 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
May 03, 2024Traditional recommender systems such as matrix factorization methods rely on learning a shared dense embedding space to represent both items and user preferences. Sequence models such as RNN, GRUs, and, recently, Transformers have also excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs in sequential recommendations, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks
Aug 27, 2019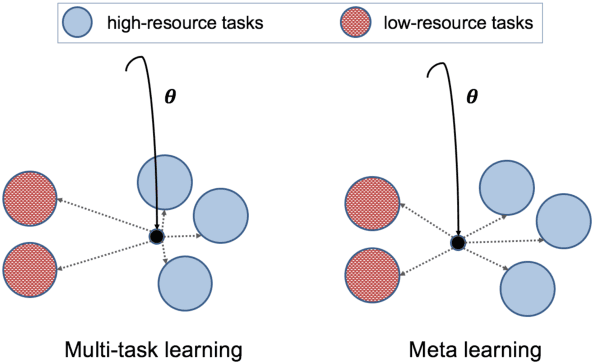
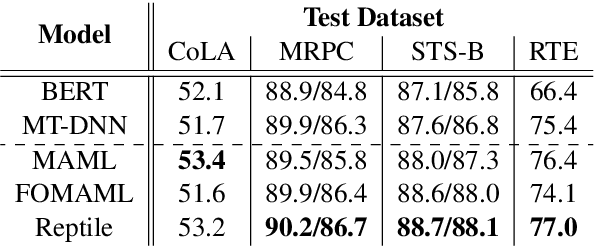
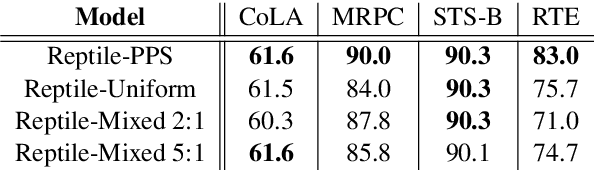
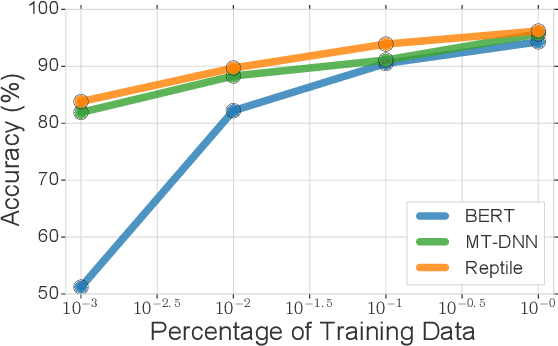
Learning general representations of text is a fundamental problem for many natural language understanding (NLU) tasks. Previously, researchers have proposed to use language model pre-training and multi-task learning to learn robust representations. However, these methods can achieve sub-optimal performance in low-resource scenarios. Inspired by the recent success of optimization-based meta-learning algorithms, in this paper, we explore the model-agnostic meta-learning algorithm (MAML) and its variants for low-resource NLU tasks. We validate our methods on the GLUE benchmark and show that our proposed models can outperform several strong baselines. We further empirically demonstrate that the learned representations can be adapted to new tasks efficiently and effectively.