 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrAME: Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation
Jul 02, 2024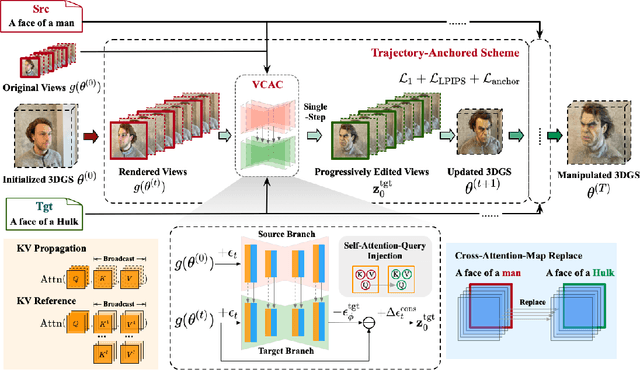



Despite significant strides in the field of 3D scene editing, current methods encounter substantial challenge, particularly in preserving 3D consistency in multi-view editing process. To tackle this challenge, we propose a progressive 3D editing strategy that ensures multi-view consistency via a Trajectory-Anchored Scheme (TAS) with a dual-branch editing mechanism. Specifically, TAS facilitates a tightly coupled iterative process between 2D view editing and 3D updating, preventing error accumulation yielded from text-to-image process. Additionally, we explore the relationship between optimization-based methods and reconstruction-based methods, offering a unified perspective for selecting superior design choice, supporting the rationale behind the designed TAS. We further present a tuning-free View-Consistent Attention Control (VCAC) module that leverages cross-view semantic and geometric reference from the source branch to yield aligned views from the target branch during the editing of 2D views. To validate the effectiveness of our method, we analyze 2D examples to demonstrate the improved consistency with the VCAC module. Further extensive quantitative and qualitative results in text-guided 3D scene editing indicate that our method achieves superior editing quality compared to state-of-the-art methods. We will make the complete codebase publicly available following the conclusion of the double-blind review process.
Hyper-3DG: Text-to-3D Gaussian Generation via Hypergraph
Mar 14, 2024



Text-to-3D generation represents an exciting field that has seen rapid advancements, facilitating the transformation of textual descriptions into detailed 3D models. However, current progress often neglects the intricate high-order correlation of geometry and texture within 3D objects, leading to challenges such as over-smoothness, over-saturation and the Janus problem. In this work, we propose a method named ``3D Gaussian Generation via Hypergraph (Hyper-3DG)'', designed to capture the sophisticated high-order correlations present within 3D objects. Our framework is anchored by a well-established mainflow and an essential module, named ``Geometry and Texture Hypergraph Refiner (HGRefiner)''. This module not only refines the representation of 3D Gaussians but also accelerates the update process of these 3D Gaussians by conducting the Patch-3DGS Hypergraph Learning on both explicit attributes and latent visual features. Our framework allows for the production of finely generated 3D objects within a cohesive optimization, effectively circumventing degradation. Extensive experimentation has shown that our proposed method significantly enhances the quality of 3D generation while incurring no additional computational overhead for the underlying framework. (Project code: https://github.com/yjhboy/Hyper3DG)
OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
Feb 29, 2024In this paper, we delve into the creation of one-shot hand avatars, attaining high-fidelity and drivable hand representations swiftly from a single image. With the burgeoning domains of the digital human, the need for quick and personalized hand avatar creation has become increasingly critical. Existing techniques typically require extensive input data and may prove cumbersome or even impractical in certain scenarios. To enhance accessibility, we present a novel method OHTA (One-shot Hand avaTAr) that enables the creation of detailed hand avatars from merely one image. OHTA tackles the inherent difficulties of this data-limited problem by learning and utilizing data-driven hand priors. Specifically, we design a hand prior model initially employed for 1) learning various hand priors with available data and subsequently for 2) the inversion and fitting of the target identity with prior knowledge. OHTA demonstrates the capability to create high-fidelity hand avatars with consistent animatable quality, solely relying on a single image. Furthermore, we illustrate the versatility of OHTA through diverse applications, encompassing text-to-avatar conversion, hand editing, and identity latent space manipulation.
Joint2Human: High-quality 3D Human Generation via Compact Spherical Embedding of 3D Joints
Dec 14, 2023
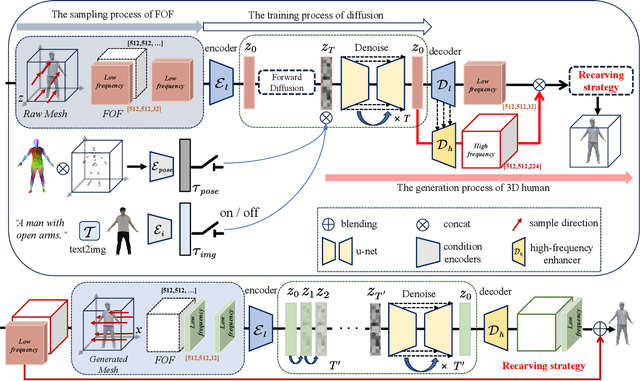

