 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIINTER: View Interpolation with Implicit Neural Representations of Images
Nov 01, 2022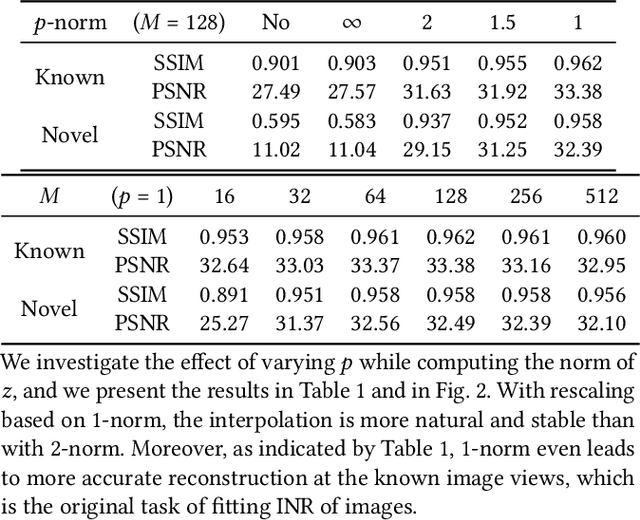

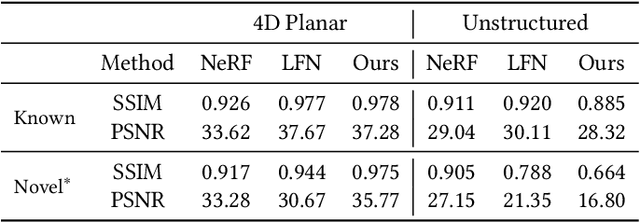
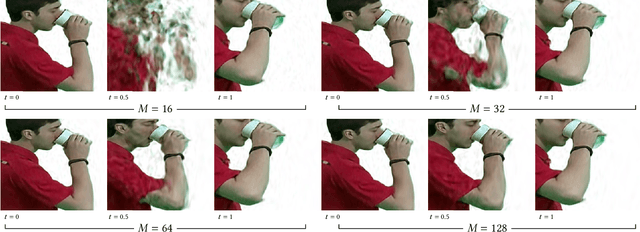
We present VIINTER, a method for view interpolation by interpolating the implicit neural representation (INR) of the captured images. We leverage the learned code vector associated with each image and interpolate between these codes to achieve viewpoint transitions. We propose several techniques that significantly enhance the interpolation quality. VIINTER signifies a new way to achieve view interpolation without constructing 3D structure, estimating camera poses, or computing pixel correspondence. We validate the effectiveness of VIINTER on several multi-view scenes with different types of camera layout and scene composition. As the development of INR of images (as opposed to surface or volume) has centered around tasks like image fitting and super-resolution, with VIINTER, we show its capability for view interpolation and offer a promising outlook on using INR for image manipulation tasks.
Improved Modeling of 3D Shapes with Multi-view Depth Maps
Sep 07, 2020

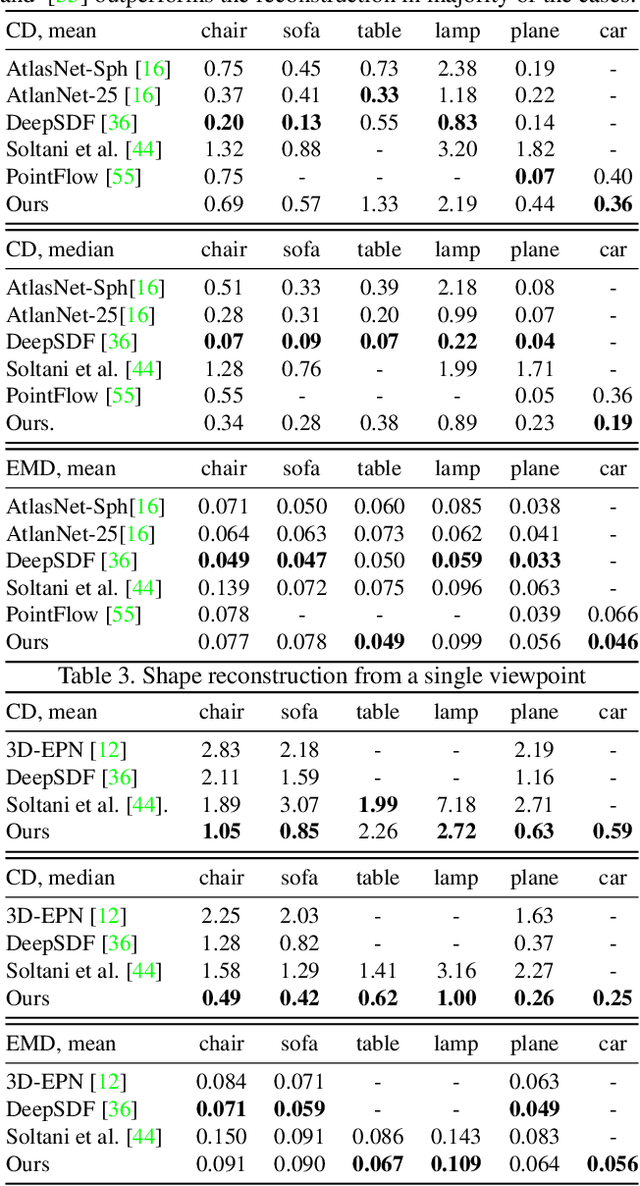

We present a simple yet effective general-purpose framework for modeling 3D shapes by leveraging recent advances in 2D image generation using CNNs. Using just a single depth image of the object, we can output a dense multi-view depth map representation of 3D objects. Our simple encoder-decoder framework, comprised of a novel identity encoder and class-conditional viewpoint generator, generates 3D consistent depth maps. Our experimental results demonstrate the two-fold advantage of our approach. First, we can directly borrow architectures that work well in the 2D image domain to 3D. Second, we can effectively generate high-resolution 3D shapes with low computational memory. Our quantitative evaluations show that our method is superior to existing depth map methods for reconstructing and synthesizing 3D objects and is competitive with other representations, such as point clouds, voxel grids, and implicit functions.