 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREGEN: A Dataset and Benchmarks with Natural Language Critiques and Narratives
Mar 14, 2025This paper introduces a novel dataset REGEN (Reviews Enhanced with GEnerative Narratives), designed to benchmark the conversational capabilities of recommender Large Language Models (LLMs), addressing the limitations of existing datasets that primarily focus on sequential item prediction. REGEN extends the Amazon Product Reviews dataset by inpainting two key natural language features: (1) user critiques, representing user "steering" queries that lead to the selection of a subsequent item, and (2) narratives, rich textual outputs associated with each recommended item taking into account prior context. The narratives include product endorsements, purchase explanations, and summaries of user preferences. Further, we establish an end-to-end modeling benchmark for the task of conversational recommendation, where models are trained to generate both recommendations and corresponding narratives conditioned on user history (items and critiques). For this joint task, we introduce a modeling framework LUMEN (LLM-based Unified Multi-task Model with Critiques, Recommendations, and Narratives) which uses an LLM as a backbone for critiquing, retrieval and generation. We also evaluate the dataset's quality using standard auto-rating techniques and benchmark it by training both traditional and LLM-based recommender models. Our results demonstrate that incorporating critiques enhances recommendation quality by enabling the recommender to learn language understanding and integrate it with recommendation signals. Furthermore, LLMs trained on our dataset effectively generate both recommendations and contextual narratives, achieving performance comparable to state-of-the-art recommenders and language models.
Beyond Retrieval: Generating Narratives in Conversational Recommender Systems
Oct 22, 2024
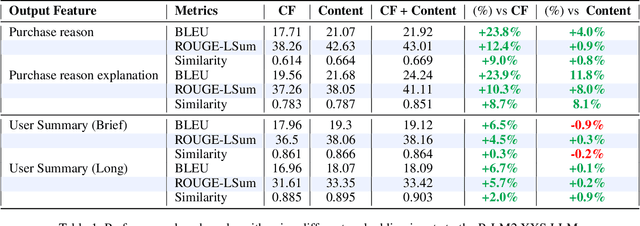


The recent advances in Large Language Model's generation and reasoning capabilities present an opportunity to develop truly conversational recommendation systems. However, effectively integrating recommender system knowledge into LLMs for natural language generation which is tailored towards recommendation tasks remains a challenge. This paper addresses this challenge by making two key contributions. First, we introduce a new dataset (REGEN) for natural language generation tasks in conversational recommendations. REGEN (Reviews Enhanced with GEnerative Narratives) extends the Amazon Product Reviews dataset with rich user narratives, including personalized explanations of product preferences, product endorsements for recommended items, and summaries of user purchase history. REGEN is made publicly available to facilitate further research. Furthermore, we establish benchmarks using well-known generative metrics, and perform an automated evaluation of the new dataset using a rater LLM. Second, the paper introduces a fusion architecture (CF model with an LLM) which serves as a baseline for REGEN. And to the best of our knowledge, represents the first attempt to analyze the capabilities of LLMs in understanding recommender signals and generating rich narratives. We demonstrate that LLMs can effectively learn from simple fusion architectures utilizing interaction-based CF embeddings, and this can be further enhanced using the metadata and personalization data associated with items. Our experiments show that combining CF and content embeddings leads to improvements of 4-12% in key language metrics compared to using either type of embedding individually. We also provide an analysis to interpret how CF and content embeddings contribute to this new generative task.
FLARE: Fusing Language Models and Collaborative Architectures for Recommender Enhancement
Sep 18, 2024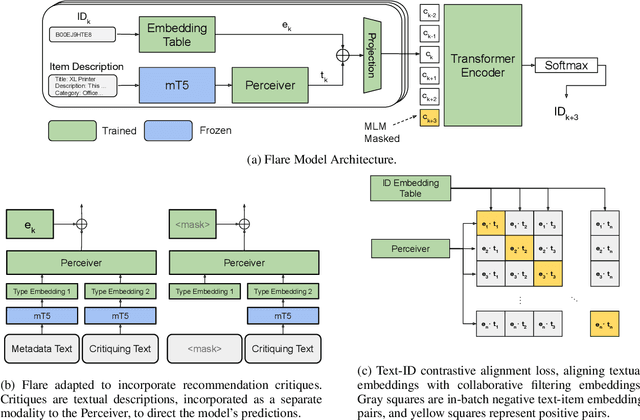


