 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Transportation Mode Using Dense Smartphone GPS Trajectories and Transformer Models
Feb 27, 2026Transportation mode detection is an important topic within GeoAI and transportation research. In this study, we introduce SpeedTransformer, a novel Transformer-based model that relies solely on speed inputs to infer transportation modes from dense smartphone GPS trajectories. In benchmark experiments, SpeedTransformer outperformed traditional deep learning models, such as the Long Short-Term Memory (LSTM) network. Moreover, the model demonstrated strong flexibility in transfer learning, achieving high accuracy across geographical regions after fine-tuning with small datasets. Finally, we deployed the model in a real-world experiment, where it consistently outperformed baseline models under complex built environments and high data uncertainty. These findings suggest that Transformer architectures, when combined with dense GPS trajectories, hold substantial potential for advancing transportation mode detection and broader mobility-related research.
Variational and Explanatory Neural Networks for Encoding Cancer Profiles and Predicting Drug Responses
Jul 05, 2024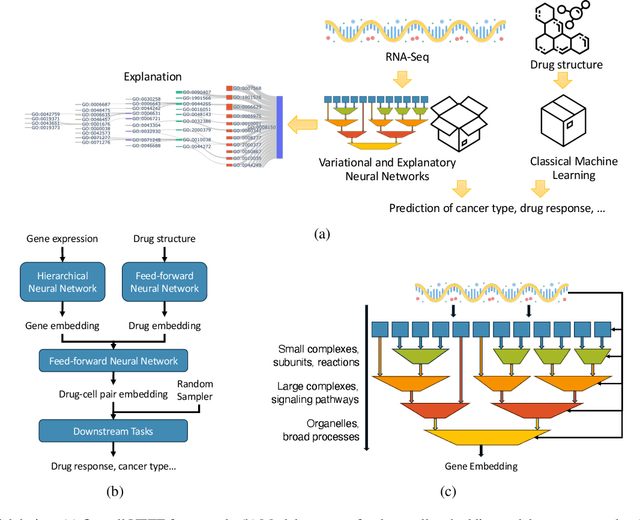

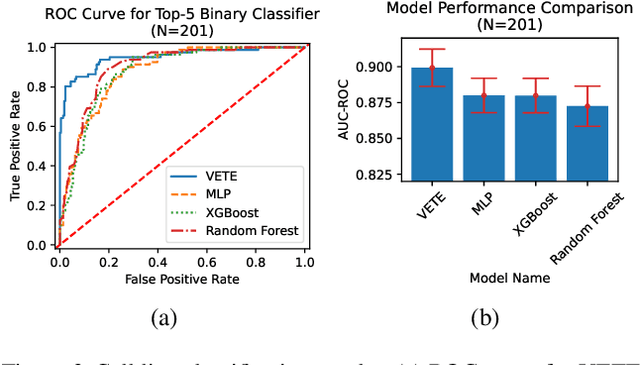
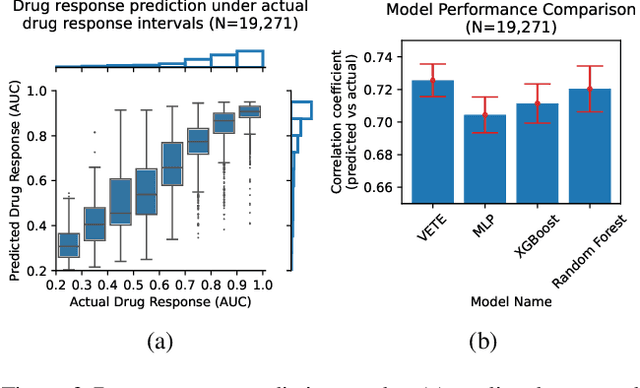
Human cancers present a significant public health challenge and require the discovery of novel drugs through translational research. Transcriptomics profiling data that describes molecular activities in tumors and cancer cell lines are widely utilized for predicting anti-cancer drug responses. However, existing AI models face challenges due to noise in transcriptomics data and lack of biological interpretability. To overcome these limitations, we introduce VETE (Variational and Explanatory Transcriptomics Encoder), a novel neural network framework that incorporates a variational component to mitigate noise effects and integrates traceable gene ontology into the neural network architecture for encoding cancer transcriptomics data. Key innovations include a local interpretability-guided method for identifying ontology paths, a visualization tool to elucidate biological mechanisms of drug responses, and the application of centralized large scale hyperparameter optimization. VETE demonstrated robust accuracy in cancer cell line classification and drug response prediction. Additionally, it provided traceable biological explanations for both tasks and offers insights into the mechanisms underlying its predictions. VETE bridges the gap between AI-driven predictions and biologically meaningful insights in cancer research, which represents a promising advancement in the field.
