 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMHI: A Multimodal Egocentric Human Motion Dataset with HMD and Body-Worn IMUs
Aug 30, 2024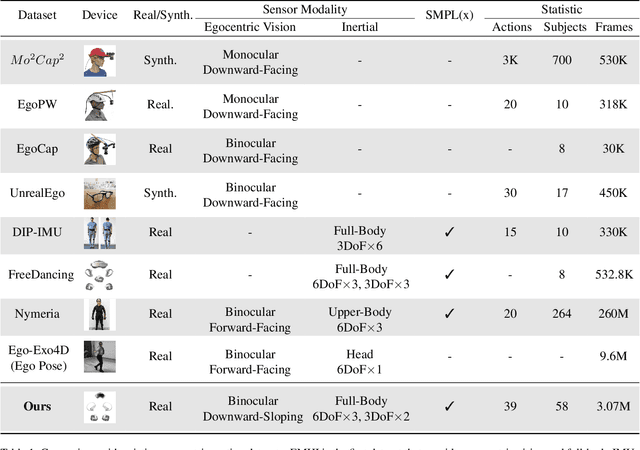
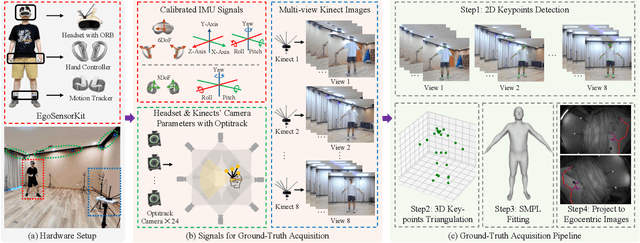
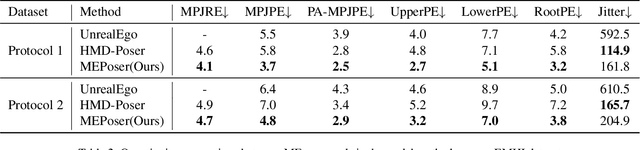
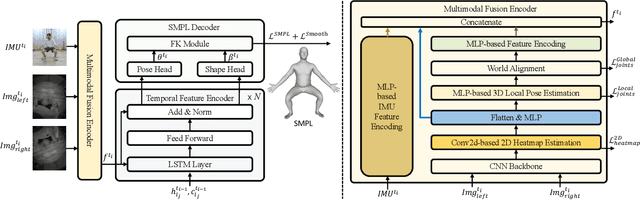
Egocentric human pose estimation (HPE) using wearable sensors is essential for VR/AR applications. Most methods rely solely on either egocentric-view images or sparse Inertial Measurement Unit (IMU) signals, leading to inaccuracies due to self-occlusion in images or the sparseness and drift of inertial sensors. Most importantly, the lack of real-world datasets containing both modalities is a major obstacle to progress in this field. To overcome the barrier, we propose EMHI, a multimodal \textbf{E}gocentric human \textbf{M}otion dataset with \textbf{H}ead-Mounted Display (HMD) and body-worn \textbf{I}MUs, with all data collected under the real VR product suite. Specifically, EMHI provides synchronized stereo images from downward-sloping cameras on the headset and IMU data from body-worn sensors, along with pose annotations in SMPL format. This dataset consists of 885 sequences captured by 58 subjects performing 39 actions, totaling about 28.5 hours of recording. We evaluate the annotations by comparing them with optical marker-based SMPL fitting results. To substantiate the reliability of our dataset, we introduce MEPoser, a new baseline method for multimodal egocentric HPE, which employs a multimodal fusion encoder, temporal feature encoder, and MLP-based regression heads. The experiments on EMHI show that MEPoser outperforms existing single-modal methods and demonstrates the value of our dataset in solving the problem of egocentric HPE. We believe the release of EMHI and the method could advance the research of egocentric HPE and expedite the practical implementation of this technology in VR/AR products.
HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations
Mar 06, 2024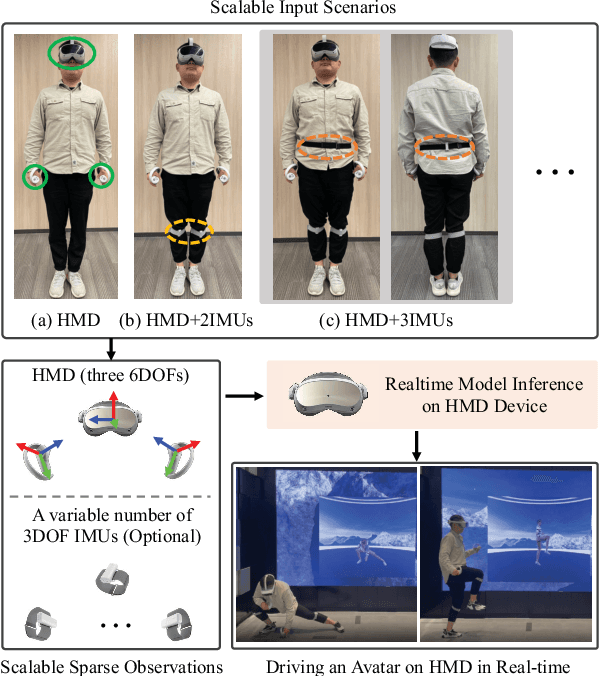
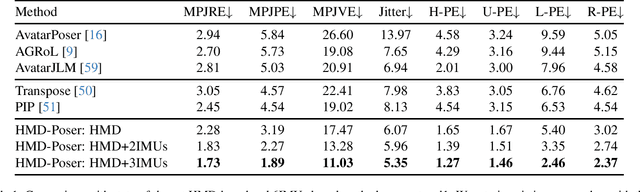
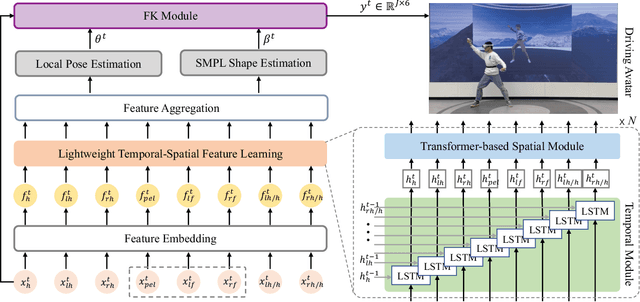
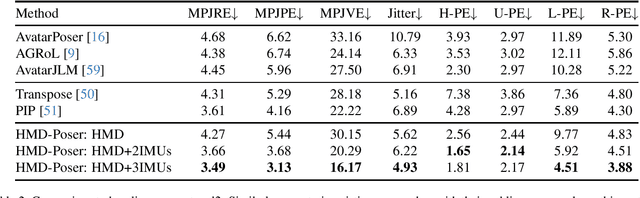
It is especially challenging to achieve real-time human motion tracking on a standalone VR Head-Mounted Display (HMD) such as Meta Quest and PICO. In this paper, we propose HMD-Poser, the first unified approach to recover full-body motions using scalable sparse observations from HMD and body-worn IMUs. In particular, it can support a variety of input scenarios, such as HMD, HMD+2IMUs, HMD+3IMUs, etc. The scalability of