 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Effectiveness of Off-the-shelf Temporal Modeling Approaches for Large-scale Video Classification
Aug 12, 2017
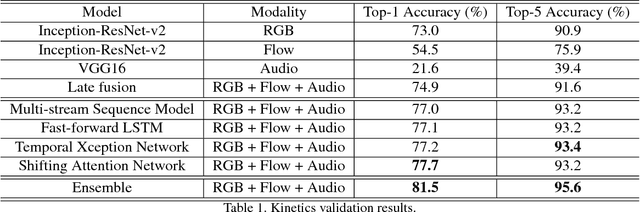
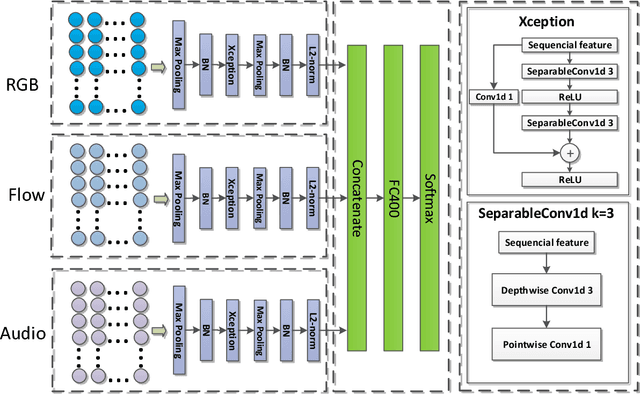
This paper describes our solution for the video recognition task of ActivityNet Kinetics challenge that ranked the 1st place. Most of existing state-of-the-art video recognition approaches are in favor of an end-to-end pipeline. One exception is the framework of DevNet. The merit of DevNet is that they first use the video data to learn a network (i.e. fine-tuning or training from scratch). Instead of directly using the end-to-end classification scores (e.g. softmax scores), they extract the features from the learned network and then fed them into the off-the-shelf machine learning models to conduct video classification. However, the effectiveness of this line work has long-term been ignored and underestimated. In this submission, we extensively use this strategy. Particularly, we investigate four temporal modeling approaches using the learned features: Multi-group Shifting Attention Network, Temporal Xception Network, Multi-stream sequence Model and Fast-Forward Sequence Model. Experiment results on the challenging Kinetics dataset demonstrate that our proposed temporal modeling approaches can significantly improve existing approaches in the large-scale video recognition tasks. Most remarkably, our best single Multi-group Shifting Attention Network can achieve 77.7% in term of top-1 accuracy and 93.2% in term of top-5 accuracy on the validation set.
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding
Jul 14, 2017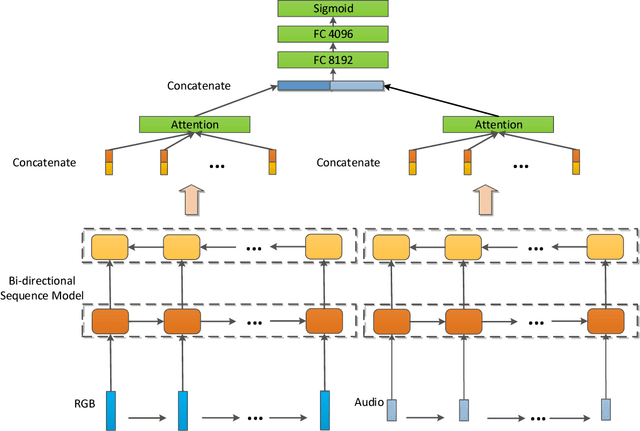
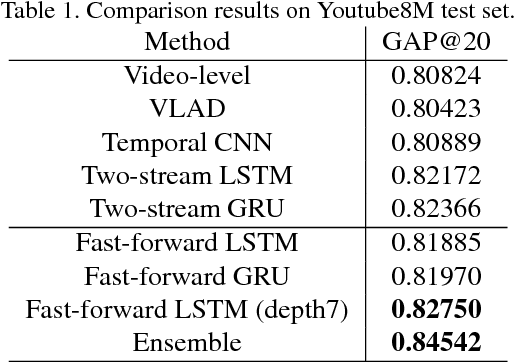
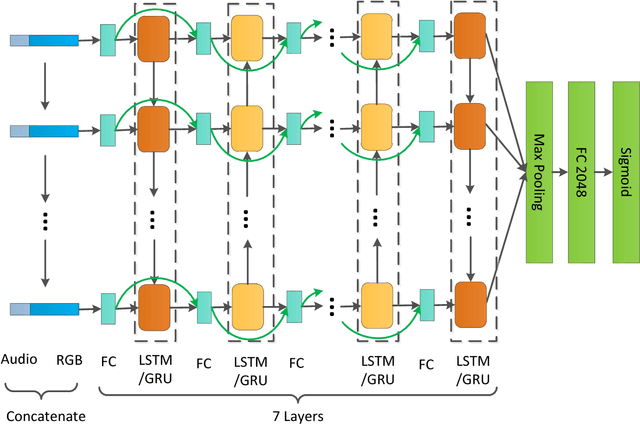
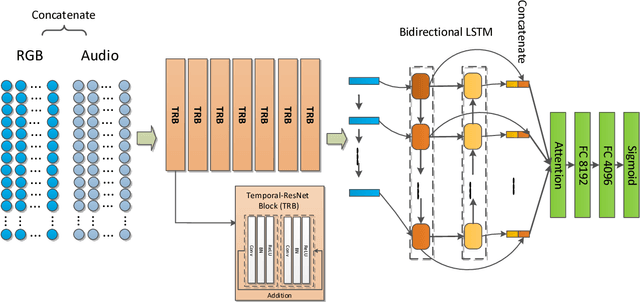
This paper describes our solution for the video recognition task of the Google Cloud and YouTube-8M Video Understanding Challenge that ranked the 3rd place. Because the challenge provides pre-extracted visual and audio features instead of the raw videos, we mainly investigate various temporal modeling approaches to aggregate the frame-level features for multi-label video recognition. Our system contains three major components: two-stream sequence model, fast-forward sequence model and temporal residual neural networks. Experiment results on the challenging Youtube-8M dataset demonstrate that our proposed temporal modeling approaches can significantly improve existing temporal modeling approaches in the large-scale video recognition tasks. To be noted, our fast-forward LSTM with a depth of 7 layers achieves 82.75% in term of GAP@20 on the Kaggle Public test set.