 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Federated Learning Face Recognition via Privacy-Agnostic Clusters
Jan 29, 2022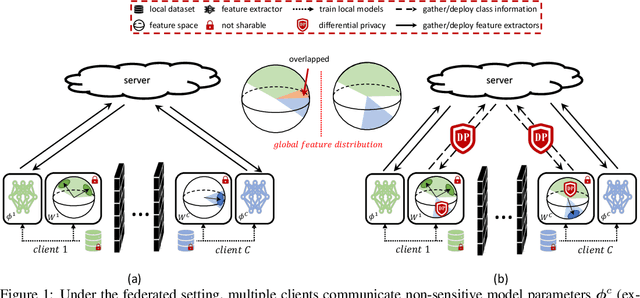
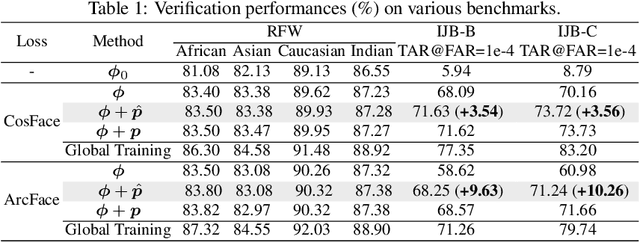
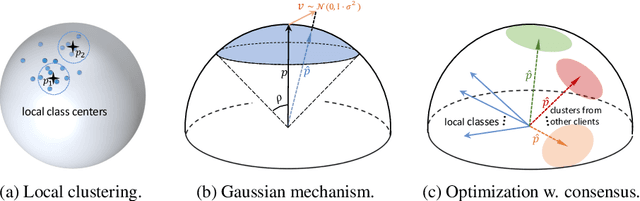
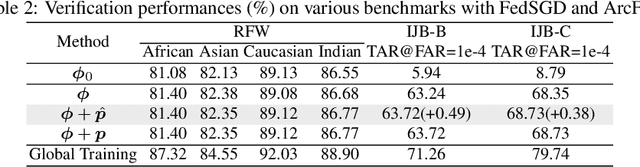
The growing public concerns on data privacy in face recognition can be greatly addressed by the federated learning (FL) paradigm. However, conventional FL methods perform poorly due to the uniqueness of the task: broadcasting class centers among clients is crucial for recognition performances but leads to privacy leakage. To resolve the privacy-utility paradox, this work proposes PrivacyFace, a framework largely improves the federated learning face recognition via communicating auxiliary and privacy-agnostic information among clients. PrivacyFace mainly consists of two components: First, a practical Differentially Private Local Clustering (DPLC) mechanism is proposed to distill sanitized clusters from local class centers. Second, a consensus-aware recognition loss subsequently encourages global consensuses among clients, which ergo results in more discriminative features. The proposed framework is mathematically proved to be differentially private, introducing a lightweight overhead as well as yielding prominent performance boosts (\textit{e.g.}, +9.63\% and +10.26\% for TAR@FAR=1e-4 on IJB-B and IJB-C respectively). Extensive experiments and ablation studies on a large-scale dataset have demonstrated the efficacy and practicability of our method.
DeLS-3D: Deep Localization and Segmentation with a 3D Semantic Map
May 13, 2018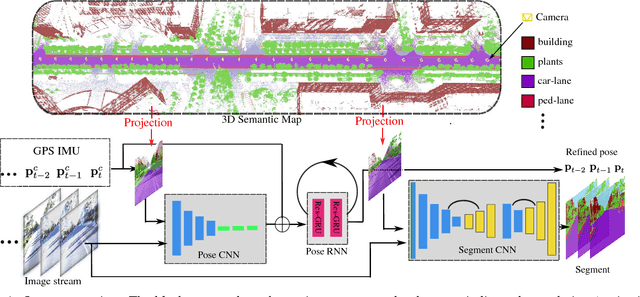

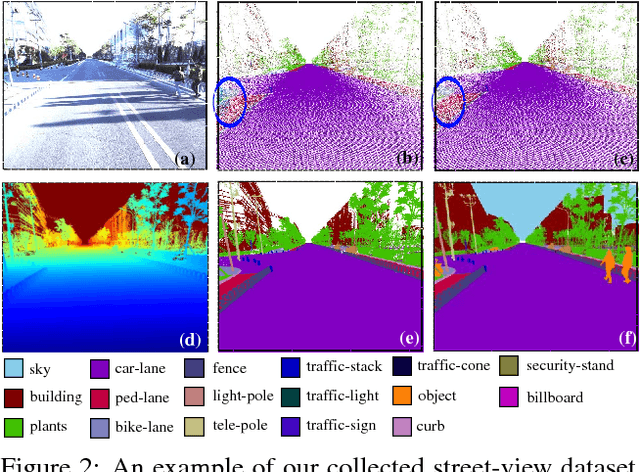

For applications such as autonomous driving, self-localization/camera pose estimation and scene parsing are crucial technologies. In this paper, we propose a unified framework to tackle these two problems simultaneously. The uniqueness of our design is a sensor fusion scheme which integrates camera videos, motion sensors (GPS/IMU), and a 3D semantic map in order to achieve robustness and efficiency of the system. Specifically, we first have an initial coarse camera pose obtained from consumer-grade GPS/IMU, based on which a label map can be rendered from the 3D semantic map. Then, the rendered label map and the RGB image are jointly fed into a pose CNN, yielding a corrected camera pose. In addition, to incorporate temporal information, a multi-layer