 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Stable Semi-Supervised Remote Sensing Segmentation via Co-Guidance and Co-Fusion
Dec 28, 2025Semi-supervised remote sensing (RS) image semantic segmentation offers a promising solution to alleviate the burden of exhaustive annotation, yet it fundamentally struggles with pseudo-label drift, a phenomenon where confirmation bias leads to the accumulation of errors during training. In this work, we propose Co2S, a stable semi-supervised RS segmentation framework that synergistically fuses priors from vision-language models and self-supervised models. Specifically, we construct a heterogeneous dual-student architecture comprising two distinct ViT-based vision foundation models initialized with pretrained CLIP and DINOv3 to mitigate error accumulation and pseudo-label drift. To effectively incorporate these distinct priors, an explicit-implicit semantic co-guidance mechanism is introduced that utilizes text embeddings and learnable queries to provide explicit and implicit class-level guidance, respectively, thereby jointly enhancing semantic consistency. Furthermore, a global-local feature collaborative fusion strategy is developed to effectively fuse the global contextual information captured by CLIP with the local details produced by DINOv3, enabling the model to generate highly precise segmentation results. Extensive experiments on six popular datasets demonstrate the superiority of the proposed method, which consistently achieves leading performance across various partition protocols and diverse scenarios. Project page is available at https://xavierjiezou.github.io/Co2S/.
GTR-Turbo: Merged Checkpoint is Secretly a Free Teacher for Agentic VLM Training
Dec 15, 2025Multi-turn reinforcement learning (RL) for multi-modal agents built upon vision-language models (VLMs) is hampered by sparse rewards and long-horizon credit assignment. Recent methods densify the reward by querying a teacher that provides step-level feedback, e.g., Guided Thought Reinforcement (GTR) and On-Policy Distillation, but rely on costly, often privileged models as the teacher, limiting practicality and reproducibility. We introduce GTR-Turbo, a highly efficient upgrade to GTR, which matches the performance without training or querying an expensive teacher model. Specifically, GTR-Turbo merges the weights of checkpoints produced during the ongoing RL training, and then uses this merged model as a "free" teacher to guide the subsequent RL via supervised fine-tuning or soft logit distillation. This design removes dependence on privileged VLMs (e.g., GPT or Gemini), mitigates the "entropy collapse" observed in prior work, and keeps training stable. Across diverse visual agentic tasks, GTR-Turbo improves the accuracy of the baseline model by 10-30% while reducing wall-clock training time by 50% and compute cost by 60% relative to GTR.
TaskSense: Cognitive Chain Modeling and Difficulty Estimation for GUI Tasks
Nov 12, 2025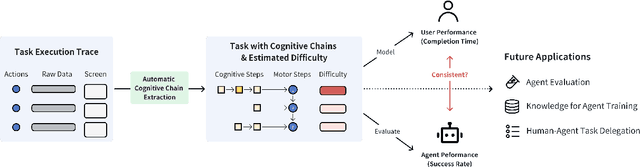
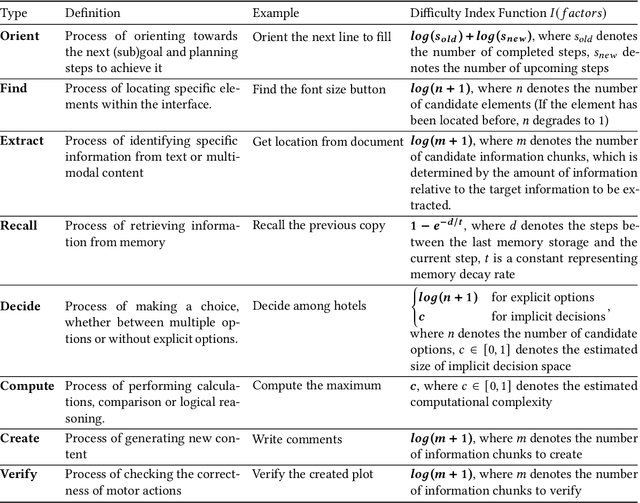
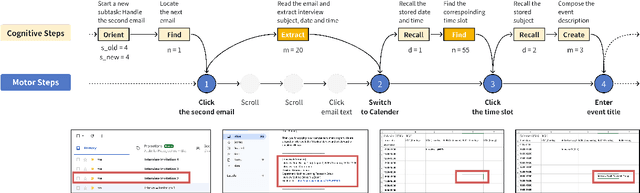

Measuring GUI task difficulty is crucial for user behavior analysis and agent capability evaluation. Yet, existing benchmarks typically quantify difficulty based on motor actions (e.g., step counts), overlooking the cognitive demands underlying task completion. In this work, we propose Cognitive Chain, a novel framework that models task difficulty from a cognitive perspective. A cognitive chain decomposes the cognitive processes preceding a motor action into a sequence of cognitive steps (e.g., finding, deciding, computing), each with a difficulty index grounded in information theories. We develop an LLM-based method to automatically extract cognitive chains from task execution traces. Validation with linear regression shows that our estimated cognitive difficulty correlates well with user completion time (step-level R-square=0.46 after annotation). Assessment of state-of-the-art GUI agents shows reduced success on cognitively demanding tasks, revealing capability gaps and Human-AI consistency patterns. We conclude by discussing potential applications in agent training, capability assessment, and human-agent delegation optimization.
