 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Shuffling Video Benefit Temporal Bias Problem: A Novel Training Framework for Temporal Grounding
Paper and Code

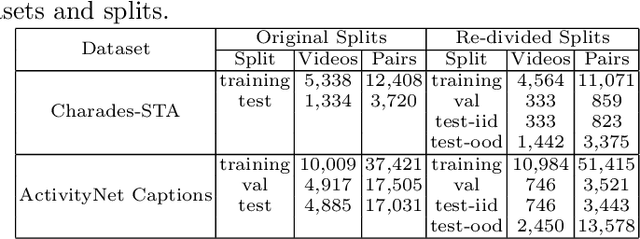
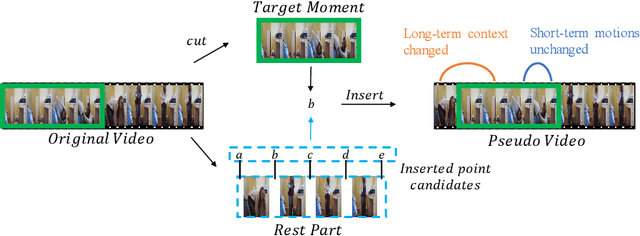
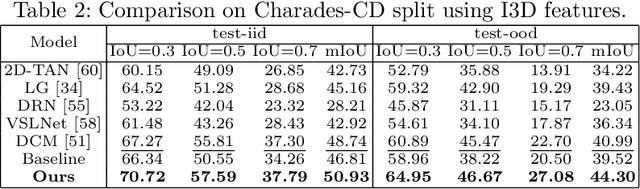
Temporal grounding aims to locate a target video moment that semantically corresponds to the given sentence query in an untrimmed video. However, recent works find that existing methods suffer a severe temporal bias problem. These methods do not reason the target moment locations based on the visual-textual semantic alignment but over-rely on the temporal biases of queries in training sets. To this end, this paper proposes a novel training framework for grounding models to use shuffled videos to address temporal bias problem without losing grounding accuracy. Our framework introduces two auxiliary tasks, cross-modal matching and temporal order discrimination, to promote the grounding model training. The cross-modal matching task leverages the content consistency between shuffled and original videos to force the grounding model to mine visual contents to semantically match queries. The temporal order discrimination task leverages the difference in temporal order to strengthen the understanding of long-term temporal contexts. Extensive experiments on Charades-STA and ActivityNet Captions demonstrate the effectiveness of our method for mitigating the reliance on temporal biases and strengthening the model's generalization ability against the different temporal distributions. Code is available at https://github.com/haojc/ShufflingVideosForTSG.