recurrent neural network (RNN) is further deployed improve the pose accuracy. Finally, based on the pose from RNN, we render a new label map, which is fed together with the RGB image into a segment CNN which produces per-pixel semantic label. In order to validate our approach, we build a dataset with registered 3D point clouds and video camera images. Both the point clouds and the images are semantically-labeled. Each video frame has ground truth pose from highly accurate motion sensors. We show that practically, pose estimation solely relying on images like PoseNet may fail due to street view confusion, and it is important to fuse multiple sensors. Finally, various ablation studies are performed, which demonstrate the effectiveness of the proposed system. In particular, we show that scene parsing and pose estimation are mutually beneficial to achieve a more robust and accurate system.
Revisiting the Effectiveness of Off-the-shelf Temporal Modeling Approaches for Large-scale Video Classification
Aug 12, 2017
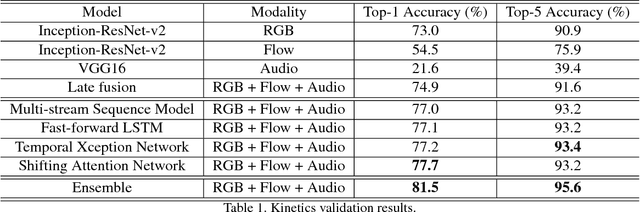
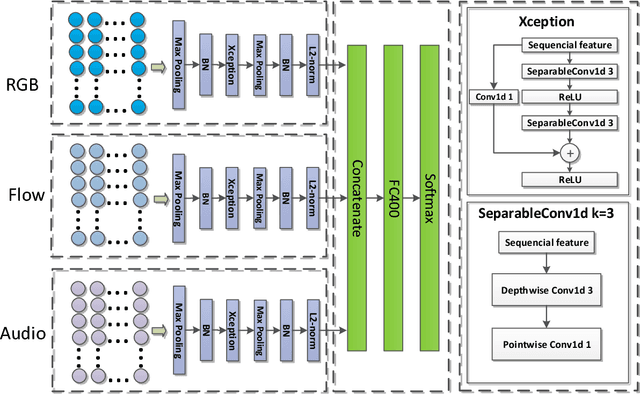
This paper describes our solution for the video recognition task of ActivityNet Kinetics challenge that ranked the 1st place. Most of existing state-of-the-art video recognition approaches are in favor of an end-to-end pipeline. One exception is the framework of DevNet. The merit of DevNet is that they first use the video data to learn a network (i.e. fine-tuning or training from scratch). Instead of directly using the end-to-end classification scores (e.g. softmax scores), they extract the features from the learned network and then fed them into the off-the-shelf machine learning models to conduct video classification. However, the effectiveness of this line work has long-term been ignored and underestimated. In this submission, we extensively use this strategy. Particularly, we investigate four temporal modeling approaches using the learned features: Multi-group Shifting Attention Network, Temporal Xception Network, Multi-stream sequence Model and Fast-Forward Sequence Model. Experiment results on the challenging Kinetics dataset demonstrate that our proposed temporal modeling approaches can significantly improve existing approaches in the large-scale video recognition tasks. Most remarkably, our best single Multi-group Shifting Attention Network can achieve 77.7% in term of top-1 accuracy and 93.2% in term of top-5 accuracy on the validation set.
