 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePORTool: Tool-Use LLM Training with Rewarded Tree
Oct 29, 2025Current tool-use large language models (LLMs) are trained on static datasets, enabling them to interact with external tools and perform multi-step, tool-integrated reasoning, which produces tool-call trajectories. However, these models imitate how a query is resolved in a generic tool-call routine, thereby failing to explore possible solutions and demonstrating limited performance in an evolved, dynamic tool-call environment. In this work, we propose PORTool, a reinforcement learning (RL) method that encourages a tool-use LLM to explore various trajectories yielding the correct answer. Specifically, this method starts with generating multiple rollouts for a given query, and some of them share the first few tool-call steps, thereby forming a tree-like structure. Next, we assign rewards to each step, based on its ability to produce a correct answer and make successful tool calls. A shared step across different trajectories receives the same reward, while different steps under the same fork receive different rewards. Finally, these step-wise rewards are used to calculate fork-relative advantages, blended with trajectory-relative advantages, to train the LLM for tool use. The experiments utilize 17 tools to address user queries, covering both time-sensitive and time-invariant topics. We conduct ablation studies to systematically justify the necessity and the design robustness of step-wise rewards. Furthermore, we compare the proposed PORTool with other training approaches and demonstrate significant improvements in final accuracy and the number of tool-call steps.
Resources and Evaluations for Multi-Distribution Dense Information Retrieval
Jun 21, 2023We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
Matching options to tasks using Option-Indexed Hierarchical Reinforcement Learning
Jun 12, 2022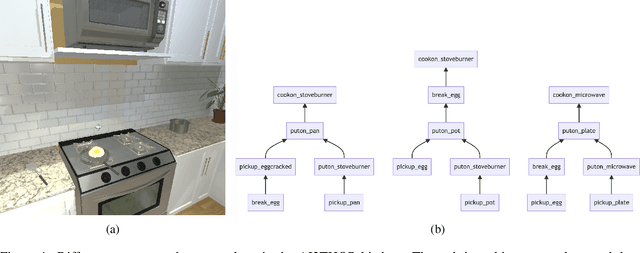
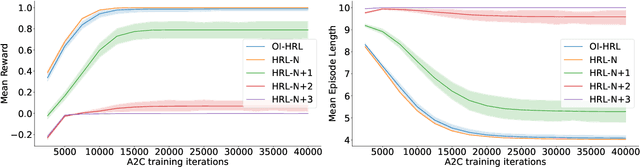
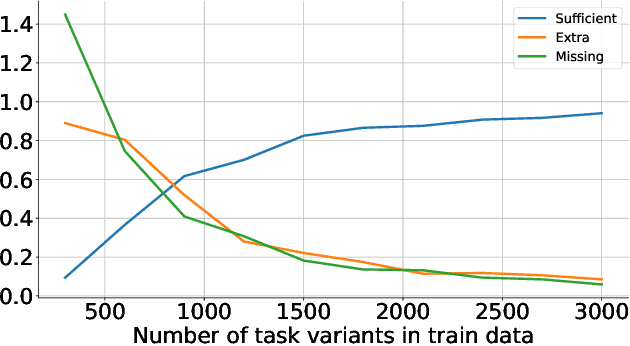
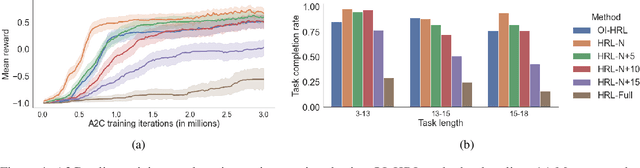
The options framework in Hierarchical Reinforcement Learning breaks down overall goals into a combination of options or simpler tasks and associated policies, allowing for abstraction in the action space. Ideally, these options can be reused across different higher-level goals; indeed, such reuse is necessary to realize the vision of a continual learning agent that can effectively leverage its prior experience. Previous approaches have only proposed limited forms of transfer of prelearned options to new task settings. We propose a novel option indexing approach to hierarchical learning (OI-HRL), where we learn an affinity function between options and the items present in the environment. This allows us to effectively reuse a large library of pretrained options, in zero-shot generalization at test time, by restricting goal-directed learning to only those options relevant to the task at hand. We develop a meta-training loop that learns the representations of options and environments over a series of HRL problems, by incorporating feedback about the relevance of retrieved options to the higher-level goal. We evaluate OI-HRL in two simulated settings - the CraftWorld and AI2THOR environments - and show that we achieve performance competitive with oracular baselines, and substantial gains over a baseline that has the entire option pool available for learning the hierarchical policy.