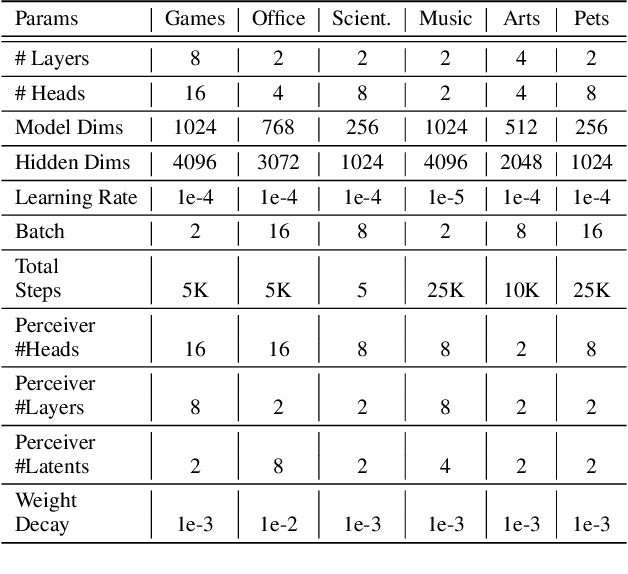
Hybrid recommender systems, combining item IDs and textual descriptions, offer potential for improved accuracy. However, previous work has largely focused on smaller datasets and model architectures. This paper introduces Flare (Fusing Language models and collaborative Architectures for Recommender Enhancement), a novel hybrid recommender that integrates a language model (mT5) with a collaborative filtering model (Bert4Rec) using a Perceiver network. This architecture allows Flare to effectively combine collaborative and content information for enhanced recommendations. We conduct a two-stage evaluation, first assessing Flare's performance against established baselines on smaller datasets, where it demonstrates competitive accuracy. Subsequently, we evaluate Flare on a larger, more realistic dataset with a significantly larger item vocabulary, introducing new baselines for this setting. Finally, we showcase Flare's inherent ability to support critiquing, enabling users to provide feedback and refine recommendations. We further leverage critiquing as an evaluation method to assess the model's language understanding and its transferability to the recommendation task.
PERSOMA: PERsonalized SOft ProMpt Adapter Architecture for Personalized Language Prompting
Aug 02, 2024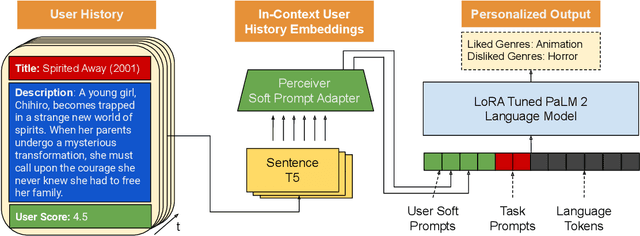



Understanding the nuances of a user's extensive interaction history is key to building accurate and personalized natural language systems that can adapt to evolving user preferences. To address this, we introduce PERSOMA, Personalized Soft Prompt Adapter architecture. Unlike previous personalized prompting methods for large language models, PERSOMA offers a novel approach to efficiently capture user history. It achieves this by resampling and compressing interactions as free form text into expressive soft prompt embeddings, building upon recent research utilizing embedding representations as input for LLMs. We rigorously validate our approach by evaluating various adapter architectures, first-stage sampling strategies, parameter-efficient tuning techniques like LoRA, and other personalization methods. Our results demonstrate PERSOMA's superior ability to handle large and complex user histories compared to existing embedding-based and text-prompt-based techniques.
User Embedding Model for Personalized Language Prompting
Jan 10, 2024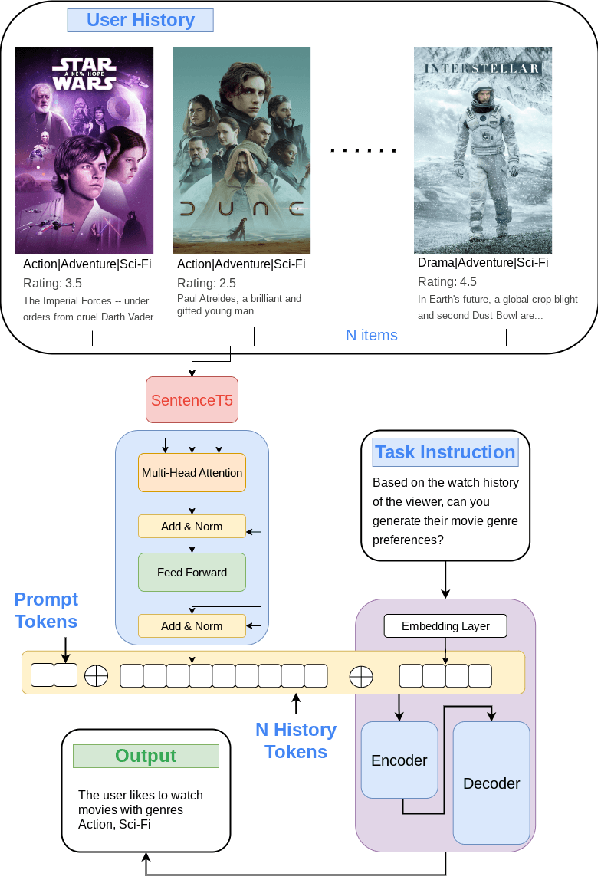

