 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointAction: 3D Points as Universal Action Representations for Robot Control
Jun 02, 2026Video-Action Models (VAMs) leverage the broad visual dynamics captured by pre-trained video diffusion models, offering a promising path toward generalizable robot manipulation. However, RGB-only video rollouts are not directly actionable: they leave metric 3D motion, contact geometry, and fine-grained spatial constraints under-specified, making action grounding ambiguous. Meanwhile, scaling action supervision across diverse tasks and embodiments remains costly. We present PointAction, a framework that bridges video predictions to robot actions through explicit point-based 4D modeling. PointAction fine-tunes a foundation video generation model to jointly predict future RGB frames and dynamic 3D pointmaps, producing temporally consistent 3D motion of task-relevant scene geometry. These point dynamics serve as a structured, embodiment-agnostic action interface, which a diffusion-based action decoder maps to executable robot actions. By using metric 3D point dynamics as the interface between video prediction and control, PointAction reduces the ambiguity of RGB-only action grounding and supports transfer across tasks and embodiments with limited action supervision. Experiments show that PointAction achieves state-of-the-art 4D generation quality on robot scenes, outperforms existing baselines in simulation, and generalizes to two real robot arms unseen during pretraining.
Vid2Sim: Generalizable, Video-based Reconstruction of Appearance, Geometry and Physics for Mesh-free Simulation
Jun 06, 2025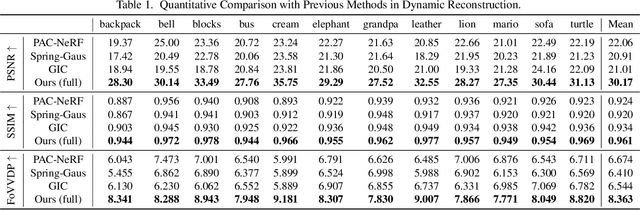
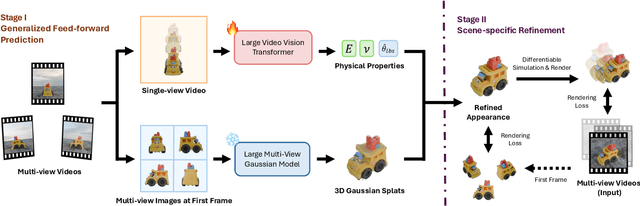
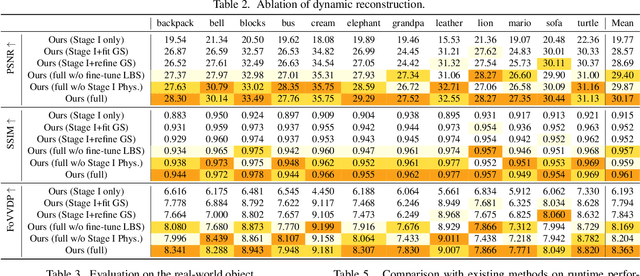

Faithfully reconstructing textured shapes and physical properties from videos presents an intriguing yet challenging problem. Significant efforts have been dedicated to advancing such a system identification problem in this area. Previous methods often rely on heavy optimization pipelines with a differentiable simulator and renderer to estimate physical parameters. However, these approaches frequently necessitate extensive hyperparameter tuning for each scene and involve a costly optimization process, which limits both their practicality and generalizability. In this work, we propose a novel framework, Vid2Sim, a generalizable video-based approach for recovering geometry and physical properties through a mesh-free reduced simulation based on Linear Blend Skinning (LBS), offering high computational efficiency and versatile representation capability. Specifically, Vid2Sim first reconstructs the observed configuration of the physical system from video using a feed-forward neural network trained to capture physical world knowledge. A lightweight optimization pipeline then refines the estimated appearance, geometry, and physical properties to closely align with video observations within just a few minutes. Additionally, after the reconstruction, Vid2Sim enables high-quality, mesh-free simulation with high efficiency. Extensive experiments demonstrate that our method achieves superior accuracy and efficiency in reconstructing geometry and physical properties from video data.
FOF-X: Towards Real-time Detailed Human Reconstruction from a Single Image
Dec 08, 2024We introduce FOF-X for real-time reconstruction of detailed human geometry from a single image. Balancing real-time speed against high-quality results is a persistent challenge, mainly due to the high computational demands of existing 3D representations. To address this, we propose Fourier Occupancy Field (FOF), an efficient 3D representation by learning the Fourier series. The core of FOF is to factorize a 3D occupancy field into a 2D vector field, retaining topology and spatial relationships within the 3D domain while facilitating compatibility with 2D convolutional neural networks. Such a representation bridges the gap between 3D and 2D domains, enabling the integration of human parametric models as priors and enhancing the reconstruction robustness. Based on FOF, we design a new reconstruction framework, FOF-X, to avoid the performance degradation caused by texture and lighting. This enables our real-time reconstruction system to better handle the domain gap between training images and real images. Additionally, in FOF-X, we enhance the inter-conversion algorithms between FOF and mesh representations with a Laplacian constraint and an automaton-based discontinuity matcher, improving both quality and robustness. We validate the strengths of our approach on different datasets and real-captured data, where FOF-X achieves new state-of-the-art results. The code will be released for research purposes.
