 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPSNet: End-to-End Human Pose and Shape Estimation with Lensless Imaging
Apr 08, 2024
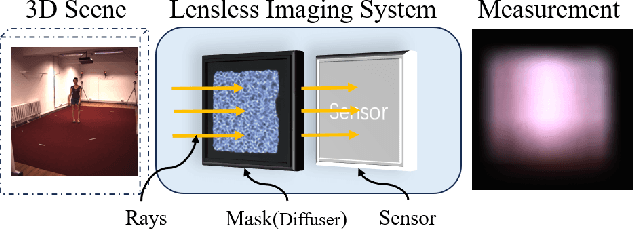
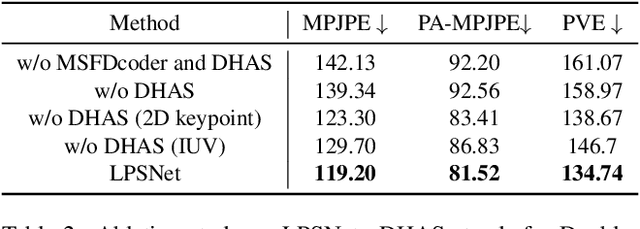
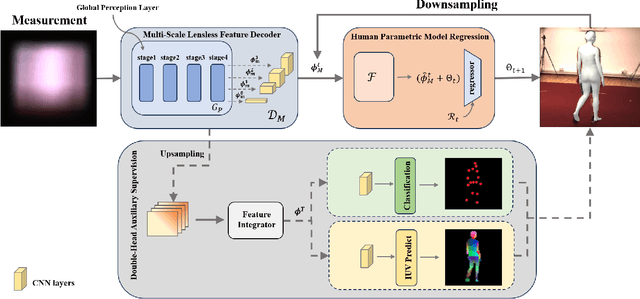
Human pose and shape (HPS) estimation with lensless imaging is not only beneficial to privacy protection but also can be used in covert surveillance scenarios due to the small size and simple structure of this device. However, this task presents significant challenges due to the inherent ambiguity of the captured measurements and lacks effective methods for directly estimating human pose and shape from lensless data. In this paper, we propose the first end-to-end framework to recover 3D human poses and shapes from lensless measurements to our knowledge. We specifically design a multi-scale lensless feature decoder to decode the lensless measurements through the optically encoded mask for efficient feature extraction. We also propose a double-head auxiliary supervision mechanism to improve the estimation accuracy of human limb ends. Besides, we establish a lensless imaging system and verify the effectiveness of our method on various datasets acquired by our lensless imaging system.
MARIS: Referring Image Segmentation via Mutual-Aware Attention Features
Nov 27, 2023
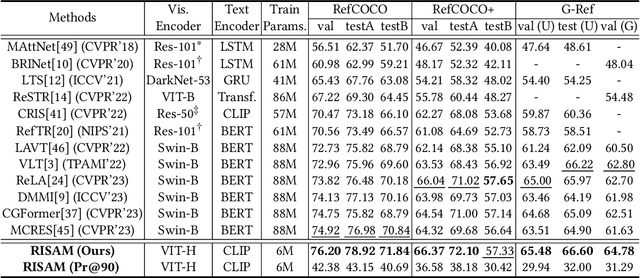

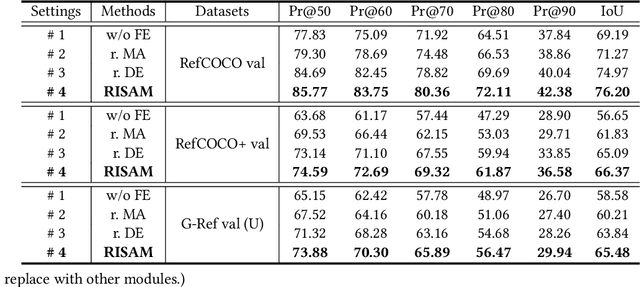
Referring image segmentation (RIS) aims to segment a particular region based on a language expression prompt. Existing methods incorporate linguistic features into visual features and obtain multi-modal features for mask decoding. However, these methods may segment the visually salient entity instead of the correct referring region, as the multi-modal features are dominated by the abundant visual context. In this paper, we propose MARIS, a referring image segmentation method that leverages the Segment Anything Model (SAM) and introduces a mutual-aware attention mechanism to enhance the cross-modal fusion via two parallel branches. Specifically, our mutual-aware attention mechanism consists of Vision-Guided Attention and Language-Guided Attention, which bidirectionally model the relationship between visual and linguistic features. Correspondingly, we design a Mask Decoder to enable explicit linguistic guidance for more consistent segmentation with the language expression. To this end, a multi-modal query token is proposed to integrate linguistic information and interact with visual information simultaneously. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art RIS methods. Our code will be publicly available.