 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Physical AI in Vision: A Survey
Jan 19, 2025



Generative Artificial Intelligence (AI) has rapidly advanced the field of computer vision by enabling machines to create and interpret visual data with unprecedented sophistication. This transformation builds upon a foundation of generative models to produce realistic images, videos, and 3D or 4D content. Traditionally, generative models primarily focus on visual fidelity while often neglecting the physical plausibility of generated content. This gap limits their effectiveness in applications requiring adherence to real-world physical laws, such as robotics, autonomous systems, and scientific simulations. As generative AI evolves to increasingly integrate physical realism and dynamic simulation, its potential to function as a "world simulator" expands-enabling the modeling of interactions governed by physics and bridging the divide between virtual and physical realities. This survey systematically reviews this emerging field of physics-aware generative AI in computer vision, categorizing methods based on how they incorporate physical knowledge-either through explicit simulation or implicit learning. We analyze key paradigms, discuss evaluation protocols, and identify future research directions. By offering a comprehensive overview, this survey aims to help future developments in physically grounded generation for vision. The reviewed papers are summarized at https://github.com/BestJunYu/Awesome-Physics-aware-Generation.
Compress Guidance in Conditional Diffusion Sampling
Aug 20, 2024Enforcing guidance throughout the entire sampling process often proves counterproductive due to the model-fitting issue., where samples are generated to match the classifier's parameters rather than generalizing the expected condition. This work identifies and quantifies the problem, demonstrating that reducing or excluding guidance at numerous timesteps can mitigate this issue. By distributing the guidance densely in the early stages of the process, we observe a significant improvement in image quality and diversity while also reducing the required guidance timesteps by nearly 40%. This approach addresses a major challenge in applying guidance effectively to generative tasks. Consequently, our proposed method, termed Compress Guidance, allows for the exclusion of a substantial number of guidance timesteps while still surpassing baseline models in image quality. We validate our approach through benchmarks on label conditional and text-to-image generative tasks across various datasets and models.
Boosting Diffusion Models with an Adaptive Momentum Sampler
Aug 23, 2023



Diffusion probabilistic models (DPMs) have been shown to generate high-quality images without the need for delicate adversarial training. However, the current sampling process in DPMs is prone to violent shaking. In this paper, we present a novel reverse sampler for DPMs inspired by the widely-used Adam optimizer. Our proposed sampler can be readily applied to a pre-trained diffusion model, utilizing momentum mechanisms and adaptive updating to smooth the reverse sampling process and ensure stable generation, resulting in outputs of enhanced quality. By implicitly reusing update directions from early steps, our proposed sampler achieves a better balance between high-level semantics and low-level details. Additionally, this sampler is flexible and can be easily integrated into pre-trained DPMs regardless of the sampler used during training. Our experimental results on multiple benchmarks demonstrate that our proposed reverse sampler yields remarkable improvements over different baselines. We will make the source code available.
Optimization of a Real-Time Wavelet-Based Algorithm for Improving Speech Intelligibility
Feb 05, 2022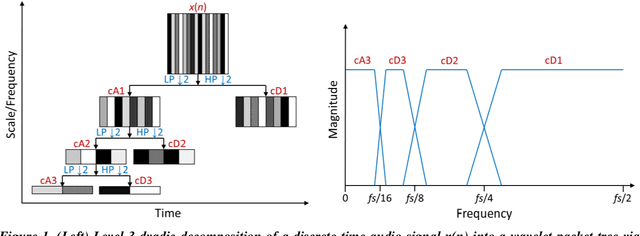
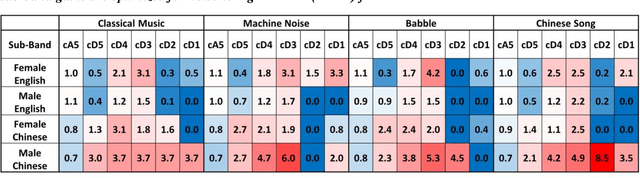

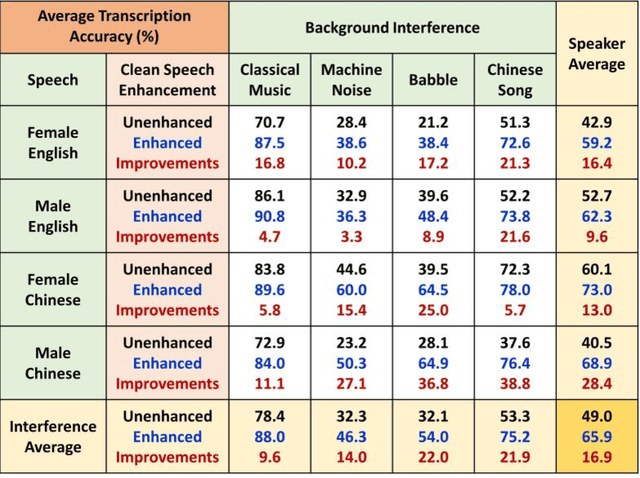
The optimization of a wavelet-based algorithm to improve speech intelligibility is reported. The discrete-time speech signal is split into frequency sub-bands via a multi-level discrete wavelet transform. Various gains are applied to the sub-band signals before they are recombined to form a modified version of the speech. The sub-band gains are adjusted while keeping the overall signal energy unchanged, and the speech intelligibility under various background interference and simulated hearing loss conditions is enhanced and evaluated objectively and quantitatively using Google Speech-to-Text transcription. For English and Chinese noise-free speech, overall intelligibility is improved, and the transcription accuracy can be increased by as much as 80 percentage points by reallocating the spectral energy toward the mid-frequency sub-bands, effectively increasing the consonant-vowel intensity ratio. This is reasonable since the consonants are relatively weak and of short duration, which are therefore the most likely to become indistinguishable in the presence of background noise or high-frequency hearing impairment. For speech already corrupted by noise, improving intelligibility is challenging but still realizable. The proposed algorithm is implementable for real-time signal processing and comparatively simpler than previous algorithms. Potential applications include speech enhancement, hearing aids, machine listening, and a better understanding of speech intelligibility.