 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention
Feb 05, 2026While humans perceive the world through diverse modalities that operate synergistically to support a holistic understanding of their surroundings, existing omnivideo models still face substantial challenges on audio-visual understanding tasks. In this paper, we propose OmniVideo-R1, a novel reinforced framework that improves mixed-modality reasoning. OmniVideo-R1 empowers models to "think with omnimodal cues" by two key strategies: (1) query-intensive grounding based on self-supervised learning paradigms; and (2) modality-attentive fusion built upon contrastive learning paradigms. Extensive experiments on multiple benchmarks demonstrate that OmniVideo-R1 consistently outperforms strong baselines, highlighting its effectiveness and robust generalization capabilities.
Unveiling Implicit Advantage Symmetry: Why GRPO Struggles with Exploration and Difficulty Adaptation
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR), particularly GRPO, has become the standard for eliciting LLM reasoning. However, its efficiency in exploration and difficulty adaptation remains an open challenge. In this work, we argue that these bottlenecks stem from an implicit advantage symmetry inherent in Group Relative Advantage Estimation (GRAE). This symmetry induces two critical limitations: (i) at the group level, strict symmetry in weights between correct and incorrect trajectories leaves unsampled action logits unchanged, thereby hindering exploration of novel correct solution. (ii) at the sample level, the algorithm implicitly prioritizes medium-difficulty samples, remaining agnostic to the non-stationary demands of difficulty focus. Through controlled experiments, we reveal that this symmetric property is sub-optimal, yielding two pivotal insights: (i) asymmetrically suppressing the advantages of correct trajectories encourages essential exploration. (ii) learning efficiency is maximized by a curriculum-like transition-prioritizing simpler samples initially before gradually shifting to complex ones. Motivated by these findings, we propose Asymmetric GRAE (A-GRAE), which dynamically modulates exploration incentives and sample-difficulty focus. Experiments across seven benchmarks demonstrate that A-GRAE consistently improves GRPO and its variants across both LLMs and MLLMs.
Dual Latent Memory for Visual Multi-agent System
Jan 31, 2026While Visual Multi-Agent Systems (VMAS) promise to enhance comprehensive abilities through inter-agent collaboration, empirical evidence reveals a counter-intuitive "scaling wall": increasing agent turns often degrades performance while exponentially inflating token costs. We attribute this failure to the information bottleneck inherent in text-centric communication, where converting perceptual and thinking trajectories into discrete natural language inevitably induces semantic loss. To this end, we propose L$^{2}$-VMAS, a novel model-agnostic framework that enables inter-agent collaboration with dual latent memories. Furthermore, we decouple the perception and thinking while dynamically synthesizing dual latent memories. Additionally, we introduce an entropy-driven proactive triggering that replaces passive information transmission with efficient, on-demand memory access. Extensive experiments among backbones, sizes, and multi-agent structures demonstrate that our method effectively breaks the "scaling wall" with superb scalability, improving average accuracy by 2.7-5.4% while reducing token usage by 21.3-44.8%. Codes: https://github.com/YU-deep/L2-VMAS.
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
Topology-Agnostic Animal Motion Generation from Text Prompt
Dec 11, 2025Motion generation is fundamental to computer animation and widely used across entertainment, robotics, and virtual environments. While recent methods achieve impressive results, most rely on fixed skeletal templates, which prevent them from generalizing to skeletons with different or perturbed topologies. We address the core limitation of current motion generation methods - the combined lack of large-scale heterogeneous animal motion data and unified generative frameworks capable of jointly modeling arbitrary skeletal topologies and textual conditions. To this end, we introduce OmniZoo, a large-scale animal motion dataset spanning 140 species and 32,979 sequences, enriched with multimodal annotations. Building on OmniZoo, we propose a generalized autoregressive motion generation framework capable of producing text-driven motions for arbitrary skeletal topologies. Central to our model is a Topology-aware Skeleton Embedding Module that encodes geometric and structural properties of any skeleton into a shared token space, enabling seamless fusion with textual semantics. Given a text prompt and a target skeleton, our method generates temporally coherent, physically plausible, and semantically aligned motions, and further enables cross-species motion style transfer.
VisMem: Latent Vision Memory Unlocks Potential of Vision-Language Models
Nov 14, 2025Despite the remarkable success of Vision-Language Models (VLMs), their performance on a range of complex visual tasks is often hindered by a "visual processing bottleneck": a propensity to lose grounding in visual evidence and exhibit a deficit in contextualized visual experience during prolonged generation. Drawing inspiration from human cognitive memory theory, which distinguishes short-term visually-dominant memory and long-term semantically-dominant memory, we propose VisMem, a cognitively-aligned framework that equips VLMs with dynamic latent vision memories, a short-term module for fine-grained perceptual retention and a long-term module for abstract semantic consolidation. These memories are seamlessly invoked during inference, allowing VLMs to maintain both perceptual fidelity and semantic consistency across thinking and generation. Extensive experiments across diverse visual benchmarks for understanding, reasoning, and generation reveal that VisMem delivers a significant average performance boost of 11.8% relative to the vanilla model and outperforms all counterparts, establishing a new paradigm for latent-space memory enhancement. The code will be available: https://github.com/YU-deep/VisMem.git.