Nonparametric Automatic Differentiation Variational Inference with Spline Approximation
Mar 10, 2024



Automatic Differentiation Variational Inference (ADVI) is efficient in learning probabilistic models. Classic ADVI relies on the parametric approach to approximate the posterior. In this paper, we develop a spline-based nonparametric approximation approach that enables flexible posterior approximation for distributions with complicated structures, such as skewness, multimodality, and bounded support. Compared with widely-used nonparametric variational inference methods, the proposed method is easy to implement and adaptive to various data structures. By adopting the spline approximation, we derive a lower bound of the importance weighted autoencoder and establish the asymptotic consistency. Experiments demonstrate the efficiency of the proposed method in approximating complex posterior distributions and improving the performance of generative models with incomplete data.
Comparing Baseline Shapley and Integrated Gradients for Local Explanation: Some Additional Insights
Aug 12, 2022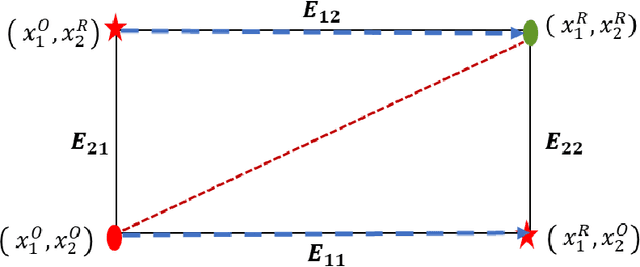
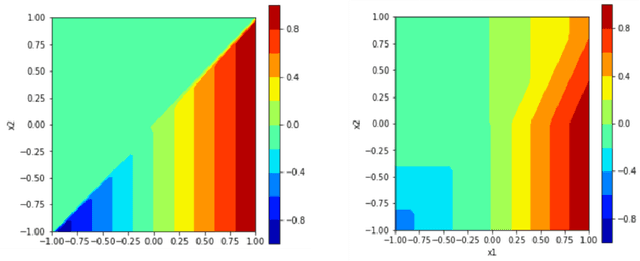

There are many different methods in the literature for local explanation of machine learning results. However, the methods differ in their approaches and often do not provide same explanations. In this paper, we consider two recent methods: Integrated Gradients (Sundararajan, Taly, & Yan, 2017) and Baseline Shapley (Sundararajan and Najmi, 2020). The original authors have already studied the axiomatic properties of the two methods and provided some comparisons. Our work provides some additional insights on their comparative behavior for tabular data. We discuss common situations where the two provide identical explanations and where they differ. We also use simulation studies to examine the differences when neural networks with ReLU activation function is used to fit the models.
Explaining Adverse Actions in Credit Decisions Using Shapley Decomposition
Apr 26, 2022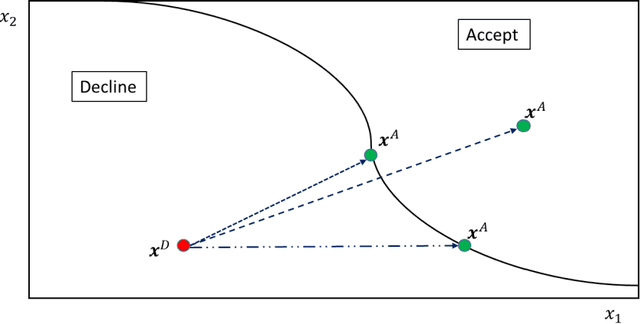
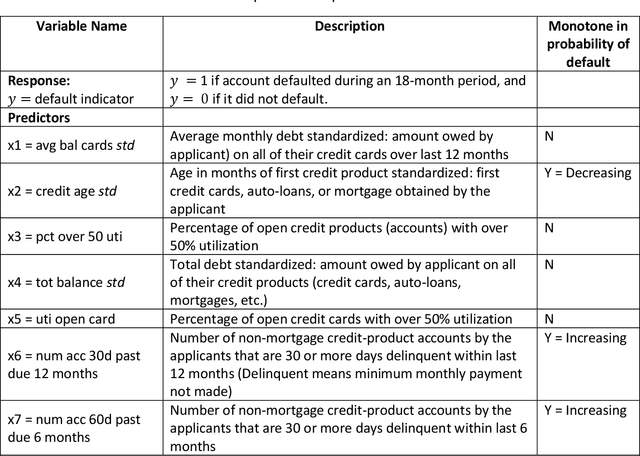
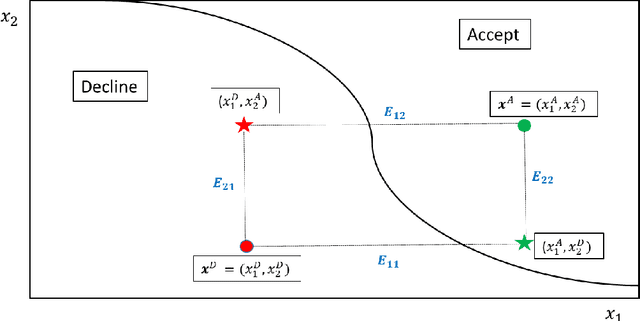

