 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization for AI-Synthesized Voice Detection
Dec 26, 2024AI-synthesized voice technology has the potential to create realistic human voices for beneficial applications, but it can also be misused for malicious purposes. While existing AI-synthesized voice detection models excel in intra-domain evaluation, they face challenges in generalizing across different domains, potentially becoming obsolete as new voice generators emerge. Current solutions use diverse data and advanced machine learning techniques (e.g., domain-invariant representation, self-supervised learning), but are limited by predefined vocoders and sensitivity to factors like background noise and speaker identity. In this work, we introduce an innovative disentanglement framework aimed at extracting domain-agnostic artifact features related to vocoders. Utilizing these features, we enhance model learning in a flat loss landscape, enabling escape from suboptimal solutions and improving generalization. Extensive experiments on benchmarks show our approach outperforms state-of-the-art methods, achieving up to 5.12% improvement in the equal error rate metric in intra-domain and 7.59% in cross-domain evaluations.
Detecting Multimedia Generated by Large AI Models: A Survey
Feb 07, 2024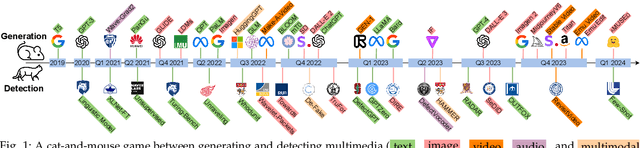
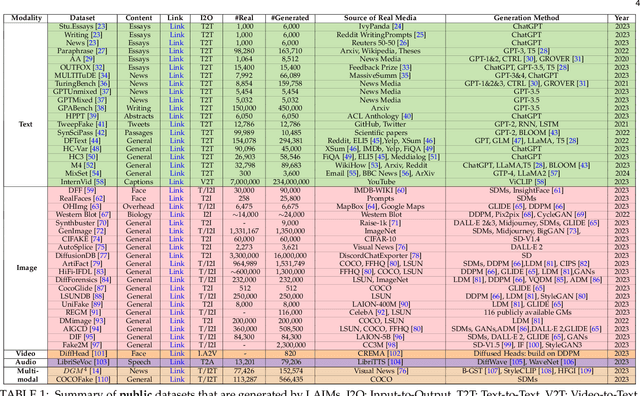
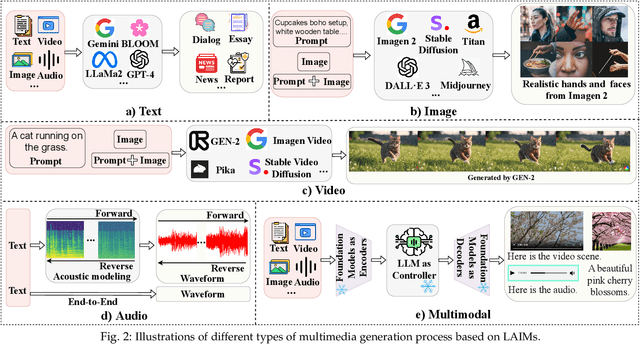
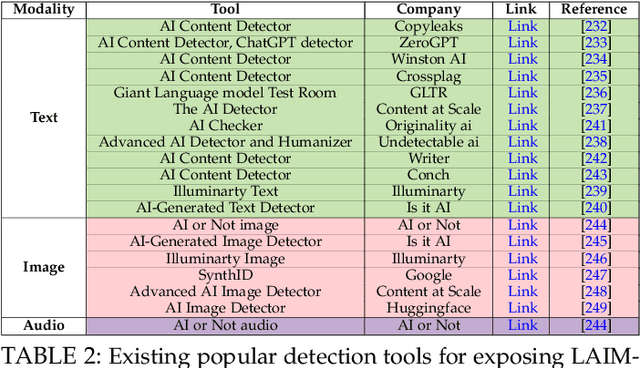
The rapid advancement of Large AI Models (LAIMs), particularly diffusion models and large language models, has marked a new era where AI-generated multimedia is increasingly integrated into various aspects of daily life. Although beneficial in numerous fields, this content presents significant risks, including potential misuse, societal disruptions, and ethical concerns. Consequently, detecting multimedia generated by LAIMs has become crucial, with a marked rise in related research. Despite this, there remains a notable gap in systematic surveys that focus specifically on detecting LAIM-generated multimedia. Addressing this, we provide the first survey to comprehensively cover existing research on detecting multimedia (such as text, images, videos, audio, and multimodal content) created by LAIMs. Specifically, we introduce a novel taxonomy for detection methods, categorized by media modality, and aligned with two perspectives: pure detection (aiming to enhance detection performance) and beyond detection (adding attributes like generalizability, robustness, and interpretability to detectors). Additionally, we have presented a brief overview of generation mechanisms, public datasets, and online detection tools to provide a valuable resource for researchers and practitioners in this field. Furthermore, we identify current challenges in detection and propose directions for future research that address unexplored, ongoing, and emerging issues in detecting multimedia generated by LAIMs. Our aim for this survey is to fill an academic gap and contribute to global AI security efforts, helping to ensure the integrity of information in the digital realm. The project link is https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey.