ECVL-ROUTER: Scenario-Aware Routing for Vision-Language Models
Oct 31, 2025Vision-Language Models (VLMs) excel in diverse multimodal tasks. However, user requirements vary across scenarios, which can be categorized into fast response, high-quality output, and low energy consumption. Relying solely on large models deployed in the cloud for all queries often leads to high latency and energy cost, while small models deployed on edge devices are capable of handling simpler tasks with low latency and energy cost. To fully leverage the strengths of both large and small models, we propose ECVL-ROUTER, the first scenario-aware routing framework for VLMs. Our approach introduces a new routing strategy and evaluation metrics that dynamically select the appropriate model for each query based on user requirements, maximizing overall utility. We also construct a multimodal response-quality dataset tailored for router training and validate the approach through extensive experiments. Results show that our approach successfully routes over 80\% of queries to the small model while incurring less than 10\% drop in problem solving probability.
Hi-Agent: Hierarchical Vision-Language Agents for Mobile Device Control
Oct 16, 2025Building agents that autonomously operate mobile devices has attracted increasing attention. While Vision-Language Models (VLMs) show promise, most existing approaches rely on direct state-to-action mappings, which lack structured reasoning and planning, and thus generalize poorly to novel tasks or unseen UI layouts. We introduce Hi-Agent, a trainable hierarchical vision-language agent for mobile control, featuring a high-level reasoning model and a low-level action model that are jointly optimized. For efficient training, we reformulate multi-step decision-making as a sequence of single-step subgoals and propose a foresight advantage function, which leverages execution feedback from the low-level model to guide high-level optimization. This design alleviates the path explosion issue encountered by Group Relative Policy Optimization (GRPO) in long-horizon tasks and enables stable, critic-free joint training. Hi-Agent achieves a new State-Of-The-Art (SOTA) 87.9% task success rate on the Android-in-the-Wild (AitW) benchmark, significantly outperforming prior methods across three paradigms: prompt-based (AppAgent: 17.7%), supervised (Filtered BC: 54.5%), and reinforcement learning-based (DigiRL: 71.9%). It also demonstrates competitive zero-shot generalization on the ScreenSpot-v2 benchmark. On the more challenging AndroidWorld benchmark, Hi-Agent also scales effectively with larger backbones, showing strong adaptability in high-complexity mobile control scenarios.
Resolving Ambiguity in Gaze-Facilitated Visual Assistant Interaction Paradigm
Sep 26, 2025With the rise in popularity of smart glasses, users' attention has been integrated into Vision-Language Models (VLMs) to streamline multi-modal querying in daily scenarios. However, leveraging gaze data to model users' attention may introduce ambiguity challenges: (1) users' verbal questions become ambiguous by using pronouns or skipping context, (2) humans' gaze patterns can be noisy and exhibit complex spatiotemporal relationships with their spoken questions. Previous works only consider single image as visual modality input, failing to capture the dynamic nature of the user's attention. In this work, we introduce GLARIFY, a novel method to leverage spatiotemporal gaze information to enhance the model's effectiveness in real-world applications. Initially, we analyzed hundreds of querying samples with the gaze modality to demonstrate the noisy nature of users' gaze patterns. We then utilized GPT-4o to design an automatic data synthesis pipeline to generate the GLARIFY-Ambi dataset, which includes a dedicated chain-of-thought (CoT) process to handle noisy gaze patterns. Finally, we designed a heatmap module to incorporate gaze information into cutting-edge VLMs while preserving their pretrained knowledge. We evaluated GLARIFY using a hold-out test set. Experiments demonstrate that GLARIFY significantly outperforms baselines. By robustly aligning VLMs with human attention, GLARIFY paves the way for a usable and intuitive interaction paradigm with a visual assistant.
