 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Quality Animatable Dynamic Garment Reconstruction from Monocular Videos
Paper and Code
Nov 02, 2023
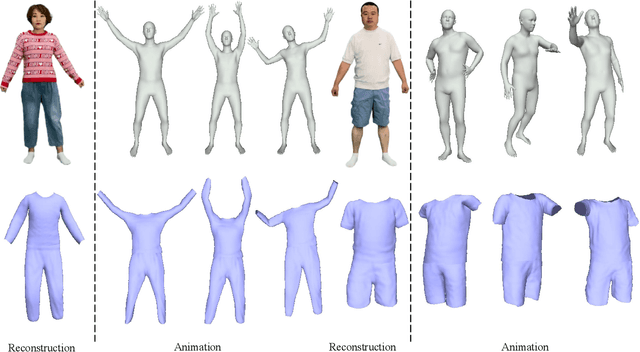


Much progress has been made in reconstructing garments from an image or a video. However, none of existing works meet the expectations of digitizing high-quality animatable dynamic garments that can be adjusted to various unseen poses. In this paper, we propose the first method to recover high-quality animatable dynamic garments from monocular videos without depending on scanned data. To generate reasonable deformations for various unseen poses, we propose a learnable garment deformation network that formulates the garment reconstruction task as a pose-driven deformation problem. To alleviate the ambiguity estimating 3D garments from monocular videos, we design a multi-hypothesis deformation module that learns spatial representations of multiple plausible deformations. Experimental results on several public datasets demonstrate that our method can reconstruct high-quality dynamic garments with coherent surface details, which can be easily animated under unseen poses. The code will be provided for research purposes.