 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
May 03, 2024Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
Fast Modeling and Understanding Fluid Dynamics Systems with Encoder-Decoder Networks
Jun 09, 2020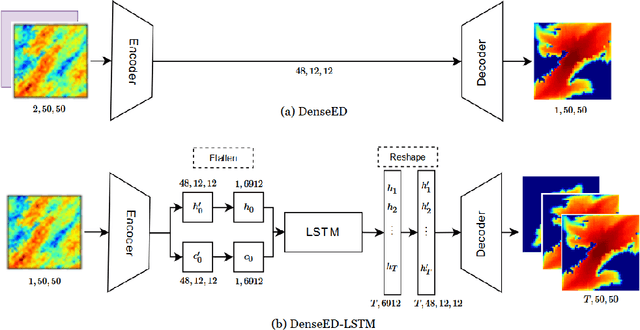
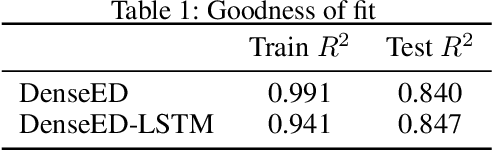


Is a deep learning model capable of understanding systems governed by certain first principle laws by only observing the system's output? Can deep learning learn the underlying physics and honor the physics when making predictions? The answers are both positive. In an effort to simulate two-dimensional subsurface fluid dynamics in porous media, we found that an accurate deep-learning-based proxy model can be taught efficiently by a computationally expensive finite-volume-based simulator. We pose the problem as an image-to-image regression, running the simulator with different input parameters to furnish a synthetic training dataset upon which we fit the deep learning models. Since the data is spatiotemporal, we compare the performance of two alternative treatments of time; a convolutional LSTM versus an autoencoder network that treats time as a direct input. Adversarial methods are adopted to address the sharp spatial gradient in the fluid dynamic problems. Compared to traditional simulation, the proposed deep learning approach enables much faster forward computation, which allows us to explore more scenarios with a much larger parameter space given the same time. It is shown that the improved forward computation efficiency is particularly valuable in solving inversion problems, where the physics model has unknown parameters to be determined by history matching. By computing the pixel-level attention of the trained model, we quantify the sensitivity of the deep learning model to key physical parameters and hence demonstrate that the inversion problems can be solved with great acceleration. We assess the efficacy of the machine learning surrogate in terms of its training speed and accuracy. The network can be trained within minutes using limited training data and achieve accuracy that scales desirably with the amount of training data supplied.