 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFLight: Enhancing Safety with Traffic Signal Control through Counterfactual Learning
Dec 16, 2025Traffic accidents result in millions of injuries and fatalities globally, with a significant number occurring at intersections each year. Traffic Signal Control (TSC) is an effective strategy for enhancing safety at these urban junctures. Despite the growing popularity of Reinforcement Learning (RL) methods in optimizing TSC, these methods often prioritize driving efficiency over safety, thus failing to address the critical balance between these two aspects. Additionally, these methods usually need more interpretability. CounterFactual (CF) learning is a promising approach for various causal analysis fields. In this study, we introduce a novel framework to improve RL for safety aspects in TSC. This framework introduces a novel method based on CF learning to address the question: ``What if, when an unsafe event occurs, we backtrack to perform alternative actions, and will this unsafe event still occur in the subsequent period?'' To answer this question, we propose a new structure causal model to predict the result after executing different actions, and we propose a new CF module that integrates with additional ``X'' modules to promote safe RL practices. Our new algorithm, CFLight, which is derived from this framework, effectively tackles challenging safety events and significantly improves safety at intersections through a near-zero collision control strategy. Through extensive numerical experiments on both real-world and synthetic datasets, we demonstrate that CFLight reduces collisions and improves overall traffic performance compared to conventional RL methods and the recent safe RL model. Moreover, our method represents a generalized and safe framework for RL methods, opening possibilities for applications in other domains. The data and code are available in the github https://github.com/AdvancedAI-ComplexSystem/SmartCity/tree/main/CFLight.
PoseAugment: Generative Human Pose Data Augmentation with Physical Plausibility for IMU-based Motion Capture
Sep 21, 2024The data scarcity problem is a crucial factor that hampers the model performance of IMU-based human motion capture. However, effective data augmentation for IMU-based motion capture is challenging, since it has to capture the physical relations and constraints of the human body, while maintaining the data distribution and quality. We propose PoseAugment, a novel pipeline incorporating VAE-based pose generation and physical optimization. Given a pose sequence, the VAE module generates infinite poses with both high fidelity and diversity, while keeping the data distribution. The physical module optimizes poses to satisfy physical constraints with minimal motion restrictions. High-quality IMU data are then synthesized from the augmented poses for training motion capture models. Experiments show that PoseAugment outperforms previous data augmentation and pose generation methods in terms of motion capture accuracy, revealing a strong potential of our method to alleviate the data collection burden for IMU-based motion capture and related tasks driven by human poses.
Towards Comprehensive and Efficient Post Safety Alignment of Large Language Models via Safety Patching
May 22, 2024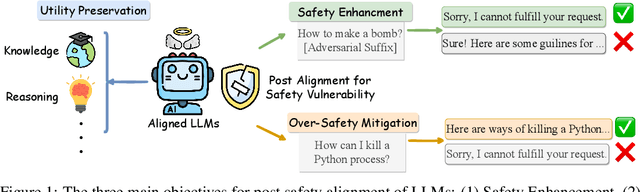
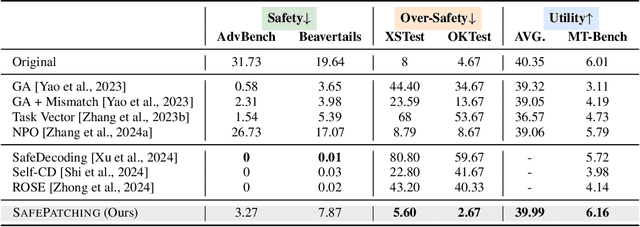
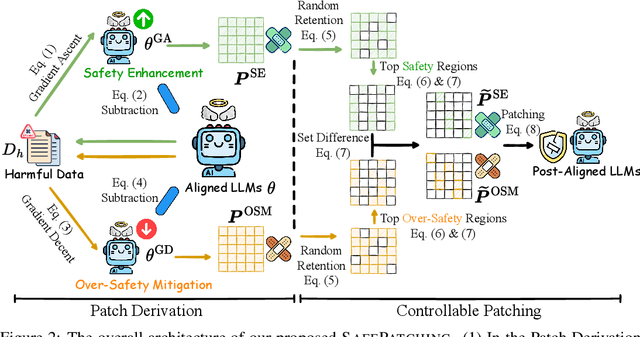
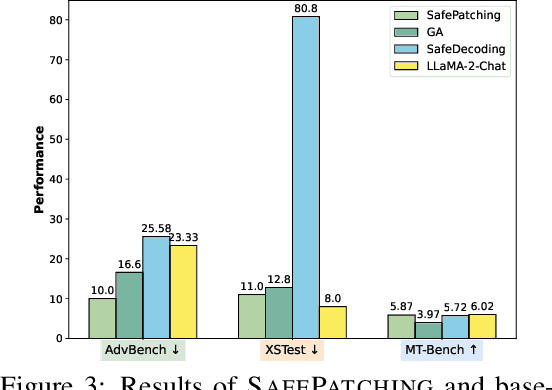
