 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-React: Towards Emotionally Controlled Synthesis of Human Reactions
Aug 08, 2025Emotion serves as an essential component in daily human interactions. Existing human motion generation frameworks do not consider the impact of emotions, which reduces naturalness and limits their application in interactive tasks, such as human reaction synthesis. In this work, we introduce a novel task: generating diverse reaction motions in response to different emotional cues. However, learning emotion representation from limited motion data and incorporating it into a motion generation framework remains a challenging problem. To address the above obstacles, we introduce a semi-supervised emotion prior in an actor-reactor diffusion model to facilitate emotion-driven reaction synthesis. Specifically, based on the observation that motion clips within a short sequence tend to share the same emotion, we first devise a semi-supervised learning framework to train an emotion prior. With this prior, we further train an actor-reactor diffusion model to generate reactions by considering both spatial interaction and emotional response. Finally, given a motion sequence of an actor, our approach can generate realistic reactions under various emotional conditions. Experimental results demonstrate that our model outperforms existing reaction generation methods. The code and data will be made publicly available at https://ereact.github.io/
Nonrigid Object Contact Estimation With Regional Unwrapping Transformer
Aug 30, 2023



Acquiring contact patterns between hands and nonrigid objects is a common concern in the vision and robotics community. However, existing learning-based methods focus more on contact with rigid ones from monocular images. When adopting them for nonrigid contact, a major problem is that the existing contact representation is restricted by the geometry of the object. Consequently, contact neighborhoods are stored in an unordered manner and contact features are difficult to align with image cues. At the core of our approach lies a novel hand-object contact representation called RUPs (Region Unwrapping Profiles), which unwrap the roughly estimated hand-object surfaces as multiple high-resolution 2D regional profiles. The region grouping strategy is consistent with the hand kinematic bone division because they are the primitive initiators for a composite contact pattern. Based on this representation, our Regional Unwrapping Transformer (RUFormer) learns the correlation priors across regions from monocular inputs and predicts corresponding contact and deformed transformations. Our experiments demonstrate that the proposed framework can robustly estimate the deformed degrees and deformed transformations, which makes it suitable for both nonrigid and rigid contact.
Reconstructing Interacting Hands with Interaction Prior from Monocular Images
Aug 27, 2023



Reconstructing interacting hands from monocular images is indispensable in AR/VR applications. Most existing solutions rely on the accurate localization of each skeleton joint. However, these methods tend to be unreliable due to the severe occlusion and confusing similarity among adjacent hand parts. This also defies human perception because humans can quickly imitate an interaction pattern without localizing all joints. Our key idea is to first construct a two-hand interaction prior and recast the interaction reconstruction task as the conditional sampling from the prior. To expand more interaction states, a large-scale multimodal dataset with physical plausibility is proposed. Then a VAE is trained to further