 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Levels of Detail for Light Field Networks
Sep 20, 2023



Recently, several approaches have emerged for generating neural representations with multiple levels of detail (LODs). LODs can improve the rendering by using lower resolutions and smaller model sizes when appropriate. However, existing methods generally focus on a few discrete LODs which suffer from aliasing and flicker artifacts as details are changed and limit their granularity for adapting to resource limitations. In this paper, we propose a method to encode light field networks with continuous LODs, allowing for finely tuned adaptations to rendering conditions. Our training procedure uses summed-area table filtering allowing efficient and continuous filtering at various LODs. Furthermore, we use saliency-based importance sampling which enables our light field networks to distribute their capacity, particularly limited at lower LODs, towards representing the details viewers are most likely to focus on. Incorporating continuous LODs into neural representations enables progressive streaming of neural representations, decreasing the latency and resource utilization for rendering.
VIINTER: View Interpolation with Implicit Neural Representations of Images
Nov 01, 2022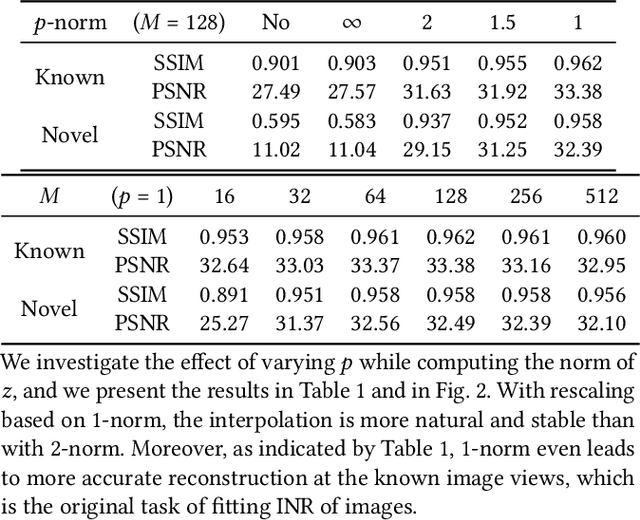

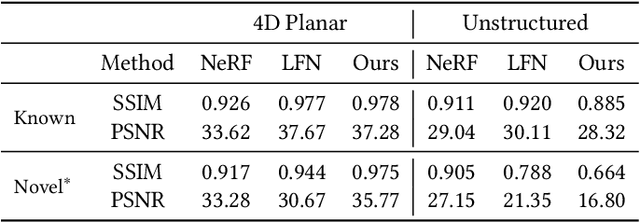
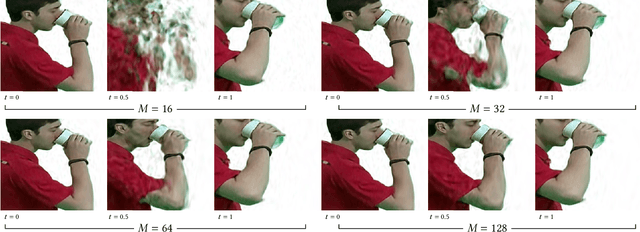
We present VIINTER, a method for view interpolation by interpolating the implicit neural representation (INR) of the captured images. We leverage the learned code vector associated with each image and interpolate between these codes to achieve viewpoint transitions. We propose several techniques that significantly enhance the interpolation quality. VIINTER signifies a new way to achieve view interpolation without constructing 3D structure, estimating camera poses, or computing pixel correspondence. We validate the effectiveness of VIINTER on several multi-view scenes with different types of camera layout and scene composition. As the development of INR of images (as opposed to surface or volume) has centered around tasks like image fitting and super-resolution, with VIINTER, we show its capability for view interpolation and offer a promising outlook on using INR for image manipulation tasks.
Progressive Multi-scale Light Field Networks
Aug 13, 2022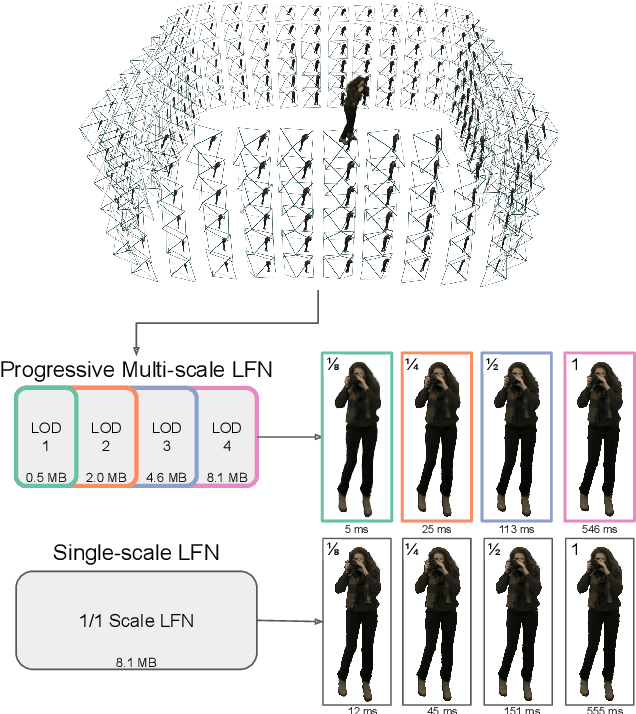


