 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Concept Bottleneck Models
Dec 26, 2022



Concept bottleneck models (CBMs) (Koh et al. 2020) are interpretable neural networks that first predict labels for human-interpretable concepts relevant to the prediction task, and then predict the final label based on the concept label predictions.We extend CBMs to interactive prediction settings where the model can query a human collaborator for the label to some concepts. We develop an interaction policy that, at prediction time, chooses which concepts to request a label for so as to maximally improve the final prediction. We demonstrate thata simple policy combining concept prediction uncertainty and influence of the concept on the final prediction achieves strong performance and outperforms a static approach proposed in Koh et al. (2020) as well as active feature acquisition methods proposed in the literature. We show that the interactiveCBM can achieve accuracy gains of 5-10% with only 5 interactions over competitive baselines on the Caltech-UCSDBirds, CheXpert and OAI datasets.
Shaken, and Stirred: Long-Range Dependencies Enable Robust Outlier Detection with PixelCNN++
Aug 29, 2022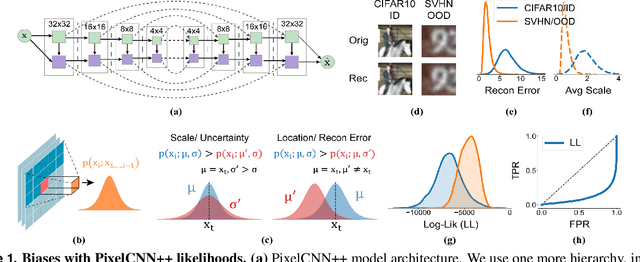
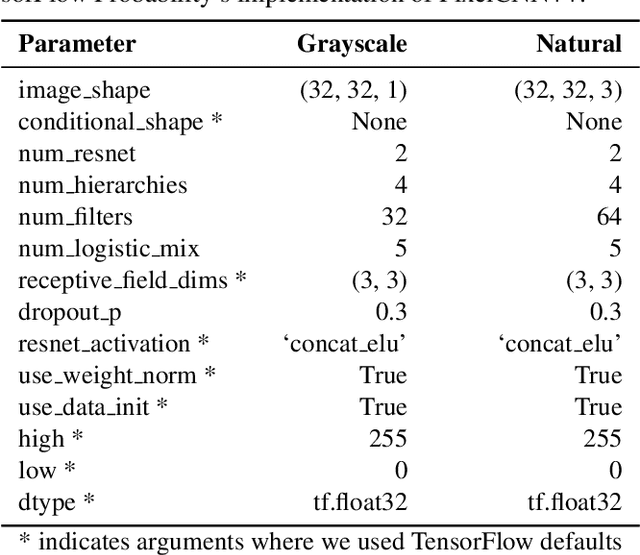
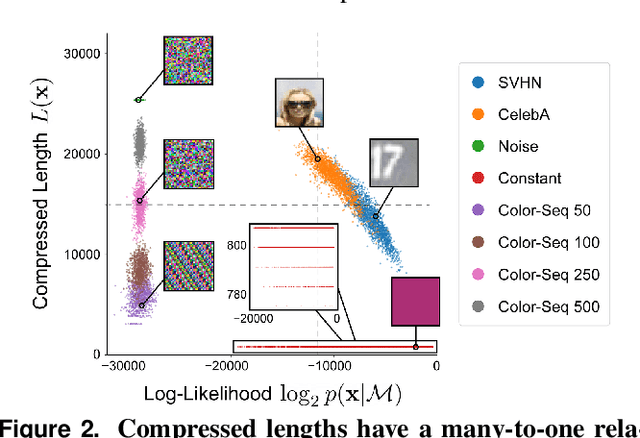
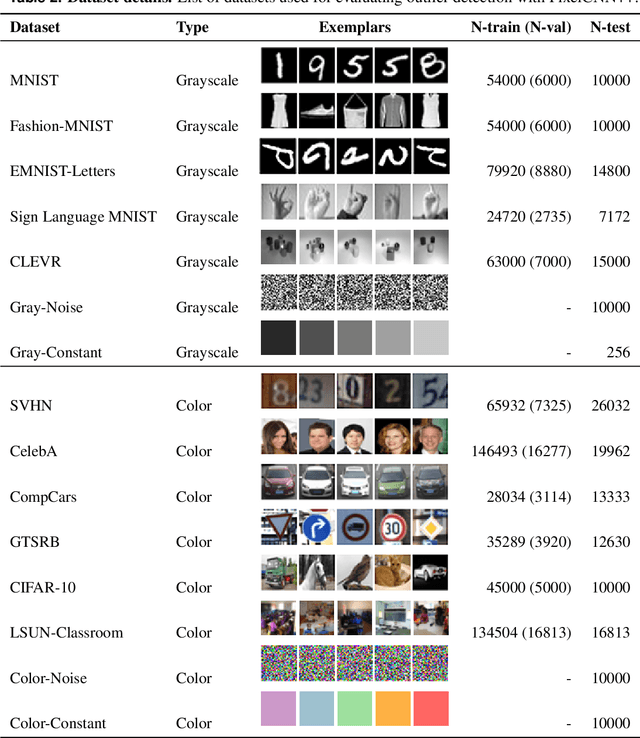
Reliable outlier detection is critical for real-world applications of deep learning models. Likelihoods produced by deep generative models, although extensively studied, have been largely dismissed as being impractical for outlier detection. For one, deep generative model likelihoods are readily biased by low-level input statistics. Second, many recent solutions for correcting these biases are computationally expensive or do not generalize well to complex, natural datasets. Here, we explore outlier detection with a state-of-the-art deep autoregressive model: PixelCNN++. We show that biases in PixelCNN++ likelihoods arise primarily from predictions based on local dependencies. We propose two families of bijective transformations that we term "shaking" and "stirring", which