 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiPhone: Modeling Inter Language Phonetic Influences in Text
Jul 06, 2023A large number of people are forced to use the Web in a language they have low literacy in due to technology asymmetries. Written text in the second language (L2) from such users often contains a large number of errors that are influenced by their native language (L1). We propose a method to mine phoneme confusions (sounds in L2 that an L1 speaker is likely to conflate) for pairs of L1 and L2. These confusions are then plugged into a generative model (Bi-Phone) for synthetically producing corrupted L2 text. Through human evaluations, we show that Bi-Phone generates plausible corruptions that differ across L1s and also have widespread coverage on the Web. We also corrupt the popular language understanding benchmark SuperGLUE with our technique (FunGLUE for Phonetically Noised GLUE) and show that SoTA language understating models perform poorly. We also introduce a new phoneme prediction pre-training task which helps byte models to recover performance close to SuperGLUE. Finally, we also release the FunGLUE benchmark to promote further research in phonetically robust language models. To the best of our knowledge, FunGLUE is the first benchmark to introduce L1-L2 interactions in text.
HintedBT: Augmenting Back-Translation with Quality and Transliteration Hints
Sep 09, 2021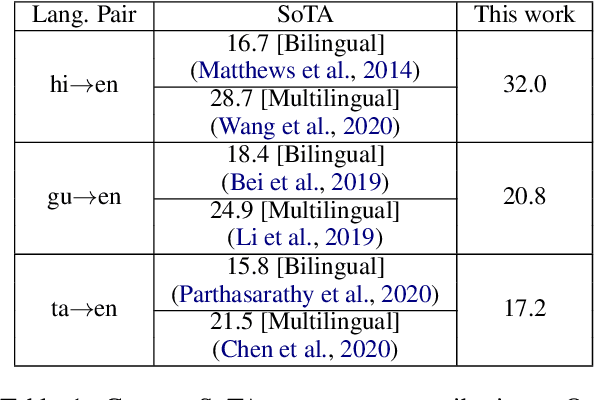


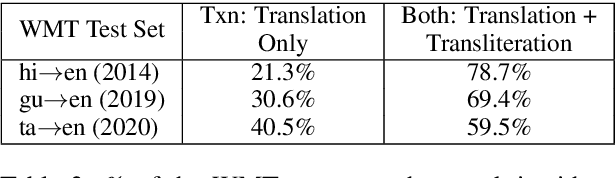
Back-translation (BT) of target monolingual corpora is a widely used data augmentation strategy for neural machine translation (NMT), especially for low-resource language pairs. To improve effectiveness of the available BT data, we introduce HintedBT -- a family of techniques which provides hints (through tags) to the encoder and decoder. First, we propose a novel method of using both high and low quality BT data by providing hints (as source tags on the encoder) to the model about the quality of each source-target pair. We don't filter out low quality data but instead show that these hints enable the model to learn effectively from noisy data. Second, we address the problem of predicting whether a source token needs to be translated or transliterated to the target language, which is common in cross-script translation tasks (i.e., where source and target do not share the written script). For such cases, we propose training the model with additional hints (as target tags on the decoder) that provide information about the operation required on the source (translation or both translation and transliteration). We conduct experiments and detailed analyses on standard WMT benchmarks for three cross-script low/medium-resource language pairs: {Hindi,Gujarati,Tamil}-to-English. Our methods compare favorably with five strong and well established baselines. We show that using these hints, both separately and together, significantly improves translation quality and leads to state-of-the-art performance in all three language pairs in corresponding bilingual settings.
Improving Segmentation for Technical Support Problems
May 22, 2020
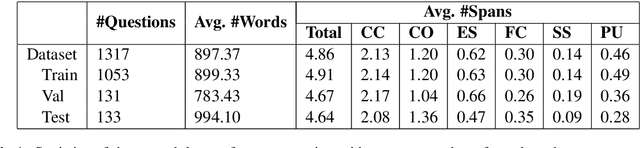


Technical support problems are often long and complex. They typically contain user descriptions of the problem, the setup, and steps for attempted resolution. Often they also contain various non-natural language text elements like outputs of commands, snippets of code, error messages or stack traces. These elements contain potentially crucial information for problem resolution. However, they cannot be correctly parsed by tools designed for natural language. In this paper, we address the problem of segmentation for technical support questions. We formulate the problem as a sequence labelling task, and study the performance of state of the art approaches. We compare this against an intuitive contextual sentence-level classification baseline, and a state of the art supervised text-segmentation approach. We also introduce a novel component of combining contextual embeddings from multiple language models pre-trained on different data sources, which achieves a marked improvement over using embeddings from a single pre-trained language model. Finally, we also demonstrate the usefulness of such segmentation with improvements on the downstream task of answer retrieval.
Mining Procedures from Technical Support Documents
May 24, 2018



Guided troubleshooting is an inherent task in the domain of technical support services. When a customer experiences an issue with the functioning of a technical service or a product, an expert user helps guide the customer through a set of steps comprising a troubleshooting procedure. The objective is to identify the source of the problem through a set of diagnostic steps and observations, and arrive at a resolution. Procedures containing these set of diagnostic steps and observations in response to different problems are common artifacts in the body of technical support documentation. The ability to use machine learning and linguistics to understand and leverage these procedures for applications like intelligent chatbots or robotic process automation, is crucial. Existing research on question answering or intelligent chatbots does not look within procedures or deep-understand them. In this paper, we outline a system for mining procedures from technical support documents. We create models for solving important subproblems like extraction of procedures, identifying decision points within procedures, identifying blocks of instructions corresponding to these decision points and mapping instructions within a decision block. We also release a dataset containing our manual annotations on publicly available support documents, to promote further research on the problem.