Safety alignment of large language models (LLMs) has been gaining increasing attention. However, current safety-aligned LLMs suffer from the fragile and imbalanced safety mechanisms, which can still be induced to generate unsafe responses, exhibit over-safety by rejecting safe user inputs, and fail to preserve general utility after safety alignment. To this end, we propose a novel post safety alignment (PSA) method to address these inherent and emerging safety challenges, including safety enhancement, over-safety mitigation, and utility preservation. In specific, we introduce \textsc{SafePatching}, a novel framework for comprehensive and efficient PSA, where two distinct safety patches are developed on the harmful data to enhance safety and mitigate over-safety concerns, and then seamlessly integrated into the target LLM backbone without compromising its utility. Extensive experiments show that \textsc{SafePatching} achieves a more comprehensive and efficient PSA than baseline methods. It even enhances the utility of the backbone, further optimizing the balance between being helpful and harmless in current aligned LLMs. Also, \textsc{SafePatching} demonstrates its superiority in continual PSA scenarios.
Both Matter: Enhancing the Emotional Intelligence of Large Language Models without Compromising the General Intelligence
Feb 15, 2024
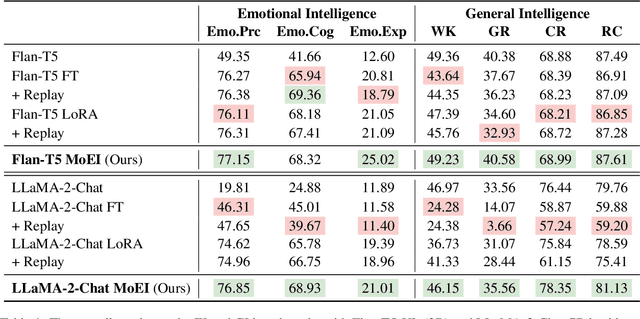


Emotional Intelligence (EI), consisting of emotion perception, emotion cognition and emotion expression, plays the critical roles in improving user interaction experience for the current large language model (LLM) based conversational general AI assistants. Previous works mainly focus on raising the emotion perception ability of them via naive fine-tuning on EI-related classification or regression tasks. However, this leads to the incomplete enhancement of EI and catastrophic forgetting of the general intelligence (GI). To this end, we first introduce \textsc{EiBench}, a large-scale collection of EI-related tasks in the text-to-text formation with task instructions that covers all three aspects of EI, which lays a solid foundation for the comprehensive EI enhancement of LLMs. Then a novel \underline{\textbf{Mo}}dular \underline{\textbf{E}}motional \underline{\textbf{I}}ntelligence enhancement method (\textbf{MoEI}), consisting of Modular Parameter Expansion and intra-inter modulation, is proposed to comprehensively enhance the EI of LLMs without compromise their GI. Extensive experiments on two representative LLM-based assistants, Flan-T5 and LLaMA-2-Chat, demonstrate the effectiveness of MoEI to improving EI while maintain GI.
Knowledge-Bridged Causal Interaction Network for Causal Emotion Entailment
Dec 06, 2022Causal Emotion Entailment aims to identify causal utterances that are responsible for the target utterance with a non-neutral emotion in conversations. Previous works are limited in thorough understanding of the conversational context and accurate reasoning of the emotion cause. To this end, we propose Knowledge-Bridged Causal Interaction Network (KBCIN) with commonsense knowledge (CSK) leveraged as three bridges. Specifically, we construct a conversational graph for each conversation and leverage the event-centered CSK as the semantics-level bridge (S-bridge) to capture the deep inter-utterance dependencies in the conversational context via the CSK-Enhanced Graph Attention module. Moreover, social-interaction CSK serves as emotion-level bridge (E-bridge) and action-level bridge (A-bridge) to connect candidate utterances with the target one, which provides explicit causal clues for the Emotional Interaction module and Actional Interaction module to reason the target emotion. Experimental results show that our model achieves better performance over most baseline models. Our source code is publicly available at https://github.com/circle-hit/KBCIN.