LPSNet: End-to-End Human Pose and Shape Estimation with Lensless Imaging
Apr 08, 2024
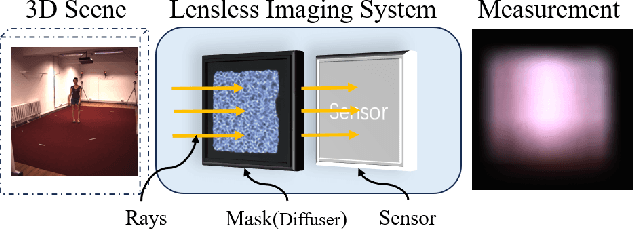
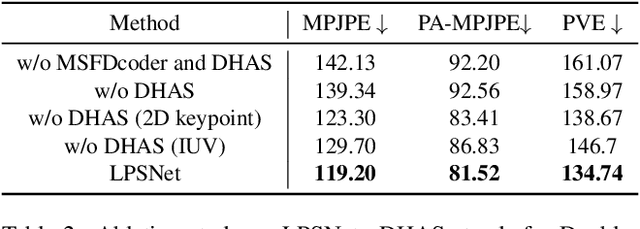
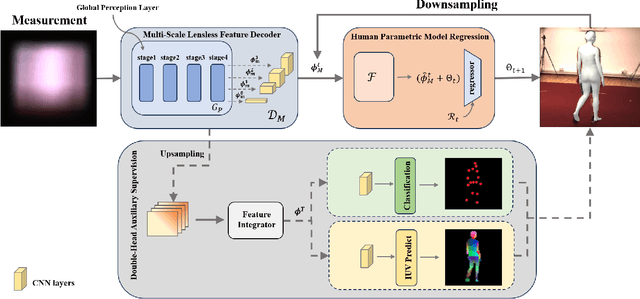
Human pose and shape (HPS) estimation with lensless imaging is not only beneficial to privacy protection but also can be used in covert surveillance scenarios due to the small size and simple structure of this device. However, this task presents significant challenges due to the inherent ambiguity of the captured measurements and lacks effective methods for directly estimating human pose and shape from lensless data. In this paper, we propose the first end-to-end framework to recover 3D human poses and shapes from lensless measurements to our knowledge. We specifically design a multi-scale lensless feature decoder to decode the lensless measurements through the optically encoded mask for efficient feature extraction. We also propose a double-head auxiliary supervision mechanism to improve the estimation accuracy of human limb ends. Besides, we establish a lensless imaging system and verify the effectiveness of our method on various datasets acquired by our lensless imaging system.
Joint2Human: High-quality 3D Human Generation via Compact Spherical Embedding of 3D Joints
Dec 14, 2023
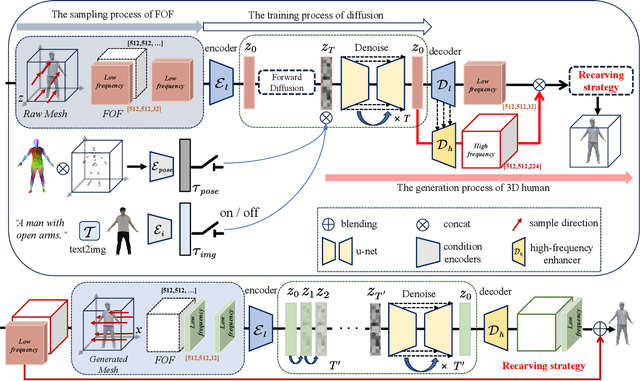

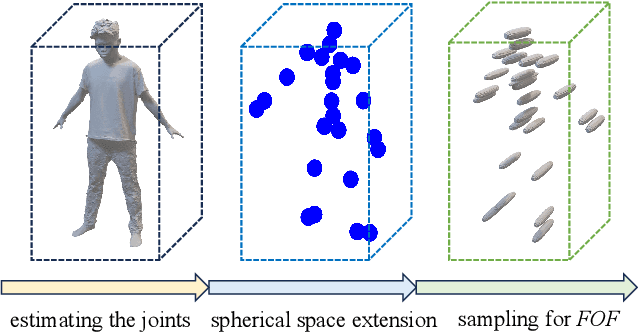
3D human generation is increasingly significant in various applications. However, the direct use of 2D generative methods in 3D generation often results in significant loss of local details, while methods that reconstruct geometry from generated images struggle with global view consistency. In this work, we introduce Joint2Human, a novel method that leverages 2D diffusion models to generate detailed 3D human geometry directly, ensuring both global structure and local details. To achieve this, we employ the Fourier occupancy field (FOF) representation, enabling the direct production of 3D shapes as preliminary results using 2D generative models. With the proposed high-frequency enhancer and the multi-view recarving strategy, our method can seamlessly integrate the details from different views into a uniform global shape.To better utilize the 3D human prior and enhance control over the generated geometry, we introduce a compact spherical embedding of 3D joints. This allows for effective application of pose guidance during the generation process. Additionally, our method is capable of generating 3D humans guided by textual inputs. Our experimental results demonstrate the capability of our method to ensure global structure, local details, high resolution, and low computational cost, simultaneously. More results and code can be found on our project page at http://cic.tju.edu.cn/faculty/likun/projects/Joint2Human.
