 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComfetch: Federated Learning of Large Networks on Memory-Constrained Clients via Sketching
Paper and Code
Sep 17, 2021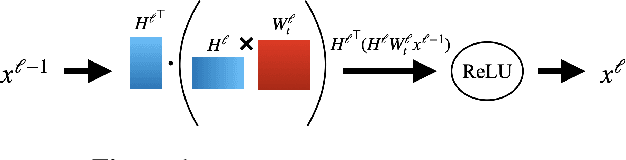
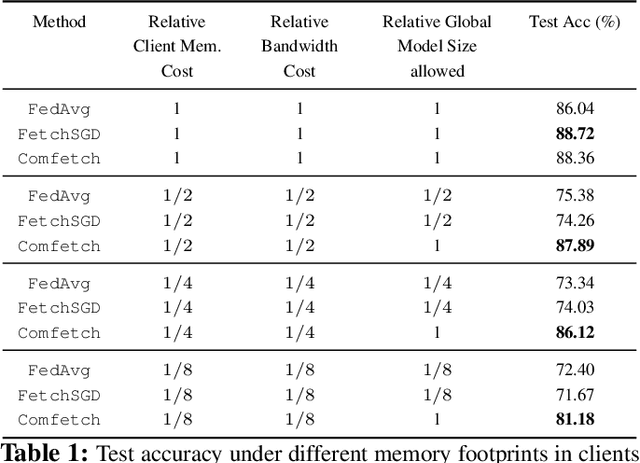
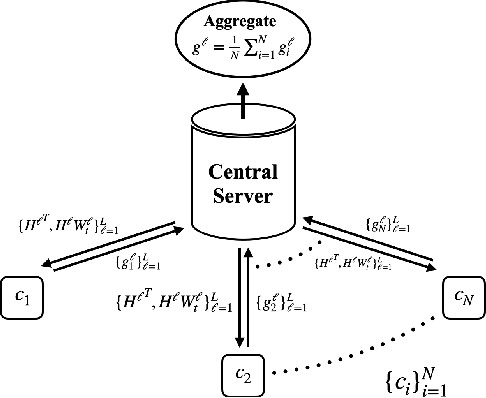
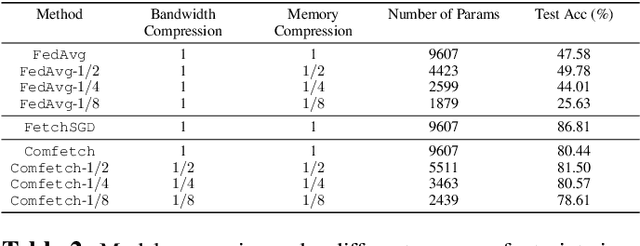
A popular application of federated learning is using many clients to train a deep neural network, the parameters of which are maintained on a central server. While recent efforts have focused on reducing communication complexity, existing algorithms assume that each participating client is able to download the current and full set of parameters, which may not be a practical assumption depending on the memory constraints of clients such as mobile devices. In this work, we propose a novel algorithm Comfetch, which allows clients to train large networks using compressed versions of the global architecture via Count Sketch, thereby reducing communication and local memory costs. We provide a theoretical convergence guarantee and experimentally demonstrate that it is possible to learn large networks, such as a deep convolutional network and an LSTM, through federated agents training on their sketched counterparts. The resulting global models exhibit competitive test accuracy when compared against the state-of-the-art FetchSGD and the classical FedAvg, both of which require clients to download the full architecture.