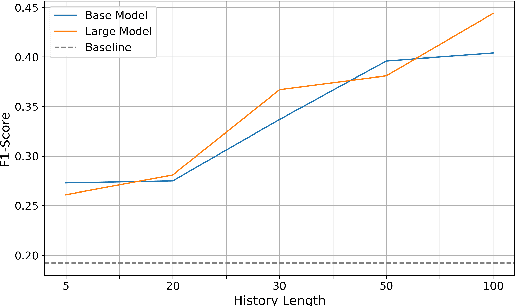

Modeling long histories plays a pivotal role in enhancing recommendation systems, allowing to capture user's evolving preferences, resulting in more precise and personalized recommendations. In this study we tackle the challenges of modeling long user histories for preference understanding in natural language. Specifically, we introduce a new User Embedding Module (UEM) that efficiently processes user history in free-form text by compressing and representing them as embeddings, to use them as soft prompts to a LM. Our experiments demonstrate the superior capability of this approach in handling significantly longer histories compared to conventional text based prompting methods, yielding substantial improvements in predictive performance. The main contribution of this research is to demonstrate the ability to bias language models with user signals represented as embeddings.
BiPhone: Modeling Inter Language Phonetic Influences in Text
Jul 06, 2023A large number of people are forced to use the Web in a language they have low literacy in due to technology asymmetries. Written text in the second language (L2) from such users often contains a large number of errors that are influenced by their native language (L1). We propose a method to mine phoneme confusions (sounds in L2 that an L1 speaker is likely to conflate) for pairs of L1 and L2. These confusions are then plugged into a generative model (Bi-Phone) for synthetically producing corrupted L2 text. Through human evaluations, we show that Bi-Phone generates plausible corruptions that differ across L1s and also have widespread coverage on the Web. We also corrupt the popular language understanding benchmark SuperGLUE with our technique (FunGLUE for Phonetically Noised GLUE) and show that SoTA language understating models perform poorly. We also introduce a new phoneme prediction pre-training task which helps byte models to recover performance close to SuperGLUE. Finally, we also release the FunGLUE benchmark to promote further research in phonetically robust language models. To the best of our knowledge, FunGLUE is the first benchmark to introduce L1-L2 interactions in text.
Multi-Task End-to-End Training Improves Conversational Recommendation
May 08, 2023



In this paper, we analyze the performance of a multitask end-to-end transformer model on the task of conversational recommendations, which aim to provide recommendations based on a user's explicit preferences expressed in dialogue. While previous works in this area adopt complex multi-component approaches where the dialogue management and entity recommendation tasks are handled by separate components, we show that a unified transformer model, based on the T5 text-to-text transformer model, can perform competitively in both recommending relevant items and generating conversation dialogue. We fine-tune our model on the ReDIAL conversational movie recommendation dataset, and create additional training tasks derived from MovieLens (such as the prediction of movie attributes and related movies based on an input movie), in a multitask learning setting. Using a series of probe studies, we demonstrate that the learned knowledge in the additional tasks is transferred to the conversational setting, where each task leads to a 9%-52% increase in its related probe score.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021
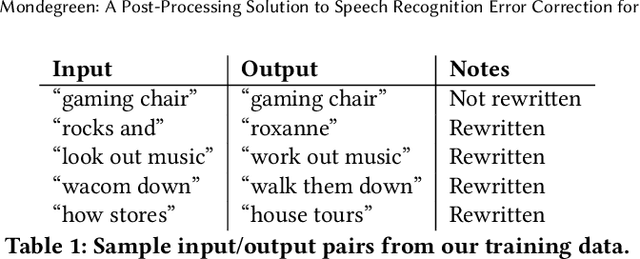


As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.