Improving Federated Learning Face Recognition via Privacy-Agnostic Clusters
Jan 29, 2022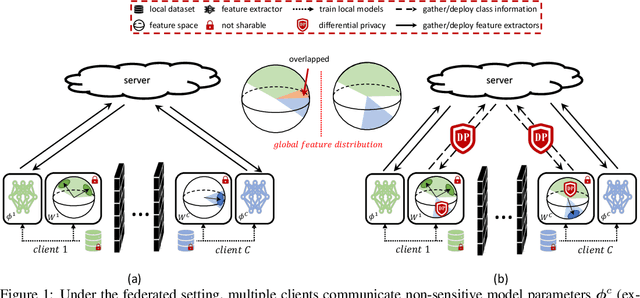
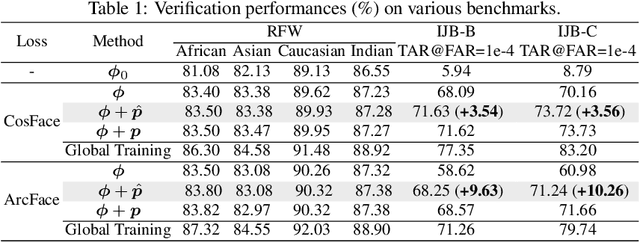
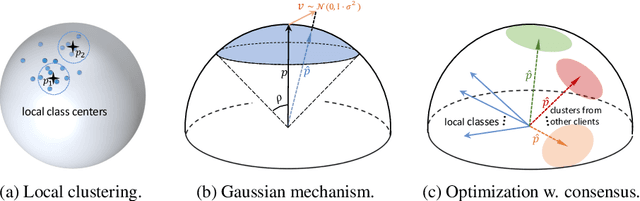
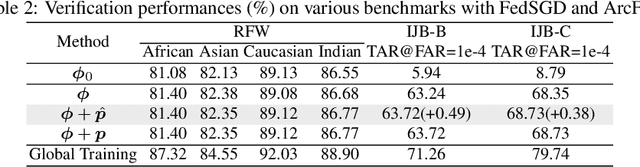
The growing public concerns on data privacy in face recognition can be greatly addressed by the federated learning (FL) paradigm. However, conventional FL methods perform poorly due to the uniqueness of the task: broadcasting class centers among clients is crucial for recognition performances but leads to privacy leakage. To resolve the privacy-utility paradox, this work proposes PrivacyFace, a framework largely improves the federated learning face recognition via communicating auxiliary and privacy-agnostic information among clients. PrivacyFace mainly consists of two components: First, a practical Differentially Private Local Clustering (DPLC) mechanism is proposed to distill sanitized clusters from local class centers. Second, a consensus-aware recognition loss subsequently encourages global consensuses among clients, which ergo results in more discriminative features. The proposed framework is mathematically proved to be differentially private, introducing a lightweight overhead as well as yielding prominent performance boosts (\textit{e.g.}, +9.63\% and +10.26\% for TAR@FAR=1e-4 on IJB-B and IJB-C respectively). Extensive experiments and ablation studies on a large-scale dataset have demonstrated the efficacy and practicability of our method.