Deep Metric Learning with Angular Loss
Aug 04, 2017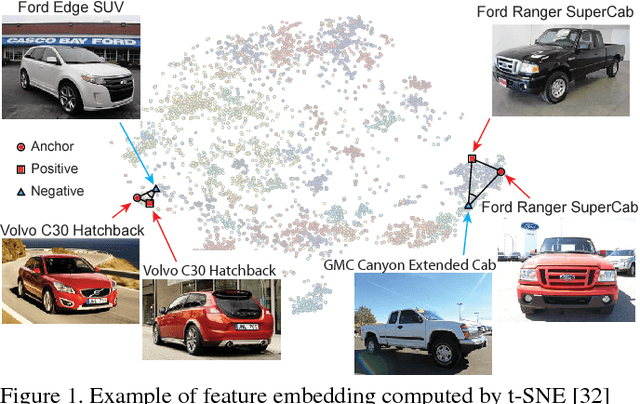



The modern image search system requires semantic understanding of image, and a key yet under-addressed problem is to learn a good metric for measuring the similarity between images. While deep metric learning has yielded impressive performance gains by extracting high level abstractions from image data, a proper objective loss function becomes the central issue to boost the performance. In this paper, we propose a novel angular loss, which takes angle relationship into account, for learning better similarity metric. Whereas previous metric learning methods focus on optimizing the similarity (contrastive loss) or relative similarity (triplet loss) of image pairs, our proposed method aims at constraining the angle at the negative point of triplet triangles. Several favorable properties are observed when compared with conventional methods. First, scale invariance is introduced, improving the robustness of objective against feature variance. Second, a third-order geometric constraint is inherently imposed, capturing additional local structure of triplet triangles than contrastive loss or triplet loss. Third, better convergence has been demonstrated by experiments on three publicly available datasets.
Fully Convolutional Attention Networks for Fine-Grained Recognition
Mar 21, 2017



Fine-grained recognition is challenging due to its subtle local inter-class differences versus large intra-class variations such as poses. A key to address this problem is to localize discriminative parts to extract pose-invariant features. However, ground-truth part annotations can be expensive to acquire. Moreover, it is hard to define parts for many fine-grained classes. This work introduces Fully Convolutional Attention Networks (FCANs), a reinforcement learning framework to optimally glimpse local discriminative regions adaptive to different fine-grained domains. Compared to previous methods, our approach enjoys three advantages: 1) the weakly-supervised reinforcement learning procedure requires no expensive part annotations; 2) the fully-convolutional architecture speeds up both training and testing; 3) the greedy reward strategy accelerates the convergence of the learning. We demonstrate the effectiveness of our method with extensive experiments on four challenging fine-grained benchmark datasets, including CUB-200-2011, Stanford Dogs, Stanford Cars and Food-101.
Subcategory-aware Convolutional Neural Networks for Object Proposals and Detection
Mar 09, 2017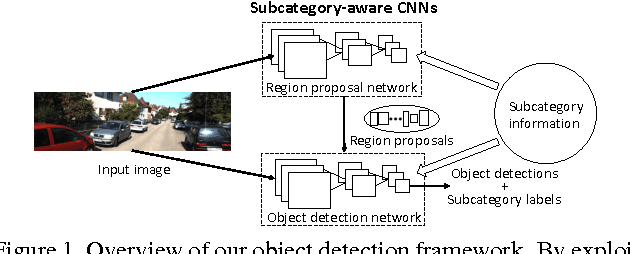


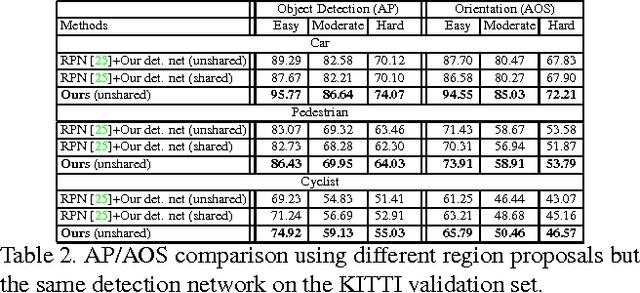
In CNN-based object detection methods, region proposal becomes a bottleneck when objects exhibit significant scale variation, occlusion or truncation. In addition, these methods mainly focus on 2D object detection and cannot estimate detailed properties of objects. In this paper, we propose subcategory-aware CNNs for object detection. We introduce a novel region proposal network that uses subcategory information to guide the proposal generating process, and a new detection network for joint detection and subcategory classification. By using subcategories related to object pose, we achieve state-of-the-art performance on both detection and pose estimation on commonly used benchmarks.
