 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Principled Scientific Discovery through Bayesian Optimization: A Tutorial
Apr 01, 2026Traditional scientific discovery relies on an iterative hypothesise-experiment-refine cycle that has driven progress for centuries, but its intuitive, ad-hoc implementation often wastes resources, yields inefficient designs, and misses critical insights. This tutorial presents Bayesian Optimisation (BO), a principled probability-driven framework that formalises and automates this core scientific cycle. BO uses surrogate models (e.g., Gaussian processes) to model empirical observations as evolving hypotheses, and acquisition functions to guide experiment selection, balancing exploitation of known knowledge and exploration of uncharted domains to eliminate guesswork and manual trial-and-error. We first frame scientific discovery as an optimisation problem, then unpack BO's core components, end-to-end workflows, and real-world efficacy via case studies in catalysis, materials science, organic synthesis, and molecule discovery. We also cover critical technical extensions for scientific applications, including batched experimentation, heteroscedasticity, contextual optimisation, and human-in-the-loop integration. Tailored for a broad audience, this tutorial bridges AI advances in BO with practical natural science applications, offering tiered content to empower cross-disciplinary researchers to design more efficient experiments and accelerate principled scientific discovery.
Learning to See through Illumination Extremes with Event Streaming in Multimodal Large Language Models
Mar 29, 2026Multimodal Large Language Models (MLLMs) perform strong vision-language reasoning under standard conditions but fail in extreme illumination, where RGB inputs lose irrevocable structure and semantics. We propose Event-MLLM, an event-enhanced model that performs all-light visual reasoning by dynamically fusing event streams with RGB frames. Two key components drive our approach: an Illumination Indicator - a learnable signal derived from a DINOv2 branch that represents exposure degradation and adaptively modulates event-RGB fusion - and an Illumination Correction Loss that aligns fused features with non-degraded (normal-light) semantics in the latent space, compensating for information lost in extreme lighting. We curate the first multi-illumination event-instruction corpus for MLLMs, with 2,241 event-RGB samples (around 6 QA pairs each) across diverse scenes and 17 brightness rates (0.05x - 20x), plus an instruct-following benchmark for reasoning, counting, and fine-grained recognition under extreme lighting. Experiments show that Event-MLLM markedly outperforms general-purpose, illumination-adaptive, and event-only baselines, setting a new state of the art in robust multimodal perception and reasoning under challenging illumination.
AI/ML for mobile networks: Current status in Rel. 19 and challenges ahead
Mar 15, 2026The transformative power of artificial intelligence (AI) and machine learning (ML) is recognized as a key enabler for sixth generation (6G) mobile networks by both academia and industry. Research on AI/ML in mobile networks has been ongoing for years, and the 3rd generation partnership project (3GPP) launched standardization efforts to integrate AI into mobile networks. However, a comprehensive review of the current status and challenges of the standardization of AI/ML for mobile networks is still missing. To this end, we provided a comprehensive review of the standardization efforts by 3GPP on AI/ML for mobile networks. This includes an overview of the general AI/ML framework, representative use cases (i.e., CSI feedback, beam management and positioning), and corresponding evaluation matrices. We emphasized the key research challenges on dataset preparation, generalization evaluation and baseline AI/ML models selection. Using CSI feedback as a case study, given the test dataset 2, we demonstrated that the pre-training-fine-tuning paradigm (i.e., pre-training using dataset 1 and fine-tuning using dataset 2) outperforms training on dataset 2. Moreover, we observed the highest performance enhancements in Transformer-based models through fine-tuning, showing its great generalization potential at large floating-point operations (FLOPs). Finally, we outlined future research directions for the application of AI/ML in mobile networks.
Explainable Interictal Epileptiform Discharge Detection Method Based on Scalp EEG and Retrieval-Augmented Generation
Feb 15, 2026The detection of interictal epileptiform discharge (IED) is crucial for the diagnosis of epilepsy, but automated methods often lack interpretability. This study proposes IED-RAG, an explainable multimodal framework for joint IED detection and report generation. Our approach employs a dual-encoder to extract electrophysiological and semantic features, aligned via contrastive learning in a shared EEG-text embedding space. During inference, clinically relevant EEG-text pairs are retrieved from a vector database as explicit evidence to condition a large language model (LLM) for the generation of evidence-based reports. Evaluated on a private dataset from Wuhan Children's Hospital and the public TUH EEG Events Corpus (TUEV), the framework achieved balanced accuracies of 89.17\% and 71.38\%, with BLEU scores of 89.61\% and 64.14\%, respectively. The results demonstrate that retrieval of explicit evidence enhances both diagnostic performance and clinical interpretability compared to standard black-box methods.