When a financial institution declines an application for credit, an adverse action (AA) is said to occur. The applicant is then entitled to an explanation for the negative decision. This paper focuses on credit decisions based on a predictive model for probability of default and proposes a methodology for AA explanation. The problem involves identifying the important predictors responsible for the negative decision and is straightforward when the underlying model is additive. However, it becomes non-trivial even for linear models with interactions. We consider models with low-order interactions and develop a simple and intuitive approach based on first principles. We then show how the methodology generalizes to the well-known Shapely decomposition and the recently proposed concept of Baseline Shapley (B-Shap). Unlike other Shapley techniques in the literature for local interpretability of machine learning results, B-Shap is computationally tractable since it involves just function evaluations. An illustrative case study is used to demonstrate the usefulness of the method. The paper also discusses situations with highly correlated predictors and desirable properties of fitted models in the credit-lending context, such as monotonicity and continuity.
Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters
Jan 29, 2022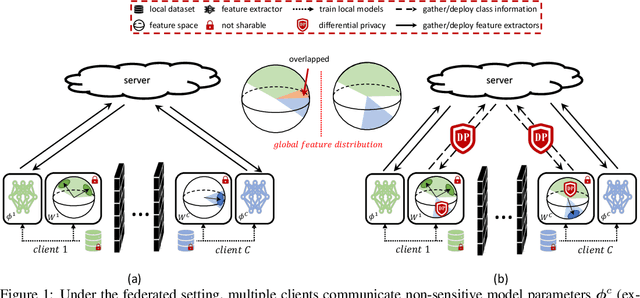
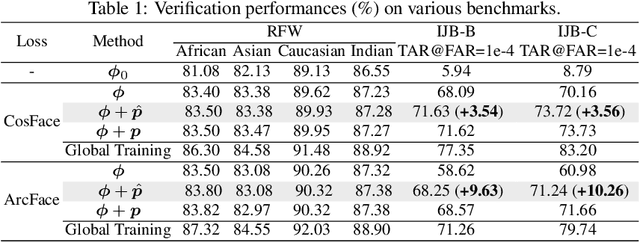
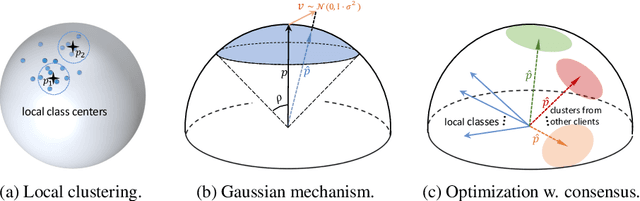
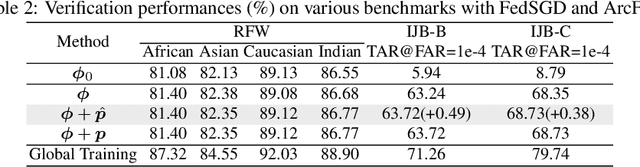
The growing public concerns on data privacy in face recognition can be greatly addressed by the federated learning (FL) paradigm. However, conventional FL methods perform poorly due to the uniqueness of the task: broadcasting class centers among clients is crucial for recognition performances but leads to privacy leakage. To resolve the privacy-utility paradox, this work proposes PrivacyFace, a framework largely improves the federated learning face recognition via communicating auxiliary and privacy-agnostic information among clients. PrivacyFace mainly consists of two components: First, a practical Differentially Private Local Clustering (DPLC) mechanism is proposed to distill sanitized clusters from local class centers. Second, a consensus-aware recognition loss subsequently encourages global consensuses among clients, which ergo results in more discriminative features. The proposed framework is mathematically proved to be differentially private, introducing a lightweight overhead as well as yielding prominent performance boosts (\textit{e.g.}, +9.63\% and +10.26\% for TAR@FAR=1e-4 on IJB-B and IJB-C respectively). Extensive experiments and ablation studies on a large-scale dataset have demonstrated the efficacy and practicability of our method.