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition
May 23, 2016
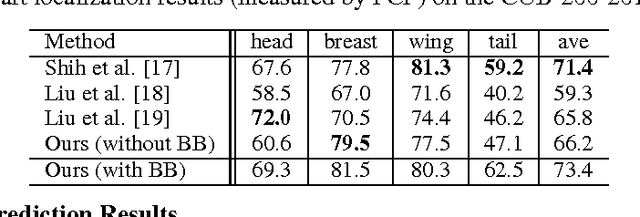
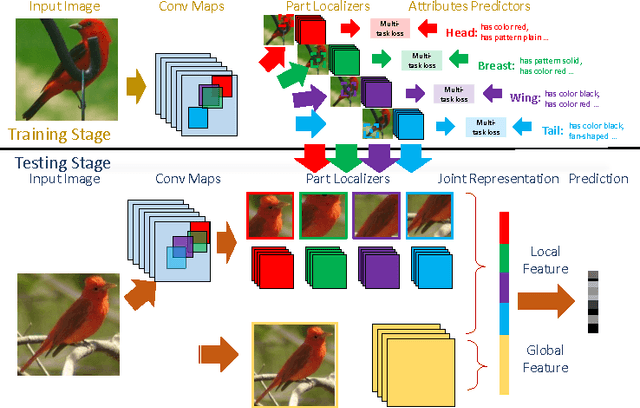
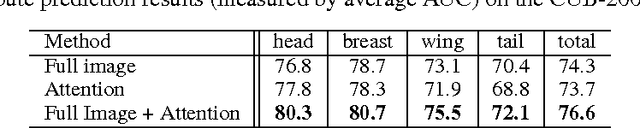
A key challenge in fine-grained recognition is how to find and represent discriminative local regions. Recent attention models are capable of learning discriminative region localizers only from category labels with reinforcement learning. However, not utilizing any explicit part information, they are not able to accurately find multiple distinctive regions. In this work, we introduce an attribute-guided attention localization scheme where the local region localizers are learned under the guidance of part attribute descriptions. By designing a novel reward strategy, we are able to learn to locate regions that are spatially and semantically distinctive with reinforcement learning algorithm. The attribute labeling requirement of the scheme is more amenable than the accurate part location annotation required by traditional part-based fine-grained recognition methods. Experimental results on the CUB-200-2011 dataset demonstrate the superiority of the proposed scheme on both fine-grained recognition and attribute recognition.
Fine-grained Categorization and Dataset Bootstrapping using Deep Metric Learning with Humans in the Loop
Apr 11, 2016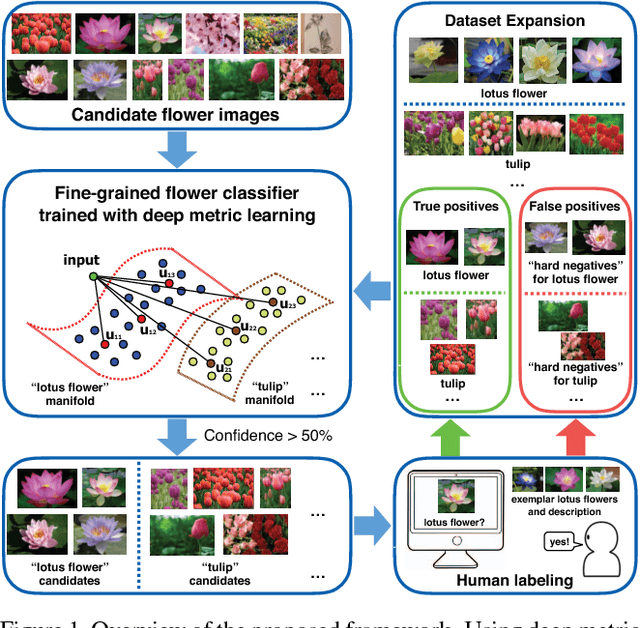


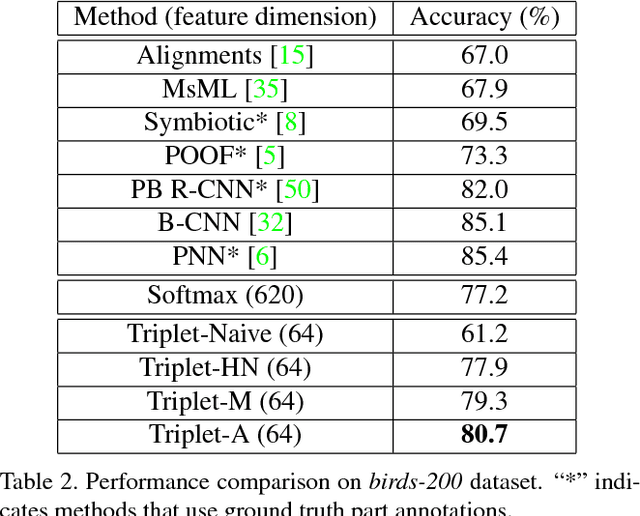
Existing fine-grained visual categorization methods often suffer from three challenges: lack of training data, large number of fine-grained categories, and high intraclass vs. low inter-class variance. In this work we propose a generic iterative framework for fine-grained categorization and dataset bootstrapping that handles these three challenges. Using deep metric learning with humans in the loop, we learn a low dimensional feature embedding with anchor points on manifolds for each category. These anchor points capture intra-class variances and remain discriminative between classes. In each round, images with high confidence scores from our model are sent to humans for labeling. By comparing with exemplar images, labelers mark each candidate image as either a "true positive" or a "false positive". True positives are added into our current dataset and false positives are regarded as "hard negatives" for our metric learning model. Then the model is retrained with an expanded dataset and hard negatives for the next round. To demonstrate the effectiveness of the proposed framework, we bootstrap a fine-grained flower dataset with 620 categories from Instagram images. The proposed deep metric learning scheme is evaluated on both our dataset and the CUB-200-2001 Birds dataset. Experimental evaluations show significant performance gain using dataset bootstrapping and demonstrate state-of-the-art results achieved by the proposed deep metric learning methods.