condense these interaction patterns as latent codes in a prior distribution. When looking for image cues that contribute to interaction prior sampling, we propose the interaction adjacency heatmap (IAH). Compared with a joint-wise heatmap for localization, IAH assigns denser visible features to those invisible joints. Compared with an all-in-one visible heatmap, it provides more fine-grained local interaction information in each interaction region. Finally, the correlations between the extracted features and corresponding interaction codes are linked by the ViT module. Comprehensive evaluations on benchmark datasets have verified the effectiveness of this framework. The code and dataset are publicly available at https://github.com/binghui-z/InterPrior_pytorch
Semi-supervised Hand Appearance Recovery via Structure Disentanglement and Dual Adversarial Discrimination
Mar 11, 2023Enormous hand images with reliable annotations are collected through marker-based MoCap. Unfortunately, degradations caused by markers limit their application in hand appearance reconstruction. A clear appearance recovery insight is an image-to-image translation trained with unpaired data. However, most frameworks fail because there exists structure inconsistency from a degraded hand to a bare one. The core of our approach is to first disentangle the bare hand structure from those degraded images and then wrap the appearance to this structure with a dual adversarial discrimination (DAD) scheme. Both modules take full advantage of the semi-supervised learning paradigm: The structure disentanglement benefits from the modeling ability of ViT, and the translator is enhanced by the dual discrimination on both translation processes and translation results. Comprehensive evaluations have been conducted to prove that our framework can robustly recover photo-realistic hand appearance from diverse marker-contained and even object-occluded datasets. It provides a novel avenue to acquire bare hand appearance data for other downstream learning problems.The codes will be publicly available at https://www.yangangwang.com
HMDO: Markerless Multi-view Hand Manipulation Capture with Deformable Objects
Jan 18, 2023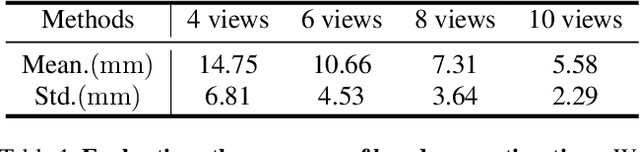

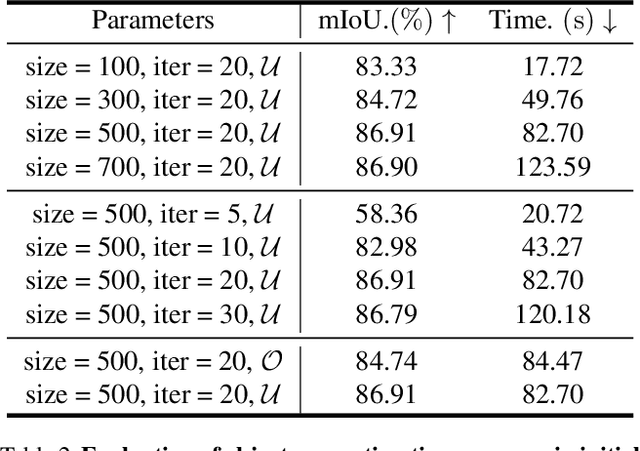
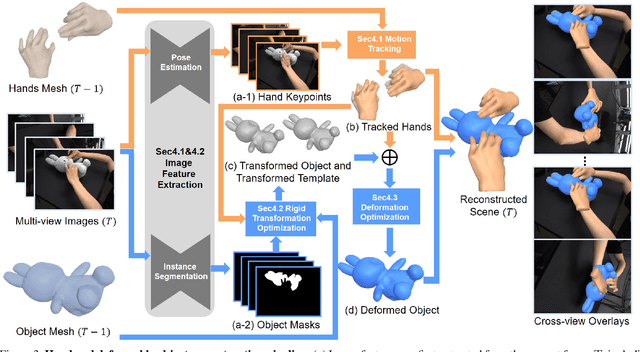
We construct the first markerless deformable interaction dataset recording interactive motions of the hands and deformable objects, called HMDO (Hand Manipulation with Deformable Objects). With our built multi-view capture system, it captures the deformable interactions with multiple perspectives, various object shapes, and diverse interactive forms. Our motivation is the current lack of hand and deformable object interaction datasets, as 3D hand and deformable object reconstruction is challenging. Mainly due to mutual occlusion, the interaction area is difficult to observe, the visual features between the hand and the object are entangled, and the reconstruction of the interaction area deformation is difficult. To tackle this challenge, we propose a method to annotate our captured data. Our key idea is to collaborate with estimated hand features to guide the object global pose estimation, and then optimize the deformation process of the object by analyzing the relationship between the hand and the object. Through comprehensive evaluation, the proposed method can reconstruct interactive motions of hands and deformable objects with high quality. HMDO currently consists of 21600 frames over 12 sequences. In the future, this dataset could boost the research of learning-based reconstruction of deformable interaction scenes.