TextOnly: A Unified Function Portal for Text-Related Functions on Smartphones
Aug 23, 2025Text boxes serve as portals to diverse functionalities in today's smartphone applications. However, when it comes to specific functionalities, users always need to navigate through multiple steps to access particular text boxes for input. We propose TextOnly, a unified function portal that enables users to access text-related functions from various applications by simply inputting text into a sole text box. For instance, entering a restaurant name could trigger a Google Maps search, while a greeting could initiate a conversation in WhatsApp. Despite their brevity, TextOnly maximizes the utilization of these raw text inputs, which contain rich information, to interpret user intentions effectively. TextOnly integrates large language models(LLM) and a BERT model. The LLM consistently provides general knowledge, while the BERT model can continuously learn user-specific preferences and enable quicker predictions. Real-world user studies demonstrated TextOnly's effectiveness with a top-1 accuracy of 71.35%, and its ability to continuously improve both its accuracy and inference speed. Participants perceived TextOnly as having satisfactory usability and expressed a preference for TextOnly over manual executions. Compared with voice assistants, TextOnly supports a greater range of text-related functions and allows for more concise inputs.
Non-Contact Health Monitoring During Daily Personal Care Routines
Jun 11, 2025Remote photoplethysmography (rPPG) enables non-contact, continuous monitoring of physiological signals and offers a practical alternative to traditional health sensing methods. Although rPPG is promising for daily health monitoring, its application in long-term personal care scenarios, such as mirror-facing routines in high-altitude environments, remains challenging due to ambient lighting variations, frequent occlusions from hand movements, and dynamic facial postures. To address these challenges, we present LADH (Long-term Altitude Daily Health), the first long-term rPPG dataset containing 240 synchronized RGB and infrared (IR) facial videos from 21 participants across five common personal care scenarios, along with ground-truth PPG, respiration, and blood oxygen signals. Our experiments demonstrate that combining RGB and IR video inputs improves the accuracy and robustness of non-contact physiological monitoring, achieving a mean absolute error (MAE) of 4.99 BPM in heart rate estimation. Furthermore, we find that multi-task learning enhances performance across multiple physiological indicators simultaneously. Dataset and code are open at https://github.com/McJackTang/FusionVitals.
DeCoDe: Defer-and-Complement Decision-Making via Decoupled Concept Bottleneck Models
May 25, 2025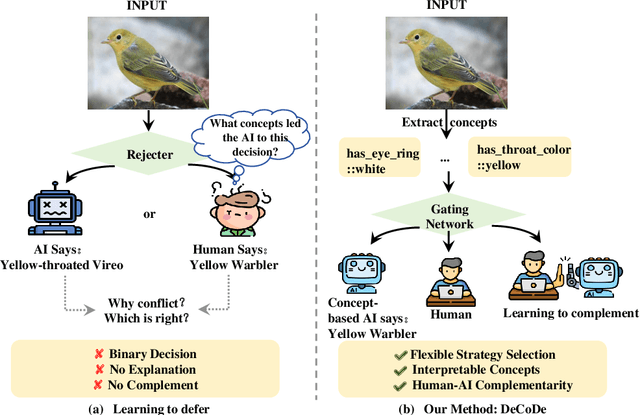
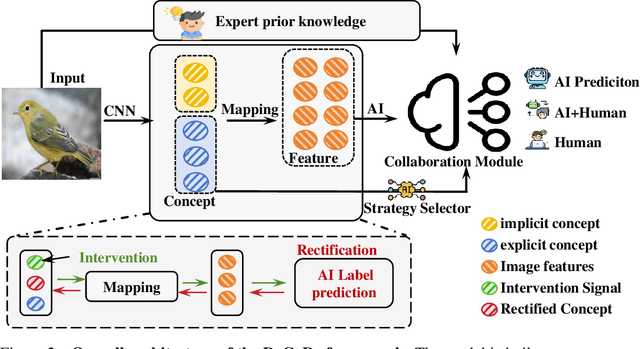
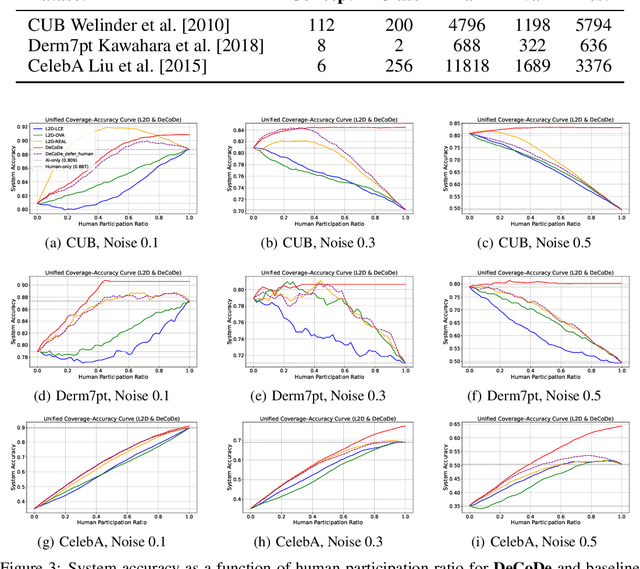