Embedding Label Structures for Fine-Grained Feature Representation
Mar 11, 2016
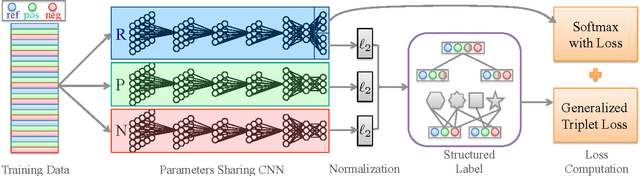


Recent algorithms in convolutional neural networks (CNN) considerably advance the fine-grained image classification, which aims to differentiate subtle differences among subordinate classes. However, previous studies have rarely focused on learning a fined-grained and structured feature representation that is able to locate similar images at different levels of relevance, e.g., discovering cars from the same make or the same model, both of which require high precision. In this paper, we propose two main contributions to tackle this problem. 1) A multi-task learning framework is designed to effectively learn fine-grained feature representations by jointly optimizing both classification and similarity constraints. 2) To model the multi-level relevance, label structures such as hierarchy or shared attributes are seamlessly embedded into the framework by generalizing the triplet loss. Extensive and thorough experiments have been conducted on three fine-grained datasets, i.e., the Stanford car, the car-333, and the food datasets, which contain either hierarchical labels or shared attributes. Our proposed method has achieved very competitive performance, i.e., among state-of-the-art classification accuracy. More importantly, it significantly outperforms previous fine-grained feature representations for image retrieval at different levels of relevance.
Fine-grained Image Classification by Exploring Bipartite-Graph Labels
Dec 10, 2015
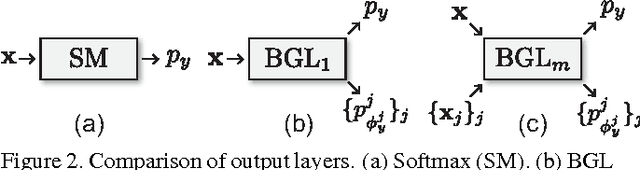

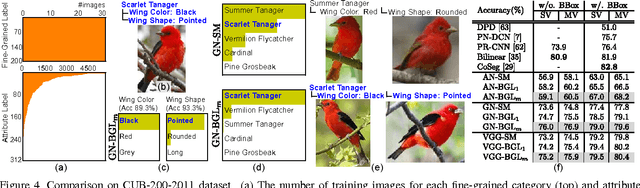
Given a food image, can a fine-grained object recognition engine tell "which restaurant which dish" the food belongs to? Such ultra-fine grained image recognition is the key for many applications like search by images, but it is very challenging because it needs to discern subtle difference between classes while dealing with the scarcity of training data. Fortunately, the ultra-fine granularity naturally brings rich relationships among object classes. This paper proposes a novel approach to exploit the rich relationships through bipartite-graph labels (BGL). We show how to model BGL in an overall convolutional neural networks and the resulting system can be optimized through back-propagation. We also show that it is computationally efficient in inference thanks to the bipartite structure. To facilitate the study, we construct a new food benchmark dataset, which consists of 37,885 food images collected from 6 restaurants and totally 975 menus. Experimental results on this new food and three other datasets demonstrates BGL advances previous works in fine-grained object recognition. An online demo is available at http://www.f-zhou.com/fg_demo/.