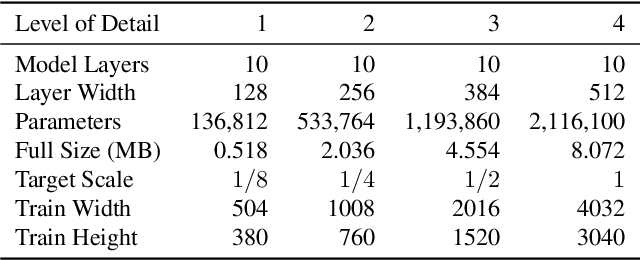
Neural representations have shown great promise in their ability to represent radiance and light fields while being very compact compared to the image set representation. However, current representations are not well suited for streaming as decoding can only be done at a single level of detail and requires downloading the entire neural network model. Furthermore, high-resolution light field networks can exhibit flickering and aliasing as neural networks are sampled without appropriate filtering. To resolve these issues, we present a progressive multi-scale light field network that encodes a light field with multiple levels of detail. Lower levels of detail are encoded using fewer neural network weights enabling progressive streaming and reducing rendering time. Our progressive multi-scale light field network addresses aliasing by encoding smaller anti-aliased representations at its lower levels of detail. Additionally, per-pixel level of detail enables our representation to support dithered transitions and foveated rendering.
PRIF: Primary Ray-based Implicit Function
Aug 12, 2022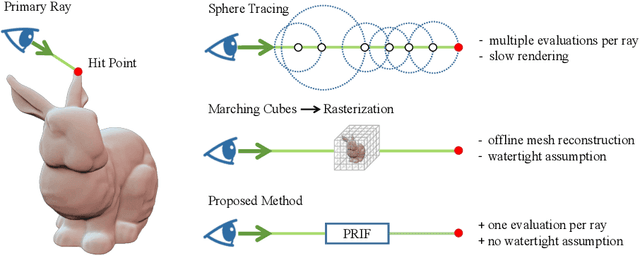
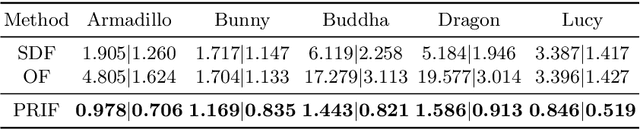
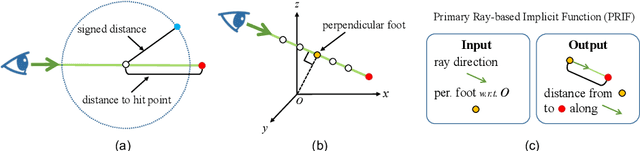

We introduce a new implicit shape representation called Primary Ray-based Implicit Function (PRIF). In contrast to most existing approaches based on the signed distance function (SDF) which handles spatial locations, our representation operates on oriented rays. Specifically, PRIF is formulated to directly produce the surface hit point of a given input ray, without the expensive sphere-tracing operations, hence enabling efficient shape extraction and differentiable rendering. We demonstrate that neural networks trained to encode PRIF achieve successes in various tasks including single shape representation, category-wise shape generation, shape completion from sparse or noisy observations, inverse rendering for camera pose estimation, and neural rendering with color.
OmniSyn: Synthesizing 360 Videos with Wide-baseline Panoramas
Feb 22, 2022


