 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
May 03, 2024Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
A Novel Deep Transfer Learning Method for Detection of Myocardial Infarction
Jun 22, 2019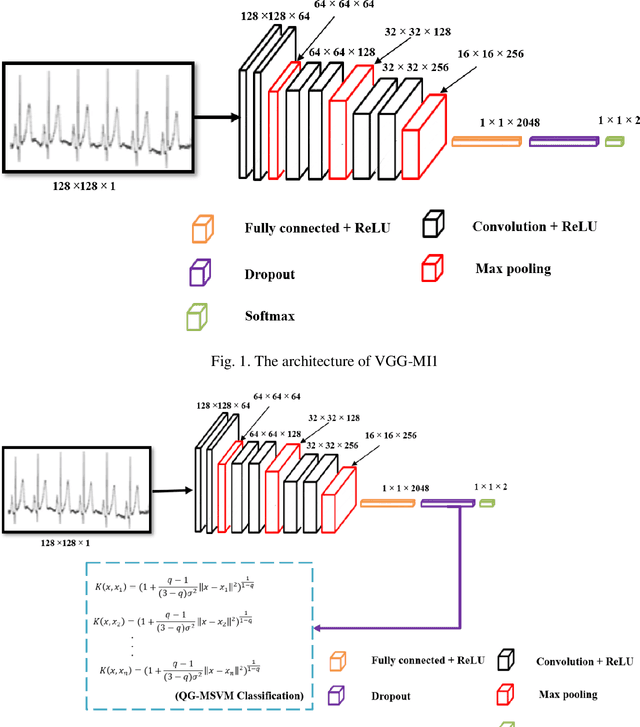
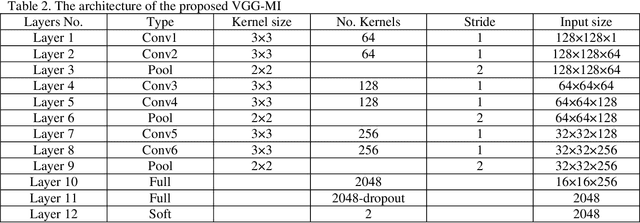
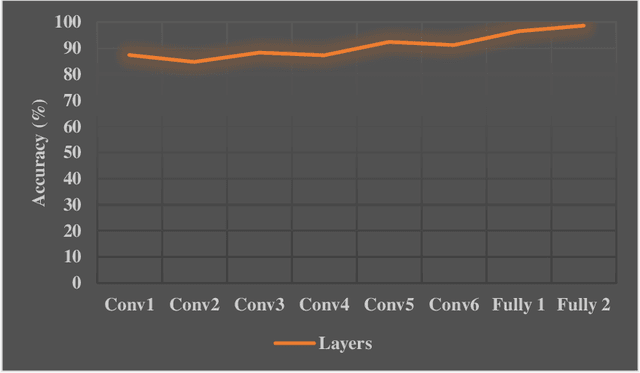

Myocardial infarction (MI), also known as a cardiac attack, is one of the common cardiac disorders occurs when one or more coronary arteries are blocked. Hence, early detection of MI is critical for the reduction of the rising of the death rate. The cardiologists use the electrocardiogram (ECG) as a diagnostic tool to monitor and reveal the MI signals. However, all the MI signals are not constant and noisy, so it is tough to detect or observe these signals manually. Several computer-aided diagnosis systems (CADs) have been suggested to solve these difficulties. In this paper, we have proposed an effective CAD system to detect MI signals using the two-dimensional convolution neural network (CNN). In this study, we have employed two ways of the transfer learning technique to retrain the pre-trained VGG-Net and obtained two new networks VGG-MI1 and VGG-MI2. Moreover, the heartbeat data augmentation techniques are employed to increase the classification performance. We have utilized two-second ECG signals from the PTB database, which has been widely employed in MI detection studies. In case of using VGG-MI1, we achieved an accuracy, sensitivity, and specificity of 99.02%, 98.76%, and 99.17% respectively and we achieved an accuracy of 99.22%, a sensitivity of 99.15%, and a specificity of 99.49% when using VGG-MI2. Results showed that the proposed algorithm is more efficient than the state-of-the-art methods in terms of accuracy sensitivity, and specificity. Finally, the proposed algorithm can assist the specialists to detect the MI signals more precisely.