ameliorate low-level biases and isolate the contribution of long-range dependencies to the PixelCNN++ likelihood. These transformations are computationally inexpensive and readily applied at evaluation time. We evaluate our approaches extensively with five grayscale and six natural image datasets and show that they achieve or exceed state-of-the-art outlier detection performance. In sum, lightweight remedies suffice to achieve robust outlier detection on images with deep generative models.
Matching options to tasks using Option-Indexed Hierarchical Reinforcement Learning
Jun 12, 2022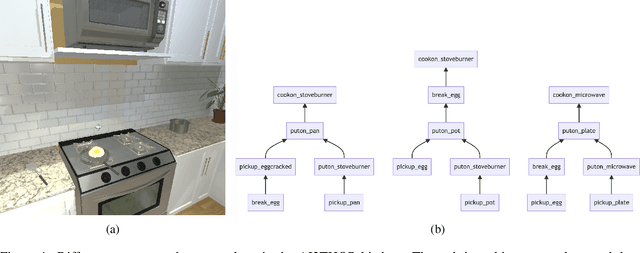
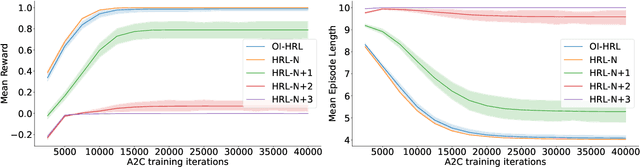
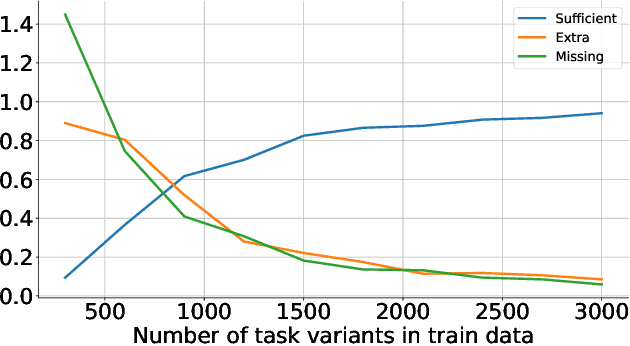
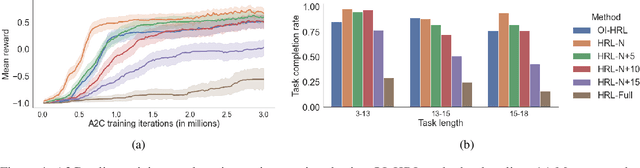
The options framework in Hierarchical Reinforcement Learning breaks down overall goals into a combination of options or simpler tasks and associated policies, allowing for abstraction in the action space. Ideally, these options can be reused across different higher-level goals; indeed, such reuse is necessary to realize the vision of a continual learning agent that can effectively leverage its prior experience. Previous approaches have only proposed limited forms of transfer of prelearned options to new task settings. We propose a novel option indexing approach to hierarchical learning (OI-HRL), where we learn an affinity function between options and the items present in the environment. This allows us to effectively reuse a large library of pretrained options, in zero-shot generalization at test time, by restricting goal-directed learning to only those options relevant to the task at hand. We develop a meta-training loop that learns the representations of options and environments over a series of HRL problems, by incorporating feedback about the relevance of retrieved options to the higher-level goal. We evaluate OI-HRL in two simulated settings - the CraftWorld and AI2THOR environments - and show that we achieve performance competitive with oracular baselines, and substantial gains over a baseline that has the entire option pool available for learning the hierarchical policy.