WMVLM: Evaluating Diffusion Model Image Watermarking via Vision-Language Models
Jan 29, 2026Digital watermarking is essential for securing generated images from diffusion models. Accurate watermark evaluation is critical for algorithm development, yet existing methods have significant limitations: they lack a unified framework for both residual and semantic watermarks, provide results without interpretability, neglect comprehensive security considerations, and often use inappropriate metrics for semantic watermarks. To address these gaps, we propose WMVLM, the first unified and interpretable evaluation framework for diffusion model image watermarking via vision-language models (VLMs). We redefine quality and security metrics for each watermark type: residual watermarks are evaluated by artifact strength and erasure resistance, while semantic watermarks are assessed through latent distribution shifts. Moreover, we introduce a three-stage training strategy to progressively enable the model to achieve classification, scoring, and interpretable text generation. Experiments show WMVLM outperforms state-of-the-art VLMs with strong generalization across datasets, diffusion models, and watermarking methods.
ReinPath: A Multimodal Reinforcement Learning Approach for Pathology
Jan 21, 2026Interpretability is significant in computational pathology, leading to the development of multimodal information integration from histopathological image and corresponding text data.However, existing multimodal methods have limited interpretability due to the lack of high-quality dataset that support explicit reasoning and inference and simple reasoning process.To address the above problems, we introduce a novel multimodal pathology large language model with strong reasoning capabilities.To improve the generation of accurate and contextually relevant textual descriptions, we design a semantic reward strategy integrated with group relative policy optimization.We construct a high-quality pathology visual question answering (VQA) dataset, specifically designed to support complex reasoning tasks.Comprehensive experiments conducted on this dataset demonstrate that our method outperforms state-of-the-art methods, even when trained with only 20% of the data.Our method also achieves comparable performance on downstream zero-shot image classification task compared with CLIP.
CSI-MAE: A Masked Autoencoder-based Channel Foundation Model
Jan 07, 2026Self-Supervised Learning (SSL) has emerged as a key technique in machine learning, tackling challenges such as limited labeled data, high annotation costs, and variable wireless channel conditions. It is essential for developing Channel Foundation Models (CFMs), which extract latent features from channel state information (CSI) and adapt to different wireless settings. Yet, existing CFMs have notable drawbacks: heavy reliance on scenario-specific data hinders generalization, they focus on single/dual tasks, and lack zero-shot learning ability. In this paper, we propose CSI-MAE, a generalized CFM leveraging masked autoencoder for cross-scenario generalization. Trained on 3GPP channel model datasets, it integrates sensing and communication via CSI perception and generation, proven effective across diverse tasks. A lightweight decoder finetuning strategy cuts training costs while maintaining competitive performance. Under this approach, CSI-MAE matches or surpasses supervised models. With full-parameter finetuning, it achieves the state-of-the-art performance. Its exceptional zero-shot transferability also rivals supervised techniques in cross-scenario applications, driving wireless communication innovation.