R2Human: Real-Time 3D Human Appearance Rendering from a Single Image
Dec 10, 2023Reconstructing 3D human appearance from a single image is crucial for achieving holographic communication and immersive social experiences. However, this remains a challenge for existing methods, which typically rely on multi-camera setups or are limited to offline operations. In this paper, we propose R$^2$Human, the first approach for real-time inference and rendering of photorealistic 3D human appearance from a single image. The core of our approach is to combine the strengths of implicit texture fields and explicit neural rendering with our novel representation, namely Z-map. Based on this, we present an end-to-end network that performs high-fidelity color reconstruction of visible areas and provides reliable color inference for occluded regions. To further enhance the 3D perception ability of our network, we leverage the Fourier occupancy field to reconstruct a detailed 3D geometry, which serves as a prior for the texture field generation and provides a sampling surface in the rendering stage. Experiments show that our end-to-end method achieves state-of-the-art performance on both synthetic data and challenging real-world images and even outperforms many offline methods. The project page is available for research purposes at http://cic.tju.edu.cn/faculty/likun/projects/R2Human.
HumanCoser: Layered 3D Human Generation via Semantic-Aware Diffusion Model
Dec 10, 2023The generation of 3D clothed humans has attracted increasing attention in recent years. However, existing work cannot generate layered high-quality 3D humans with consistent body structures. As a result, these methods are unable to arbitrarily and separately change and edit the body and clothing of the human. In this paper, we propose a text-driven layered 3D human generation framework based on a novel physically-decoupled semantic-aware diffusion model. To keep the generated clothing consistent with the target text, we propose a semantic-confidence strategy for clothing that can eliminate the non-clothing content generated by the model. To match the clothing with different body shapes, we propose a SMPL-driven implicit field deformation network that enables the free transfer and reuse of clothing. Besides, we introduce uniform shape priors based on the SMPL model for body and clothing, respectively, which generates more diverse 3D content without being constrained by specific templates. The experimental results demonstrate that the proposed method not only generates 3D humans with consistent body structures but also allows free editing in a layered manner. The source code will be made public.
FOF: Learning Fourier Occupancy Field for Monocular Real-time Human Reconstruction
Jun 05, 2022

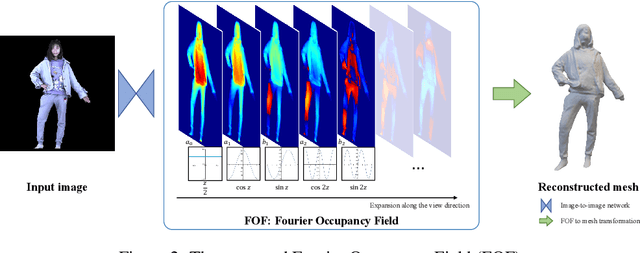

The advent of deep learning has led to significant progress in monocular human reconstruction. However, existing representations, such as parametric models, voxel grids, meshes and implicit neural representations, have difficulties achieving high-quality results and real-time speed at the same time. In this paper, we propose Fourier Occupancy Field (FOF), a novel powerful, efficient and flexible 3D representation, for monocular real-time and accurate human reconstruction. The FOF represents a 3D object with a 2D field orthogonal to the view direction where at each 2D position the occupancy field of the object along the view direction is compactly represented with the first few terms of Fourier series, which retains the topology and neighborhood relation in the 2D domain. A FOF can be stored as a multi-channel image, which is compatible with 2D convolutional neural networks and can bridge the gap between 3D geometries and 2D images. The FOF is very flexible and extensible, e.g., parametric models can be easily integrated into a FOF as a prior to generate more robust results. Based on FOF, we design the first 30+FPS high-fidelity real-time monocular human reconstruction framework. We demonstrate the potential of FOF on both public dataset and real captured data. The code will be released for research purposes.