inputs may accommodate users' choices for both high tracking accuracy and easy-to-wear. A lightweight temporal-spatial feature learning network is proposed in HMD-Poser to guarantee that the model runs in real-time on HMDs. Furthermore, HMD-Poser presents online body shape estimation to improve the position accuracy of body joints. Extensive experimental results on the challenging AMASS dataset show that HMD-Poser achieves new state-of-the-art results in both accuracy and real-time performance. We also build a new free-dancing motion dataset to evaluate HMD-Poser's on-device performance and investigate the performance gap between synthetic data and real-captured sensor data. Finally, we demonstrate our HMD-Poser with a real-time Avatar-driving application on a commercial HMD. Our code and free-dancing motion dataset are available https://pico-ai-team.github.io/hmd-poser
Optimization of a Real-Time Wavelet-Based Algorithm for Improving Speech Intelligibility
Feb 05, 2022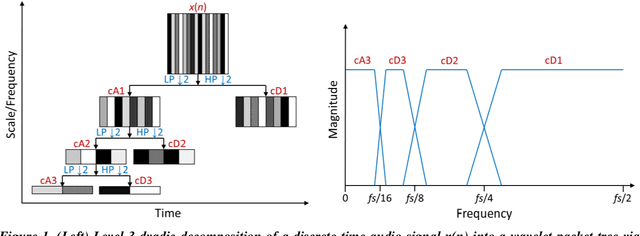
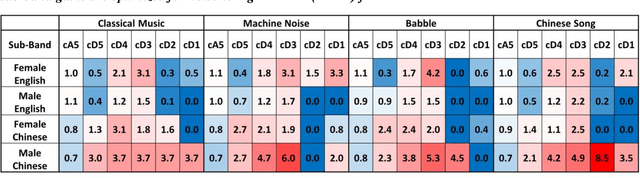

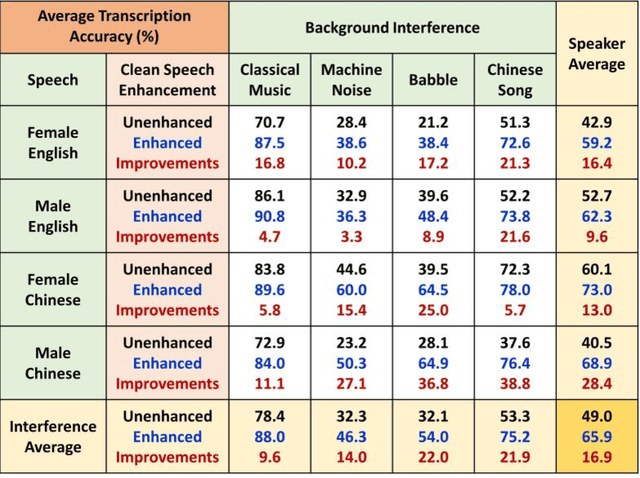
The optimization of a wavelet-based algorithm to improve speech intelligibility is reported. The discrete-time speech signal is split into frequency sub-bands via a multi-level discrete wavelet transform. Various gains are applied to the sub-band signals before they are recombined to form a modified version of the speech. The sub-band gains are adjusted while keeping the overall signal energy unchanged, and the speech intelligibility under various background interference and simulated hearing loss conditions is enhanced and evaluated objectively and quantitatively using Google Speech-to-Text transcription. For English and Chinese noise-free speech, overall intelligibility is improved, and the transcription accuracy can be increased by as much as 80 percentage points by reallocating the spectral energy toward the mid-frequency sub-bands, effectively increasing the consonant-vowel intensity ratio. This is reasonable since the consonants are relatively weak and of short duration, which are therefore the most likely to become indistinguishable in the presence of background noise or high-frequency hearing impairment. For speech already corrupted by noise, improving intelligibility is challenging but still realizable. The proposed algorithm is implementable for real-time signal processing and comparatively simpler than previous algorithms. Potential applications include speech enhancement, hearing aids, machine listening, and a better understanding of speech intelligibility.