 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscending Language Boundaries: Harnessing LLMs for Low-Resource Language Translation
Paper and Code
Nov 18, 2024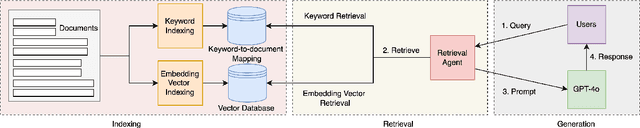
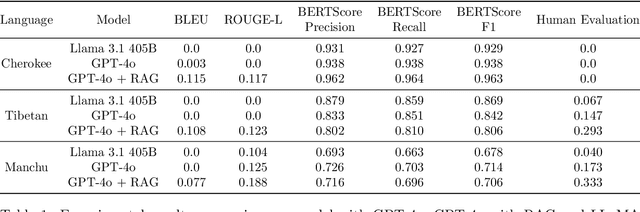


Large Language Models (LLMs) have demonstrated remarkable success across a wide range of tasks and domains. However, their performance in low-resource language translation, particularly when translating into these languages, remains underexplored. This gap poses significant challenges, as linguistic barriers hinder the cultural preservation and development of minority communities. To address this issue, this paper introduces a novel retrieval-based method that enhances translation quality for low-resource languages by focusing on key terms, which involves translating keywords and retrieving corresponding examples from existing data. To evaluate the effectiveness of this method, we conducted experiments translating from English into three low-resource languages: Cherokee, a critically endangered indigenous language of North America; Tibetan, a historically and culturally significant language in Asia; and Manchu, a language with few remaining speakers. Our comparison with the zero-shot performance of GPT-4o and LLaMA 3.1 405B, highlights the significant challenges these models face when translating into low-resource languages. In contrast, our retrieval-based method shows promise in improving both word-level accuracy and overall semantic understanding by leveraging existing resources more effectively.