A high-capacity linguistic steganography based on entropy-driven rank-token mapping
Oct 27, 2025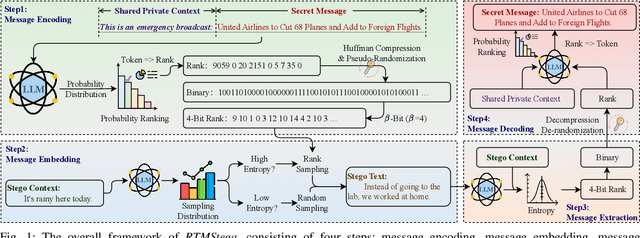
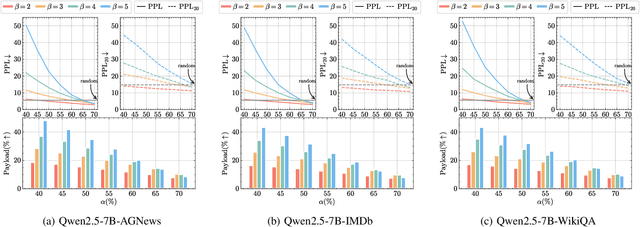
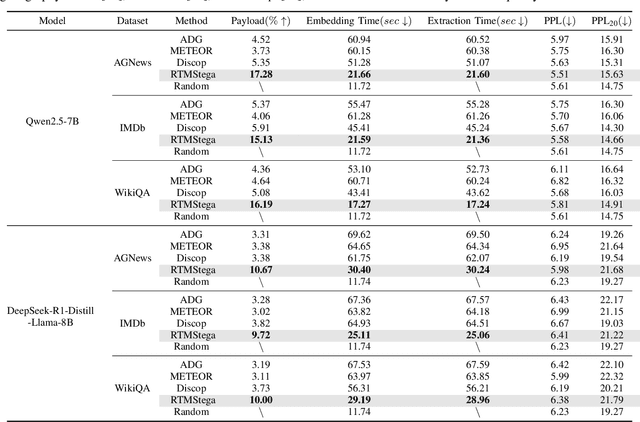

Linguistic steganography enables covert communication through embedding secret messages into innocuous texts; however, current methods face critical limitations in payload capacity and security. Traditional modification-based methods introduce detectable anomalies, while retrieval-based strategies suffer from low embedding capacity. Modern generative steganography leverages language models to generate natural stego text but struggles with limited entropy in token predictions, further constraining capacity. To address these issues, we propose an entropy-driven framework called RTMStega that integrates rank-based adaptive coding and context-aware decompression with normalized entropy. By mapping secret messages to token probability ranks and dynamically adjusting sampling via context-aware entropy-based adjustments, RTMStega achieves a balance between payload capacity and imperceptibility. Experiments across diverse datasets and models demonstrate that RTMStega triples the payload capacity of mainstream generative steganography, reduces processing time by over 50%, and maintains high text quality, offering a trustworthy solution for secure and efficient covert communication.
C2S-AE: CSI to Sensing enabled by an Auto-Encoder-based Framework
Mar 02, 2025



Next-generation mobile networks are set to utilize integrated sensing and communication (ISAC) as a critical technology, providing significant support for sectors like the industrial Internet of Things (IIoT), extended reality (XR), and smart home applications. A key challenge in ISAC implementation is the extraction of sensing parameters from radio signals, a task that conventional methods struggle to achieve due to the complexity of acquiring sensing channel data. In this paper, we introduce a novel auto-encoder (AE)-based framework to acquire sensing information using channel state information (CSI). Specifically, our framework, termed C2S (CSI to sensing)-AE, learns the relationship between CSI and the delay power spectrum (DPS), from which the range information can be readily accessed. To validate our framework's performance, we conducted measurements of DPS and CSI in real-world scenarios and introduced the dataset 'SHU7'. Our extensive experiments demonstrate that the framework excels in C2S extrapolation, surpassing existing methods in terms of accuracy for both delay and signal strength of individual paths. This innovative approach holds the potential to greatly enhance sensing capabilities in future mobile networks, paving the way for more robust and versatile ISAC applications.
MTCA: Multi-Task Channel Analysis for Wireless Communication
Feb 26, 2025



In modern wireless communication systems, the effective processing of Channel State Information (CSI) is crucial for enhancing communication quality and reliability. However, current methods often handle different tasks in isolation, thereby neglecting the synergies among various tasks and leading to extract CSI features inadequately for subsequent analysis. To address these limitations, this paper introduces a novel Multi-Task Channel Analysis framework named MTCA, aimed at improving the performance of wireless communication even sensing. MTCA is designed to handle four critical tasks, including channel prediction, antenna-domain channel extrapolation, channel identification, and scenario classification. Experiments conducted on a multi-scenario, multi-antenna dataset tailored for UAV-based communications demonstrate that the proposed MTCA exhibits superior comprehension of CSI, achieving enhanced performance across all evaluated tasks. Notably, MTCA reached 100% prediction accuracy in channel identification and scenario classification. Compared to the previous state-of-the-art methods, MTCA improved channel prediction performance by 20.1% and antenna-domain extrapolation performance by 54.5%.