 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinarized Convolutional Neural Networks with Separable Filters for Efficient Hardware Acceleration
Paper and Code
Jul 15, 2017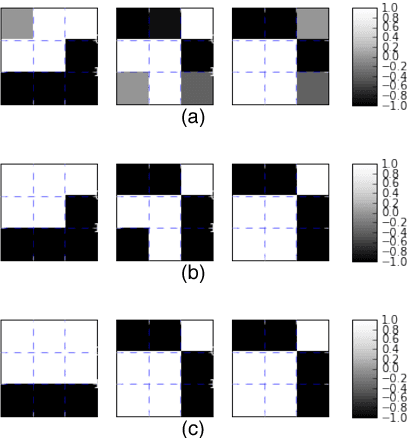
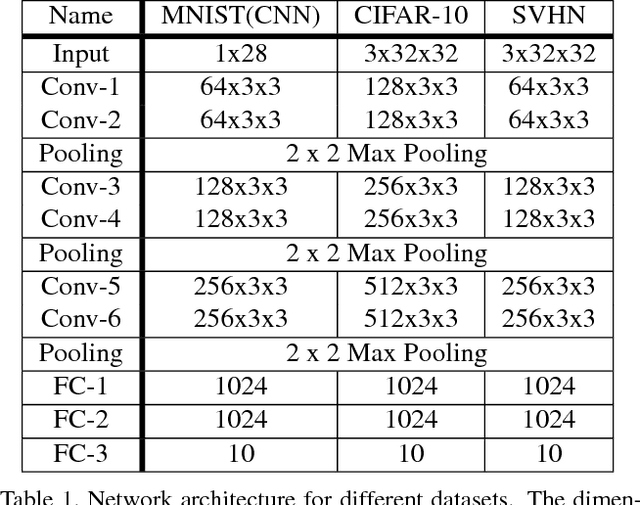
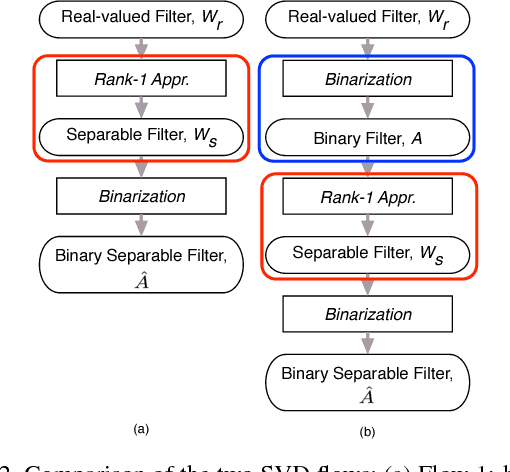
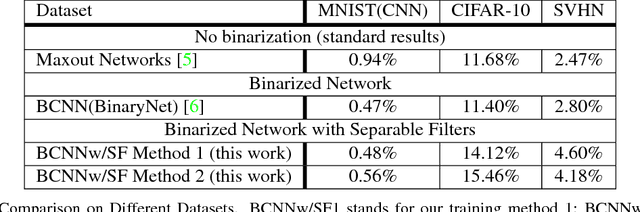
State-of-the-art convolutional neural networks are enormously costly in both compute and memory, demanding massively parallel GPUs for execution. Such networks strain the computational capabilities and energy available to embedded and mobile processing platforms, restricting their use in many important applications. In this paper, we push the boundaries of hardware-effective CNN design by proposing BCNN with Separable Filters (BCNNw/SF), which applies Singular Value Decomposition (SVD) on BCNN kernels to further reduce computational and storage complexity. To enable its implementation, we provide a closed form of the gradient over SVD to calculate the exact gradient with respect to every binarized weight in backward propagation. We verify BCNNw/SF on the MNIST, CIFAR-10, and SVHN datasets, and implement an accelerator for CIFAR-10 on FPGA hardware. Our BCNNw/SF accelerator realizes memory savings of 17% and execution time reduction of 31.3% compared to BCNN with only minor accuracy sacrifices.