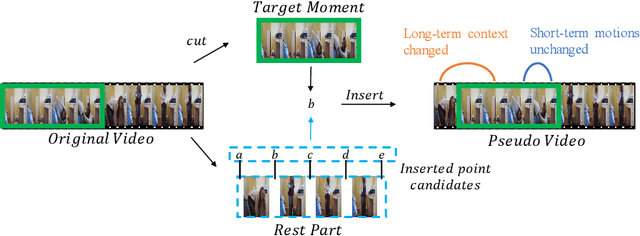
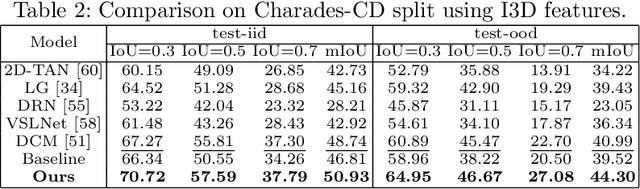
Temporal grounding aims to locate a target video moment that semantically corresponds to the given sentence query in an untrimmed video. However, recent works find that existing methods suffer a severe temporal bias problem. These methods do not reason the target moment locations based on the visual-textual semantic alignment but over-rely on the temporal biases of queries in training sets. To this end, this paper proposes a novel training framework for grounding models to use shuffled videos to address temporal bias problem without losing grounding accuracy. Our framework introduces two auxiliary tasks, cross-modal matching and temporal order discrimination, to promote the grounding model training. The cross-modal matching task leverages the content consistency between shuffled and original videos to force the grounding model to mine visual contents to semantically match queries. The temporal order discrimination task leverages the difference in temporal order to strengthen the understanding of long-term temporal contexts. Extensive experiments on Charades-STA and ActivityNet Captions demonstrate the effectiveness of our method for mitigating the reliance on temporal biases and strengthening the model's generalization ability against the different temporal distributions. Code is available at https://github.com/haojc/ShufflingVideosForTSG.
AWR: Adaptive Weighting Regression for 3D Hand Pose Estimation
Jul 19, 2020

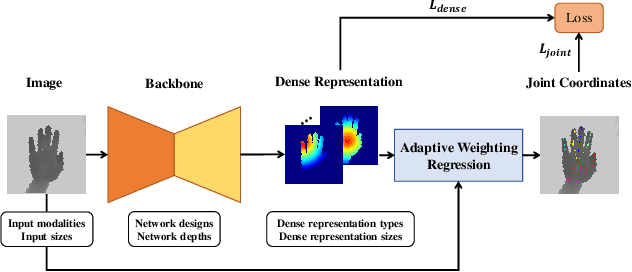

In this paper, we propose an adaptive weighting regression (AWR) method to leverage the advantages of both detection-based and regression-based methods. Hand joint coordinates are estimated as discrete integration of all pixels in dense representation, guided by adaptive weight maps. This learnable aggregation process introduces both dense and joint supervision that allows end-to-end training and brings adaptability to weight maps, making the network more accurate and robust. Comprehensive exploration experiments are conducted to validate the effectiveness and generality of AWR under various experimental settings, especially its usefulness for different types of dense representation and input modality. Our method outperforms other state-of-the-art methods on four publicly available datasets, including NYU, ICVL, MSRA and HANDS 2017 dataset.
* Accepted by AAAI-2020
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
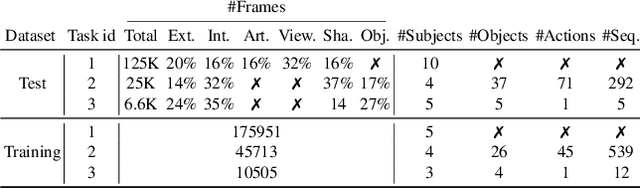
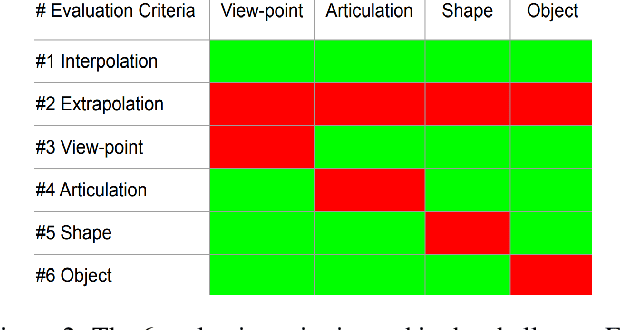
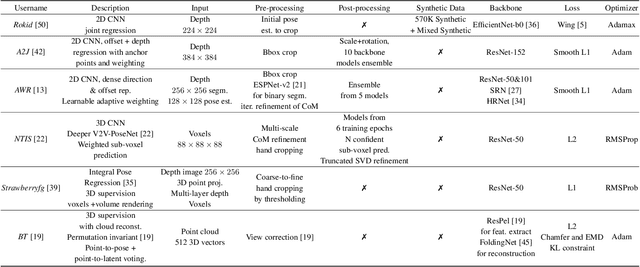
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.