 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Baseline Shapley and Integrated Gradients for Local Explanation: Some Additional Insights
Aug 12, 2022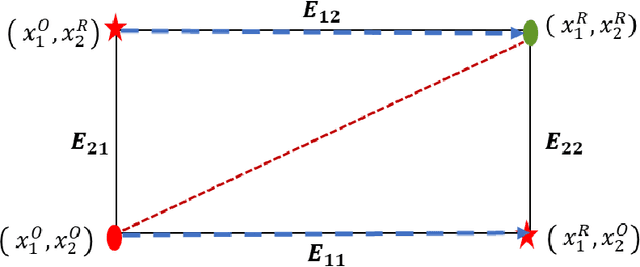
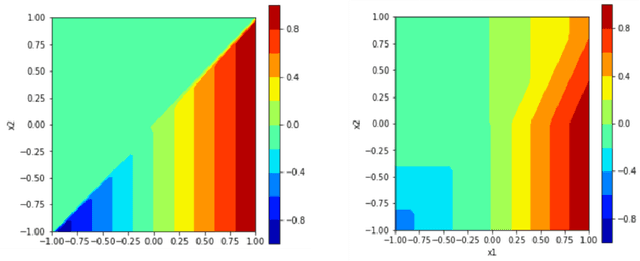

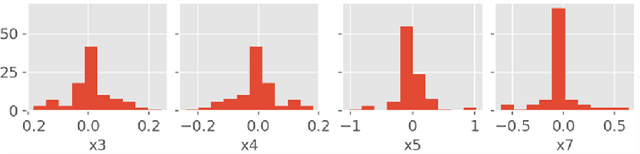
There are many different methods in the literature for local explanation of machine learning results. However, the methods differ in their approaches and often do not provide same explanations. In this paper, we consider two recent methods: Integrated Gradients (Sundararajan, Taly, & Yan, 2017) and Baseline Shapley (Sundararajan and Najmi, 2020). The original authors have already studied the axiomatic properties of the two methods and provided some comparisons. Our work provides some additional insights on their comparative behavior for tabular data. We discuss common situations where the two provide identical explanations and where they differ. We also use simulation studies to examine the differences when neural networks with ReLU activation function is used to fit the models.