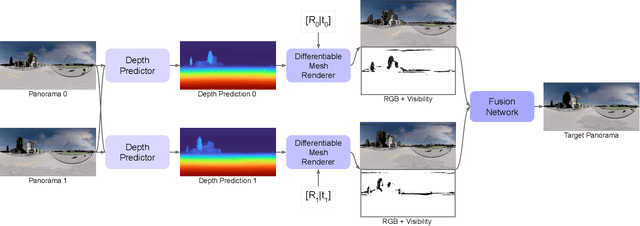
Immersive maps such as Google Street View and Bing Streetside provide true-to-life views with a massive collection of panoramas. However, these panoramas are only available at sparse intervals along the path they are taken, resulting in visual discontinuities during navigation. Prior art in view synthesis is usually built upon a set of perspective images, a pair of stereoscopic images, or a monocular image, but barely examines wide-baseline panoramas, which are widely adopted in commercial platforms to optimize bandwidth and storage usage. In this paper, we leverage the unique characteristics of wide-baseline panoramas and present OmniSyn, a novel pipeline for 360{\deg} view synthesis between wide-baseline panoramas. OmniSyn predicts omnidirectional depth maps using a spherical cost volume and a monocular skip connection, renders meshes in 360{\deg} images, and synthesizes intermediate views with a fusion network. We demonstrate the effectiveness of OmniSyn via comprehensive experimental results including comparison with the state-of-the-art methods on CARLA and Matterport datasets, ablation studies, and generalization studies on street views. We envision our work may inspire future research for this unheeded real-world task and eventually produce a smoother experience for navigating immersive maps.
Comfetch: Federated Learning of Large Networks on Memory-Constrained Clients via Sketching
Sep 17, 2021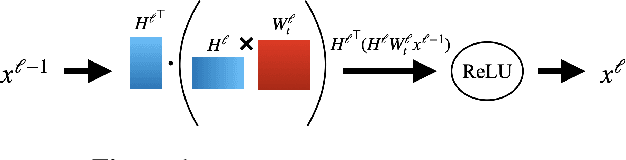
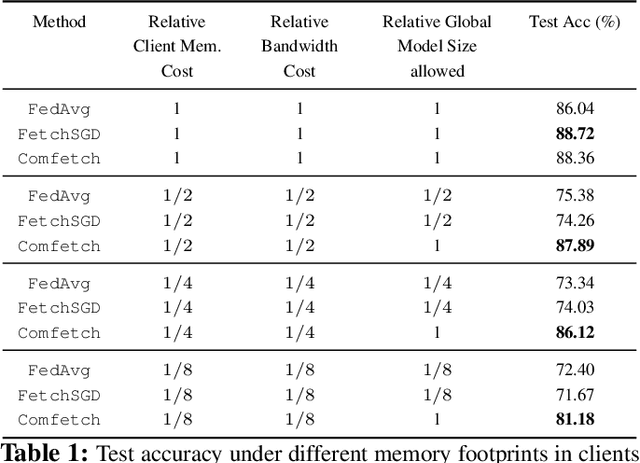
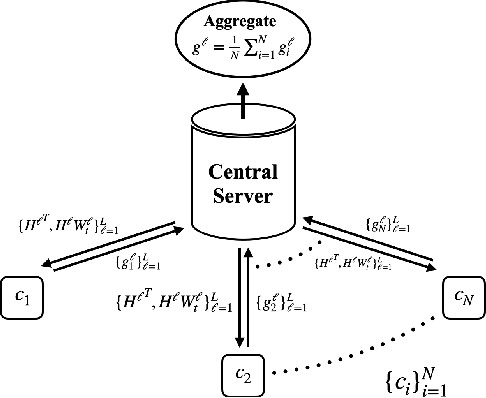
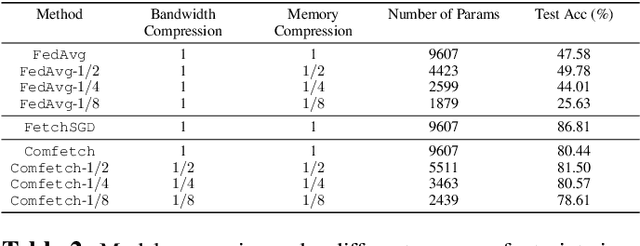
A popular application of federated learning is using many clients to train a deep neural network, the parameters of which are maintained on a central server. While recent efforts have focused on reducing communication complexity, existing algorithms assume that each participating client is able to download the current and full set of parameters, which may not be a practical assumption depending on the memory constraints of clients such as mobile devices. In this work, we propose a novel algorithm Comfetch, which allows clients to train large networks using compressed versions of the global architecture via Count Sketch, thereby reducing communication and local memory costs. We provide a theoretical convergence guarantee and experimentally demonstrate that it is possible to learn large networks, such as a deep convolutional network and an LSTM, through federated agents training on their sketched counterparts. The resulting global models exhibit competitive test accuracy when compared against the state-of-the-art FetchSGD and the classical FedAvg, both of which require clients to download the full architecture.