SIFThinker: Spatially-Aware Image Focus for Visual Reasoning
Aug 08, 2025Current multimodal large language models (MLLMs) still face significant challenges in complex visual tasks (e.g., spatial understanding, fine-grained perception). Prior methods have tried to incorporate visual reasoning, however, they fail to leverage attention correction with spatial cues to iteratively refine their focus on prompt-relevant regions. In this paper, we introduce SIFThinker, a spatially-aware "think-with-images" framework that mimics human visual perception. Specifically, SIFThinker enables attention correcting and image region focusing by interleaving depth-enhanced bounding boxes and natural language. Our contributions are twofold: First, we introduce a reverse-expansion-forward-inference strategy that facilitates the generation of interleaved image-text chains of thought for process-level supervision, which in turn leads to the construction of the SIF-50K dataset. Besides, we propose GRPO-SIF, a reinforced training paradigm that integrates depth-informed visual grounding into a unified reasoning pipeline, teaching the model to dynamically correct and focus on prompt-relevant regions. Extensive experiments demonstrate that SIFThinker outperforms state-of-the-art methods in spatial understanding and fine-grained visual perception, while maintaining strong general capabilities, highlighting the effectiveness of our method.
NFR: Neural Feature-Guided Non-Rigid Shape Registration
May 28, 2025In this paper, we propose a novel learning-based framework for 3D shape registration, which overcomes the challenges of significant non-rigid deformation and partiality undergoing among input shapes, and, remarkably, requires no correspondence annotation during training. Our key insight is to incorporate neural features learned by deep learning-based shape matching networks into an iterative, geometric shape registration pipeline. The advantage of our approach is two-fold -- On one hand, neural features provide more accurate and semantically meaningful correspondence estimation than spatial features (e.g., coordinates), which is critical in the presence of large non-rigid deformations; On the other hand, the correspondences are dynamically updated according to the intermediate registrations and filtered by consistency prior, which prominently robustify the overall pipeline. Empirical results show that, with as few as dozens of training shapes of limited variability, our pipeline achieves state-of-the-art results on several benchmarks of non-rigid point cloud matching and partial shape matching across varying settings, but also delivers high-quality correspondences between unseen challenging shape pairs that undergo both significant extrinsic and intrinsic deformations, in which case neither traditional registration methods nor intrinsic methods work.
VisRL: Intention-Driven Visual Perception via Reinforced Reasoning
Mar 10, 2025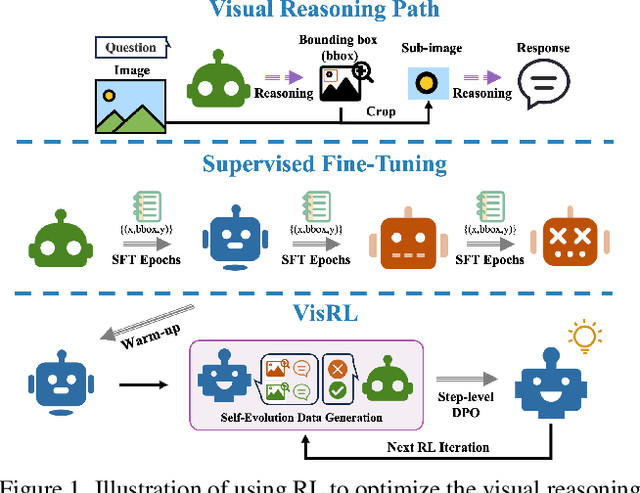



Visual understanding is inherently intention-driven - humans selectively focus on different regions of a scene based on their goals. Recent advances in large multimodal models (LMMs) enable flexible expression of such intentions through natural language, allowing queries to guide visual reasoning processes. Frameworks like Visual Chain-of-Thought have demonstrated the benefit of incorporating explicit reasoning steps, where the model predicts a focus region before answering a query. However, existing approaches rely heavily on supervised training with annotated intermediate bounding boxes, which severely limits scalability due to the combinatorial explosion of intention-region pairs. To overcome this limitation, we propose VisRL, the first framework that applies reinforcement learning (RL) to the problem of intention-driven visual perception. VisRL optimizes the entire visual reasoning process using only reward signals. By treating intermediate focus selection as a internal decision optimized through trial-and-error, our method eliminates the need for costly region annotations while aligning more closely with how humans learn to perceive the world. Extensive experiments across multiple benchmarks show that VisRL consistently outperforms strong baselines, demonstrating both its effectiveness and its strong generalization across different LMMs. Our code is available at this [URL](https://github.com/zhangquanchen/VisRL).
Unsupervised Non-Rigid Point Cloud Matching through Large Vision Models
Aug 16, 2024



In this paper, we propose a novel learning-based framework for non-rigid point cloud matching, which can be trained purely on point clouds without any correspondence annotation but also be extended naturally to partial-to-full matching. Our key insight is to incorporate semantic features derived from large vision models (LVMs) to geometry-based shape feature learning. Our framework effectively leverages the structural information contained in the semantic features to address ambiguities arise from self-similarities among local geometries. Furthermore, our framework also enjoys the strong generalizability and robustness regarding partial observations of LVMs, leading to improvements in the regarding point cloud matching tasks. In order to achieve the above, we propose a pixel-to-point feature aggregation module, a local and global attention network as well as a geometrical similarity loss function. Experimental results show that our method achieves state-of-the-art results in matching non-rigid point clouds in both near-isometric and heterogeneous shape collection as well as more realistic partial and noisy data.