In human-AI collaboration, a central challenge is deciding whether the AI should handle a task, be deferred to a human expert, or be addressed through collaborative effort. Existing Learning to Defer approaches typically make binary choices between AI and humans, neglecting their complementary strengths. They also lack interpretability, a critical property in high-stakes scenarios where users must understand and, if necessary, correct the model's reasoning. To overcome these limitations, we propose Defer-and-Complement Decision-Making via Decoupled Concept Bottleneck Models (DeCoDe), a concept-driven framework for human-AI collaboration. DeCoDe makes strategy decisions based on human-interpretable concept representations, enhancing transparency throughout the decision process. It supports three flexible modes: autonomous AI prediction, deferral to humans, and human-AI collaborative complementarity, selected via a gating network that takes concept-level inputs and is trained using a novel surrogate loss that balances accuracy and human effort. This approach enables instance-specific, interpretable, and adaptive human-AI collaboration. Experiments on real-world datasets demonstrate that DeCoDe significantly outperforms AI-only, human-only, and traditional deferral baselines, while maintaining strong robustness and interpretability even under noisy expert annotations.
A Dataset and Toolkit for Multiparameter Cardiovascular Physiology Sensing on Rings
May 08, 2025



Smart rings offer a convenient way to continuously and unobtrusively monitor cardiovascular physiological signals. However, a gap remains between the ring hardware and reliable methods for estimating cardiovascular parameters, partly due to the lack of publicly available datasets and standardized analysis tools. In this work, we present $\tau$-Ring, the first open-source ring-based dataset designed for cardiovascular physiological sensing. The dataset comprises photoplethysmography signals (infrared and red channels) and 3-axis accelerometer data collected from two rings (reflective and transmissive optical paths), with 28.21 hours of raw data from 34 subjects across seven activities. $\tau$-Ring encompasses both stationary and motion scenarios, as well as stimulus-evoked abnormal physiological states, annotated with four ground-truth labels: heart rate, respiratory rate, oxygen saturation, and blood pressure. Using our proposed RingTool toolkit, we evaluated three widely-used physics-based methods and four cutting-edge deep learning approaches. Our results show superior performance compared to commercial rings, achieving best MAE values of 5.18 BPM for heart rate, 2.98 BPM for respiratory rate, 3.22\% for oxygen saturation, and 13.33/7.56 mmHg for systolic/diastolic blood pressure estimation. The open-sourced dataset and toolkit aim to foster further research and community-driven advances in ring-based cardiovascular health sensing.