Stability-driven Contact Reconstruction From Monocular Color Images
May 02, 2022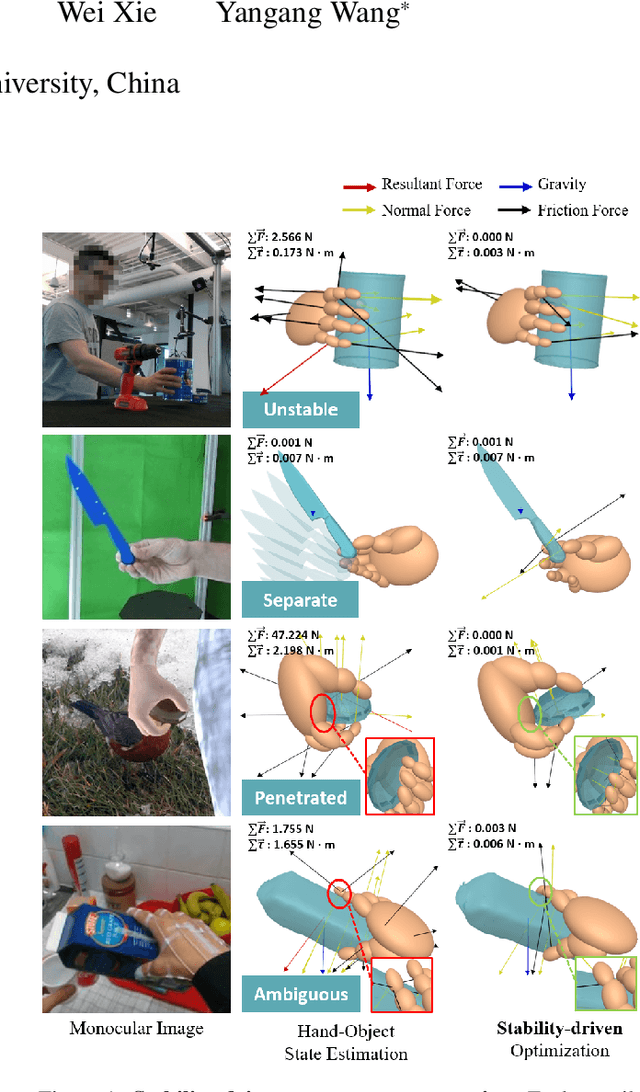
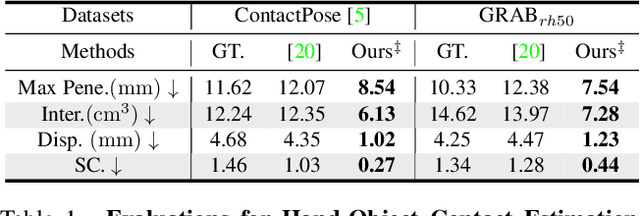
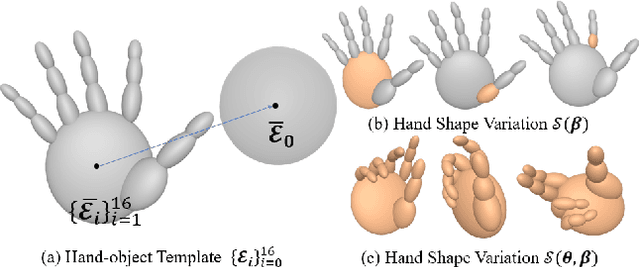

Physical contact provides additional constraints for hand-object state reconstruction as well as a basis for further understanding of interaction affordances. Estimating these severely occluded regions from monocular images presents a considerable challenge. Existing methods optimize the hand-object contact driven by distance threshold or prior from contact-labeled datasets. However, due to the number of subjects and objects involved in these indoor datasets being limited, the learned contact patterns could not be generalized easily. Our key idea is to reconstruct the contact pattern directly from monocular images, and then utilize the physical stability criterion in the simulation to optimize it. This criterion is defined by the resultant forces and contact distribution computed by the physics engine.Compared to existing solutions, our framework can be adapted to more personalized hands and diverse object shapes. Furthermore, an interaction dataset with extra physical attributes is created to verify the sim-to-real consistency of our methods. Through comprehensive evaluations, hand-object contact can be reconstructed with both accuracy and stability by the proposed framework.