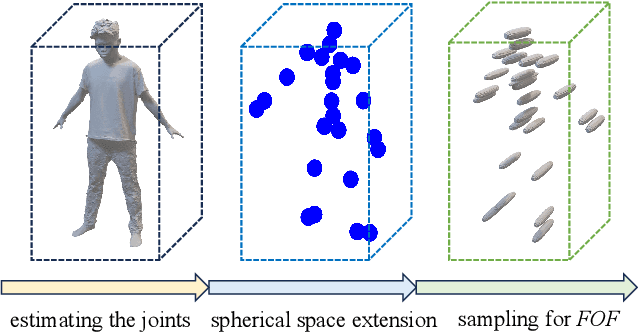
3D human generation is increasingly significant in various applications. However, the direct use of 2D generative methods in 3D generation often results in significant loss of local details, while methods that reconstruct geometry from generated images struggle with global view consistency. In this work, we introduce Joint2Human, a novel method that leverages 2D diffusion models to generate detailed 3D human geometry directly, ensuring both global structure and local details. To achieve this, we employ the Fourier occupancy field (FOF) representation, enabling the direct production of 3D shapes as preliminary results using 2D generative models. With the proposed high-frequency enhancer and the multi-view recarving strategy, our method can seamlessly integrate the details from different views into a uniform global shape.To better utilize the 3D human prior and enhance control over the generated geometry, we introduce a compact spherical embedding of 3D joints. This allows for effective application of pose guidance during the generation process. Additionally, our method is capable of generating 3D humans guided by textual inputs. Our experimental results demonstrate the capability of our method to ensure global structure, local details, high resolution, and low computational cost, simultaneously. More results and code can be found on our project page at http://cic.tju.edu.cn/faculty/likun/projects/Joint2Human.
Reconstructing Interacting Hands with Interaction Prior from Monocular Images
Aug 27, 2023



