 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploratory Study to Repurpose LLMs to a Unified Architecture for Time Series Classification
Jan 15, 2026Time series classification (TSC) is a core machine learning problem with broad applications. Recently there has been growing interest in repurposing large language models (LLMs) for TSC, motivated by their strong reasoning and generalization ability. Prior work has primarily focused on alignment strategies that explicitly map time series data into the textual domain; however, the choice of time series encoder architecture remains underexplored. In this work, we conduct an exploratory study of hybrid architectures that combine specialized time series encoders with a frozen LLM backbone. We evaluate a diverse set of encoder families, including Inception, convolutional, residual, transformer-based, and multilayer perceptron architectures, among which the Inception model is the only encoder architecture that consistently yields positive performance gains when integrated with an LLM backbone. Overall, this study highlights the impact of time series encoder choice in hybrid LLM architectures and points to Inception-based models as a promising direction for future LLM-driven time series learning.
Matching Skeleton-based Activity Representations with Heterogeneous Signals for HAR
Mar 17, 2025In human activity recognition (HAR), activity labels have typically been encoded in one-hot format, which has a recent shift towards using textual representations to provide contextual knowledge. Here, we argue that HAR should be anchored to physical motion data, as motion forms the basis of activity and applies effectively across sensing systems, whereas text is inherently limited. We propose SKELAR, a novel HAR framework that pretrains activity representations from skeleton data and matches them with heterogeneous HAR signals. Our method addresses two major challenges: (1) capturing core motion knowledge without context-specific details. We achieve this through a self-supervised coarse angle reconstruction task that recovers joint rotation angles, invariant to both users and deployments; (2) adapting the representations to downstream tasks with varying modalities and focuses. To address this, we introduce a self-attention matching module that dynamically prioritizes relevant body parts in a data-driven manner. Given the lack of corresponding labels in existing skeleton data, we establish MASD, a new HAR dataset with IMU, WiFi, and skeleton, collected from 20 subjects performing 27 activities. This is the first broadly applicable HAR dataset with time-synchronized data across three modalities. Experiments show that SKELAR achieves the state-of-the-art performance in both full-shot and few-shot settings. We also demonstrate that SKELAR can effectively leverage synthetic skeleton data to extend its use in scenarios without skeleton collections.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

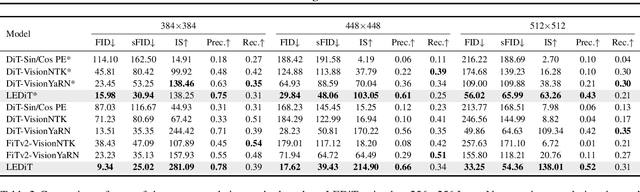
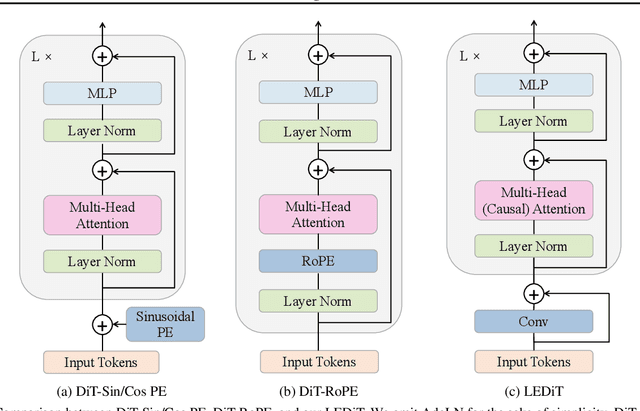
Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
Orthogonal Calibration for Asynchronous Federated Learning
Feb 21, 2025Asynchronous federated learning mitigates the inefficiency of conventional synchronous aggregation by integrating updates as they arrive and adjusting their influence based on staleness. Due to asynchrony and data heterogeneity, learning objectives at the global and local levels are inherently inconsistent -- global optimization trajectories may conflict with ongoing local updates. Existing asynchronous methods simply distribute the latest global weights to clients, which can overwrite local progress and cause model drift. In this paper, we propose OrthoFL, an orthogonal calibration framework that decouples global and local learning progress and adjusts global shifts to minimize interference before merging them into local models. In OrthoFL, clients and the server maintain separate model weights. Upon receiving an update, the server aggregates it into the global weights via a moving average. For client weights, the server computes the global weight shift accumulated during the client's delay and removes the components aligned with the direction of the received update. The resulting parameters lie in a subspace orthogonal to the client update and preserve the maximal information from the global progress. The calibrated global shift is then merged into the client weights for further training. Extensive experiments show that OrthoFL improves accuracy by 9.6% and achieves a 12$\times$ speedup compared to synchronous methods. Moreover, it consistently outperforms state-of-the-art asynchronous baselines under various delay patterns and heterogeneity scenarios.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Misusing Tools in Large Language Models With Visual Adversarial Examples
Oct 04, 2023



Large Language Models (LLMs) are being enhanced with the ability to use tools and to process multiple modalities. These new capabilities bring new benefits and also new security risks. In this work, we show that an attacker can use visual adversarial examples to cause attacker-desired tool usage. For example, the attacker could cause a victim LLM to delete calendar events, leak private conversations and book hotels. Different from prior work, our attacks can affect the confidentiality and integrity of user resources connected to the LLM while being stealthy and generalizable to multiple input prompts. We construct these attacks using gradient-based adversarial training and characterize performance along multiple dimensions. We find that our adversarial images can manipulate the LLM to invoke tools following real-world syntax almost always (~98%) while maintaining high similarity to clean images (~0.9 SSIM). Furthermore, using human scoring and automated metrics, we find that the attacks do not noticeably affect the conversation (and its semantics) between the user and the LLM.
Recursive Graphical Neural Networks for Text Classification
Sep 18, 2019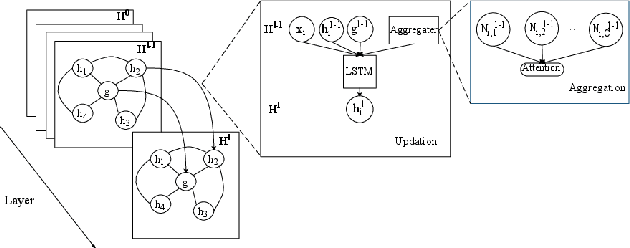

The complicated syntax structure of natural language is hard to be explicitly modeled by sequence-based models. Graph is a natural structure to describe the complicated relation between tokens. The recent advance in Graph Neural Networks (GNN) provides a powerful tool to model graph structure data, but simple graph models such as Graph Convolutional Networks (GCN) suffer from over-smoothing problem, that is, when stacking multiple layers, all nodes will converge to the same value. In this paper, we propose a novel Recursive Graphical Neural Networks model (ReGNN) to represent text organized in the form of graph. In our proposed model, LSTM is used to dynamically decide which part of the aggregated neighbor information should be transmitted to upper layers thus alleviating the over-smoothing problem. Furthermore, to encourage the exchange between the local and global information, a global graph-level node is designed. We conduct experiments on both single and multiple label text classification tasks. Experiment results show that our ReGNN model surpasses the strong baselines significantly in most of the datasets and greatly alleviates the over-smoothing problem.