 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPSNet: End-to-End Human Pose and Shape Estimation with Lensless Imaging
Apr 08, 2024
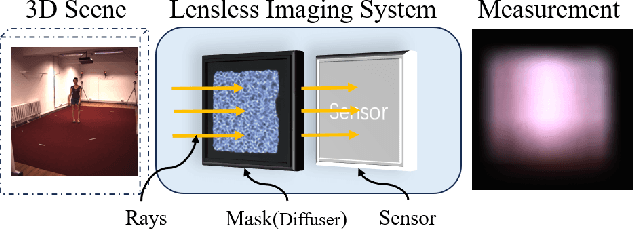
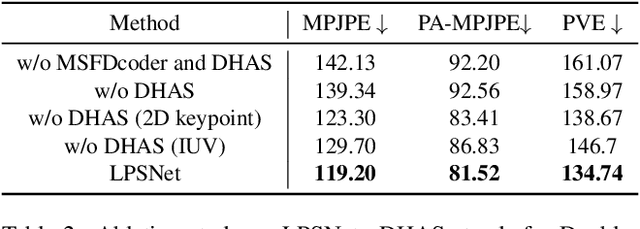
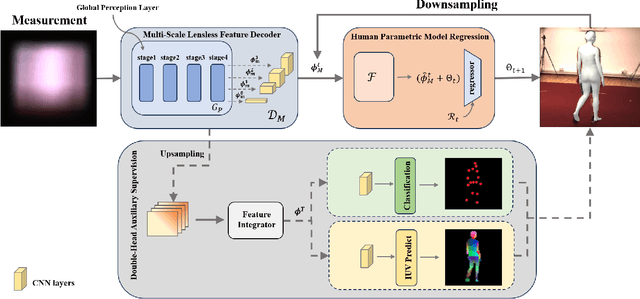
Human pose and shape (HPS) estimation with lensless imaging is not only beneficial to privacy protection but also can be used in covert surveillance scenarios due to the small size and simple structure of this device. However, this task presents significant challenges due to the inherent ambiguity of the captured measurements and lacks effective methods for directly estimating human pose and shape from lensless data. In this paper, we propose the first end-to-end framework to recover 3D human poses and shapes from lensless measurements to our knowledge. We specifically design a multi-scale lensless feature decoder to decode the lensless measurements through the optically encoded mask for efficient feature extraction. We also propose a double-head auxiliary supervision mechanism to improve the estimation accuracy of human limb ends. Besides, we establish a lensless imaging system and verify the effectiveness of our method on various datasets acquired by our lensless imaging system.
High-Quality Animatable Dynamic Garment Reconstruction from Monocular Videos
Nov 02, 2023
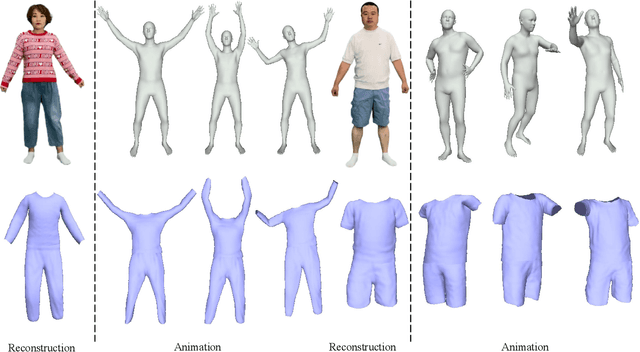


Much progress has been made in reconstructing garments from an image or a video. However, none of existing works meet the expectations of digitizing high-quality animatable dynamic garments that can be adjusted to various unseen poses. In this paper, we propose the first method to recover high-quality animatable dynamic garments from monocular videos without depending on scanned data. To generate reasonable deformations for various unseen poses, we propose a learnable garment deformation network that formulates the garment reconstruction task as a pose-driven deformation problem. To alleviate the ambiguity estimating 3D garments from monocular videos, we design a multi-hypothesis deformation module that learns spatial representations of multiple plausible deformations. Experimental results on several public datasets demonstrate that our method can reconstruct high-quality dynamic garments with coherent surface details, which can be easily animated under unseen poses. The code will be provided for research purposes.
Narrator: Towards Natural Control of Human-Scene Interaction Generation via Relationship Reasoning
Mar 16, 2023



Naturally controllable human-scene interaction (HSI) generation has an important role in various fields, such as VR/AR content creation and human-centered AI. However, existing methods are unnatural and unintuitive in their controllability, which heavily limits their application in practice. Therefore, we focus on a challenging task of naturally and controllably generating realistic and diverse HSIs from textual descriptions. From human cognition, the ideal generative model should correctly reason about spatial relationships and interactive actions. To that end, we propose Narrator, a novel relationship reasoning-based generative approach using a conditional variation autoencoder for naturally controllable generation given a 3D scene and a textual description. Also, we model global and local spatial relationships in a 3D scene and a textual description respectively based on the scene graph, and introduce a partlevel action mechanism to represent interactions as atomic body part states. In particular, benefiting from our relationship reasoning, we further propose a simple yet effective multi-human generation strategy, which is the first exploration for controllable multi-human scene interaction generation. Our extensive experiments and perceptual studies show that Narrator can controllably generate diverse interactions and significantly outperform existing works. The code and dataset will be available for research purposes.