Reconstructing interacting hands from monocular images is indispensable in AR/VR applications. Most existing solutions rely on the accurate localization of each skeleton joint. However, these methods tend to be unreliable due to the severe occlusion and confusing similarity among adjacent hand parts. This also defies human perception because humans can quickly imitate an interaction pattern without localizing all joints. Our key idea is to first construct a two-hand interaction prior and recast the interaction reconstruction task as the conditional sampling from the prior. To expand more interaction states, a large-scale multimodal dataset with physical plausibility is proposed. Then a VAE is trained to further condense these interaction patterns as latent codes in a prior distribution. When looking for image cues that contribute to interaction prior sampling, we propose the interaction adjacency heatmap (IAH). Compared with a joint-wise heatmap for localization, IAH assigns denser visible features to those invisible joints. Compared with an all-in-one visible heatmap, it provides more fine-grained local interaction information in each interaction region. Finally, the correlations between the extracted features and corresponding interaction codes are linked by the ViT module. Comprehensive evaluations on benchmark datasets have verified the effectiveness of this framework. The code and dataset are publicly available at https://github.com/binghui-z/InterPrior_pytorch
Realistic Full-Body Tracking from Sparse Observations via Joint-Level Modeling
Aug 17, 2023To bridge the physical and virtual worlds for rapidly developed VR/AR applications, the ability to realistically drive 3D full-body avatars is of great significance. Although real-time body tracking with only the head-mounted displays (HMDs) and hand controllers is heavily under-constrained, a carefully designed end-to-end neural network is of great potential to solve the problem by learning from large-scale motion data. To this end, we propose a two-stage framework that can obtain accurate and smooth full-body motions with the three tracking signals of head and hands only. Our framework explicitly models the joint-level features in the first stage and utilizes them as spatiotemporal tokens for alternating spatial and temporal transformer blocks to capture joint-level correlations in the second stage. Furthermore, we design a set of loss terms to constrain the task of a high degree of freedom, such that we can exploit the potential of our joint-level modeling. With extensive experiments on the AMASS motion dataset and real-captured data, we validate the effectiveness of our designs and show our proposed method can achieve more accurate and smooth motion compared to existing approaches.
See You Soon: Decoupled Iterative Refinement Framework for Interacting Hands Reconstruction from a Single RGB Image
Feb 05, 2023Reconstructing interacting hands from a single RGB image is a very challenging task. On the one hand, severe mutual occlusion and similar local appearance between two hands confuse the extraction of visual features, resulting in the misalignment of estimated hand meshes and the image. On the other hand, there are complex interaction patterns between interacting hands, which significantly increases the solution space of hand poses and increases the difficulty of network learning. In this paper, we propose a decoupled iterative refinement framework to achieve pixel-alignment hand reconstruction while efficiently modeling the spatial relationship between hands. Specifically, we define two feature spaces with different characteristics, namely 2D visual feature space and 3D joint feature space. First, we obtain joint-wise features from the visual feature map and utilize a graph convolution network and a transformer to perform intra- and inter-hand information interaction in the 3D joint feature space, respectively. Then, we project the joint features with global information back into the 2D visual feature space in an obfuscation-free manner and utilize the 2D convolution for pixel-wise enhancement. By performing multiple alternate enhancements in the two feature spaces, our method can achieve an accurate and robust reconstruction of interacting hands. Our method outperforms all existing two-hand reconstruction methods by a large margin on the InterHand2.6M dataset. Meanwhile, our method shows a strong generalization ability for in-the-wild images.
Hand Pose Estimation via Multiview Collaborative Self-Supervised Learning
Feb 02, 20233D hand pose estimation has made significant progress in recent years. However, the improvement is highly dependent on the emergence of large-scale annotated datasets. To alleviate the label-hungry limitation, we propose a multi-view collaborative self-supervised learning framework, HaMuCo, that estimates hand pose only with pseudo labels for training. We use a two-stage strategy to tackle the noisy label challenge and the multi-view ``groupthink'' problem. In the first stage, we estimate the 3D hand poses for each view independently. In the second stage, we employ a cross-view interaction network to capture the cross-view correlated features and use multi-view consistency loss to achieve collaborative learning among views. To further enhance the collaboration between single-view and multi-view, we fuse the results of all views to supervise the single-view network. To summarize, we introduce collaborative learning in two folds, the cross-view level and the multi- to single-view level. Extensive experiments show that our method can achieve state-of-the-art performance on multi-view self-supervised hand pose estimation. Moreover, ablation studies verify the effectiveness of each component. Results on multiple datasets further demonstrate the generalization ability of our network.
3D Room Layout Estimation from a Cubemap of Panorama Image via Deep Manhattan Hough Transform
Jul 19, 2022

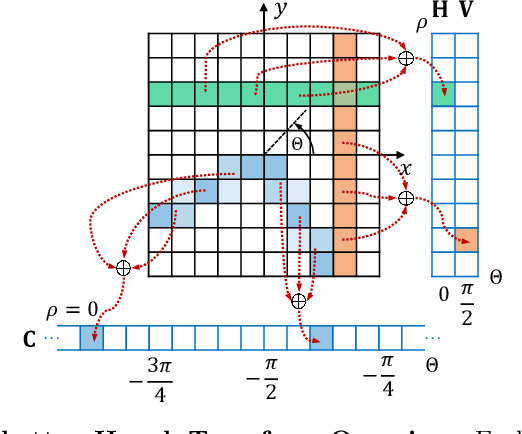
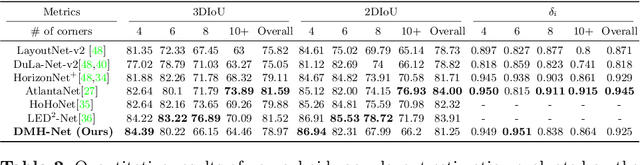
Significant geometric structures can be compactly described by global wireframes in the estimation of 3D room layout from a single panoramic image. Based on this observation, we present an alternative approach to estimate the walls in 3D space by modeling long-range geometric patterns in a learnable Hough Transform block. We transform the image feature from a cubemap tile to the Hough space of a Manhattan world and directly map the feature to the geometric output. The convolutional layers not only learn the local gradient-like line features, but also utilize the global information to successfully predict occluded walls with a simple network structure. Unlike most previous work, the predictions are performed individually on each cubemap tile, and then assembled to get the layout estimation. Experimental results show that we achieve comparable results with recent state-of-the-art in prediction accuracy and performance. Code is available at https://github.com/Starrah/DMH-Net.