Efficient remedies for outlier detection with variational autoencoders
Aug 19, 2021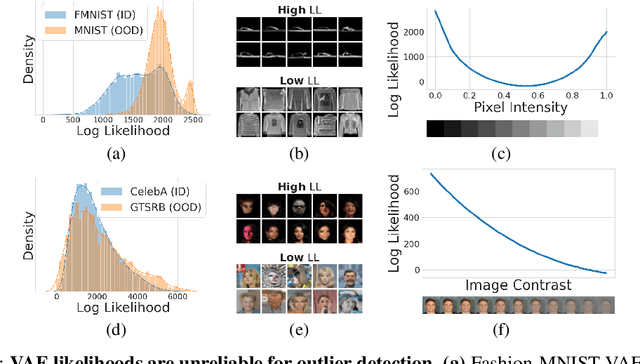

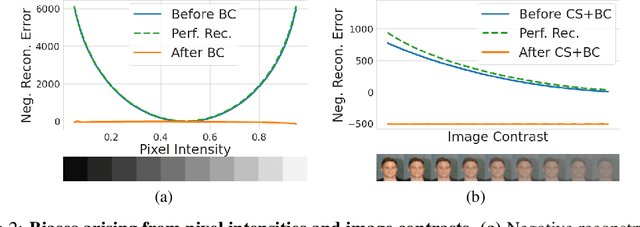
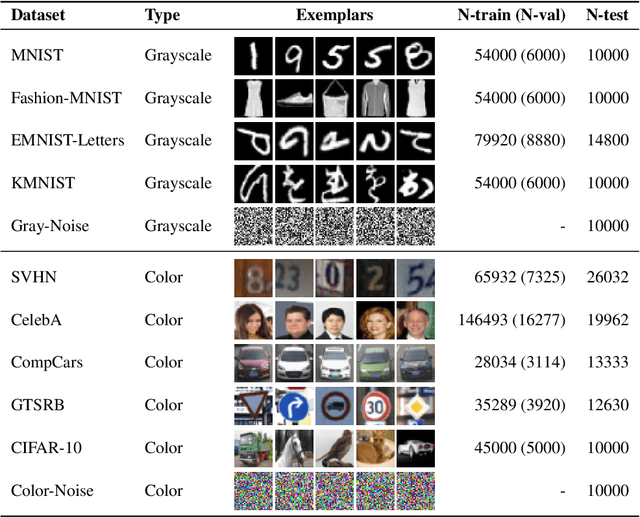
Deep networks often make confident, yet incorrect, predictions when tested with outlier data that is far removed from their training distributions. Likelihoods computed by deep generative models are a candidate metric for outlier detection with unlabeled data. Yet, previous studies have shown that such likelihoods are unreliable and can be easily biased by simple transformations to input data. Here, we examine outlier detection with variational autoencoders (VAEs), among the simplest class of deep generative models. First, we show that a theoretically-grounded correction readily ameliorates a key bias with VAE likelihood estimates. The bias correction is model-free, sample-specific, and accurately computed with the Bernoulli and continuous Bernoulli visible distributions. Second, we show that a well-known preprocessing technique, contrast normalization, extends the effectiveness of bias correction to natural image datasets. Third, we show that the variance of the likelihoods computed over an ensemble of VAEs also enables robust outlier detection. We perform a comprehensive evaluation of our remedies with nine (grayscale and natural) image datasets, and demonstrate significant advantages, in terms of both speed and accuracy, over four other state-of-the-art methods. Our lightweight remedies are biologically inspired and may serve to achieve efficient outlier detection with many types of deep generative models.
Improving Segmentation for Technical Support Problems
May 22, 2020


Technical support problems are often long and complex. They typically contain user descriptions of the problem, the setup, and steps for attempted resolution. Often they also contain various non-natural language text elements like outputs of commands, snippets of code, error messages or stack traces. These elements contain potentially crucial information for problem resolution. However, they cannot be correctly parsed by tools designed for natural language. In this paper, we address the problem of segmentation for technical support questions. We formulate the problem as a sequence labelling task, and study the performance of state of the art approaches. We compare this against an intuitive contextual sentence-level classification baseline, and a state of the art supervised text-segmentation approach. We also introduce a novel component of combining contextual embeddings from multiple language models pre-trained on different data sources, which achieves a marked improvement over using embeddings from a single pre-trained language model. Finally, we also demonstrate the usefulness of such segmentation with improvements on the downstream task of answer retrieval.