 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Modeling Approaches for Large-scale Youtube-8M Video Understanding
Paper and Code
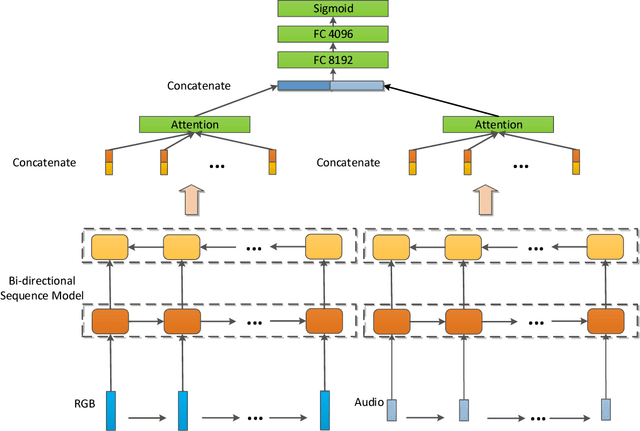
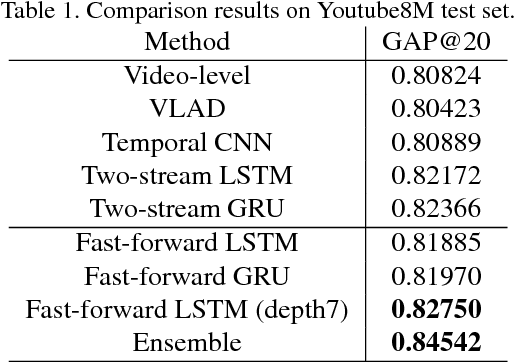
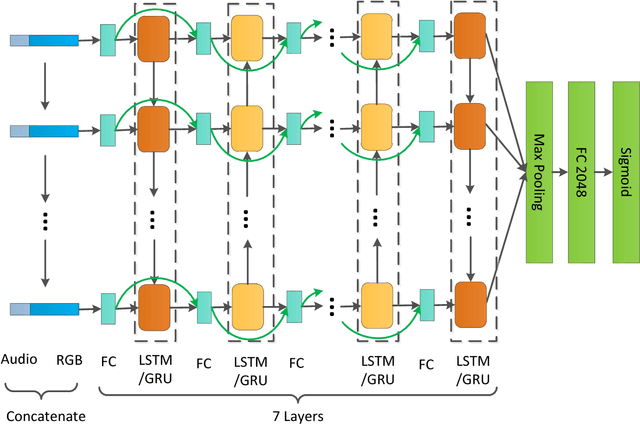
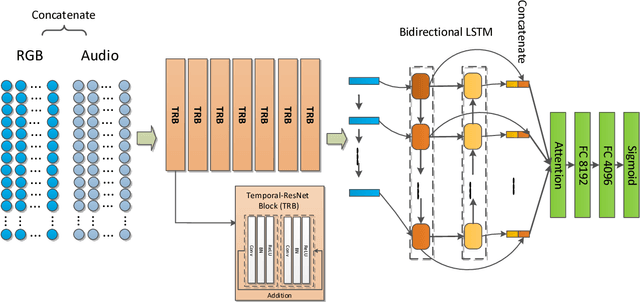
This paper describes our solution for the video recognition task of the Google Cloud and YouTube-8M Video Understanding Challenge that ranked the 3rd place. Because the challenge provides pre-extracted visual and audio features instead of the raw videos, we mainly investigate various temporal modeling approaches to aggregate the frame-level features for multi-label video recognition. Our system contains three major components: two-stream sequence model, fast-forward sequence model and temporal residual neural networks. Experiment results on the challenging Youtube-8M dataset demonstrate that our proposed temporal modeling approaches can significantly improve existing temporal modeling approaches in the large-scale video recognition tasks. To be noted, our fast-forward LSTM with a depth of 7 layers achieves 82.75% in term of GAP@20 on the Kaggle Public test set.