Accurate Online Posterior Alignments for Principled Lexically-Constrained Decoding
Apr 02, 2022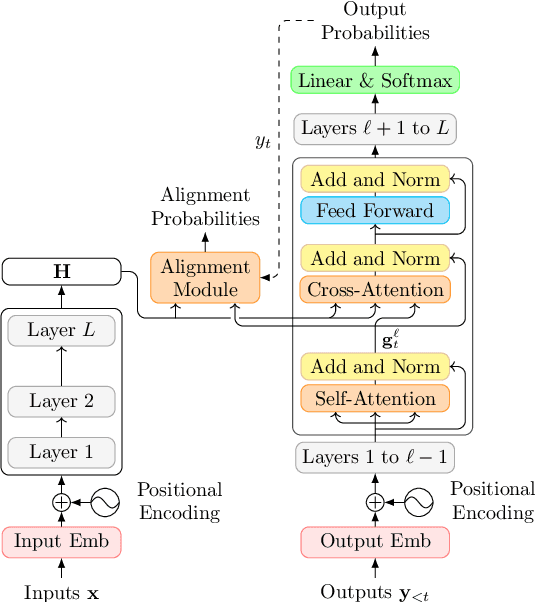
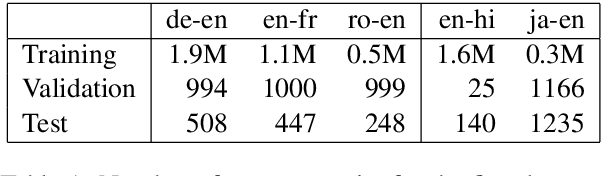
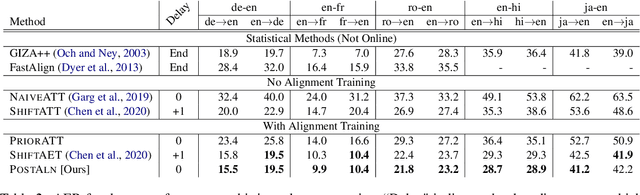
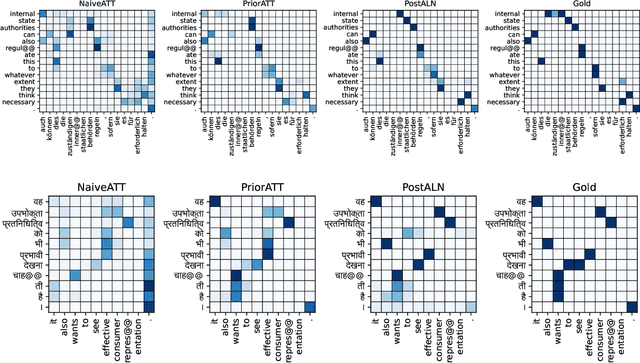
Online alignment in machine translation refers to the task of aligning a target word to a source word when the target sequence has only been partially decoded. Good online alignments facilitate important applications such as lexically constrained translation where user-defined dictionaries are used to inject lexical constraints into the translation model. We propose a novel posterior alignment technique that is truly online in its execution and superior in terms of alignment error rates compared to existing methods. Our proposed inference technique jointly considers alignment and token probabilities in a principled manner and can be seamlessly integrated within existing constrained beam-search decoding algorithms. On five language pairs, including two distant language pairs, we achieve consistent drop in alignment error rates. When deployed on seven lexically constrained translation tasks, we achieve significant improvements in BLEU specifically around the constrained positions.
Joint Learning of Hyperbolic Label Embeddings for Hierarchical Multi-label Classification
Jan 13, 2021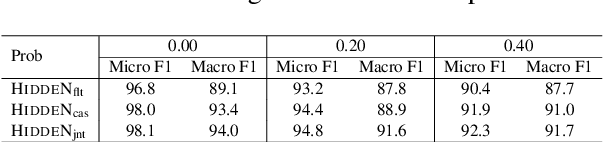

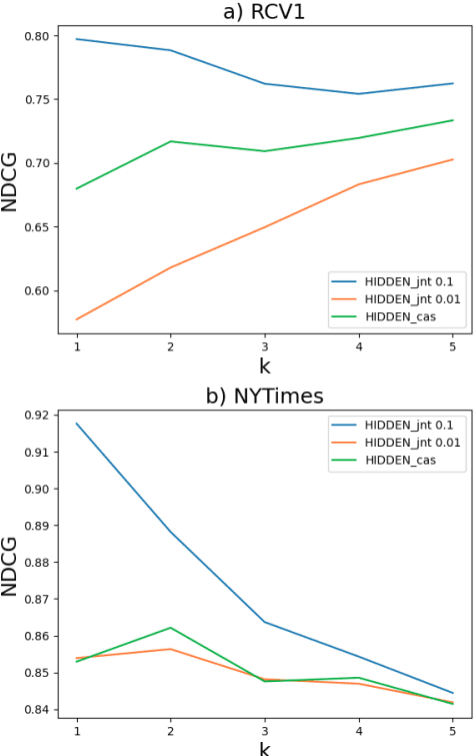
We consider the problem of multi-label classification where the labels lie in a hierarchy. However, unlike most existing works in hierarchical multi-label classification, we do not assume that the label-hierarchy is known. Encouraged by the recent success of hyperbolic embeddings in capturing hierarchical relations, we propose to jointly learn the classifier parameters as well as the label embeddings. Such a joint learning is expected to provide a twofold advantage: i) the classifier generalizes better as it leverages the prior knowledge of existence of a hierarchy over the labels, and ii) in addition to the label co-occurrence information, the label-embedding may benefit from the manifold structure of the input datapoints, leading to embeddings that are more faithful to the label hierarchy. We propose a novel formulation for the joint learning and empirically evaluate its efficacy. The results show that the joint learning improves over the baseline that employs label co-occurrence based pre-trained hyperbolic embeddings. Moreover, the proposed classifiers achieve state-of-the-art generalization on standard benchmarks. We also present evaluation of the hyperbolic embeddings obtained by joint learning and show that they represent the hierarchy more accurately than the other alternatives.
Model-agnostic Fits for Understanding Information Seeking Patterns in Humans
Dec 09, 2020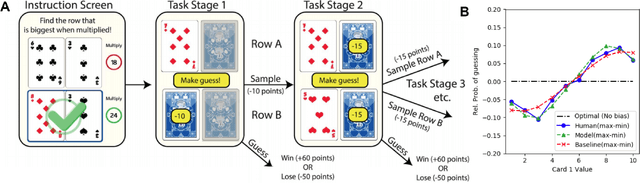
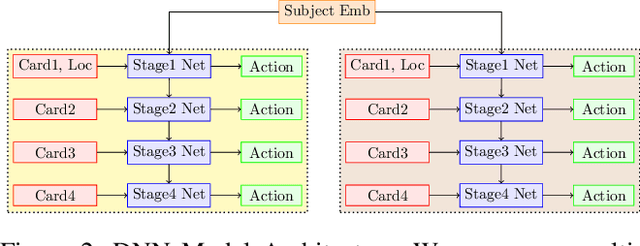
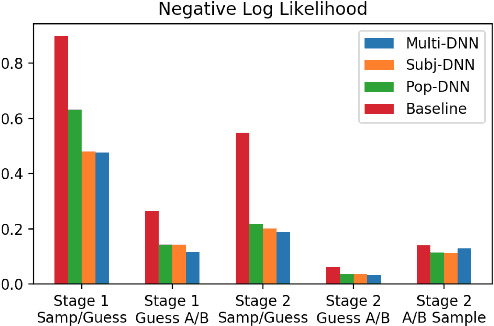
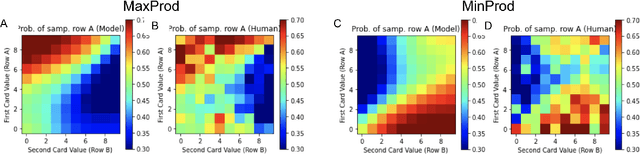
In decision making tasks under uncertainty, humans display characteristic biases in seeking, integrating, and acting upon information relevant to the task. Here, we reexamine data from previous carefully designed experiments, collected at scale, that measured and catalogued these biases in aggregate form. We design deep learning models that replicate these biases in aggregate, while also capturing individual variation in behavior. A key finding of our work is that paucity of data collected from each individual subject can be overcome by sampling large numbers of subjects from the population, while still capturing individual differences. In addition, we can predict human behavior with high accuracy without making any assumptions about task goals, reward structure, or individual biases, thus providing a model-agnostic fit to human behavior in the task. Such an approach can sidestep potential limitations in modeler-specified inductive biases, and has implications for computational modeling of human cognitive function in general, and of human-AI interfaces in particular.