 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModuSeg: Decoupling Object Discovery and Semantic Retrieval for Training-Free Weakly Supervised Segmentation
Apr 08, 2026Weakly supervised semantic segmentation aims to achieve pixel-level predictions using image-level labels. Existing methods typically entangle semantic recognition and object localization, which often leads models to focus exclusively on sparse discriminative regions. Although foundation models show immense potential, many approaches still follow the tightly coupled optimization paradigm, struggling to effectively alleviate pseudo-label noise and often relying on time-consuming multi-stage retraining or unstable end-to-end joint optimization. To address the above challenges, we present ModuSeg, a training-free weakly supervised semantic segmentation framework centered on explicitly decoupling object discovery and semantic assignment. Specifically, we integrate a general mask proposer to extract geometric proposals with reliable boundaries, while leveraging semantic foundation models to construct an offline feature bank, transforming segmentation into a non-parametric feature retrieval process. Furthermore, we propose semantic boundary purification and soft-masked feature aggregation strategies to effectively mitigate boundary ambiguity and quantization errors, thereby extracting high-quality category prototypes. Extensive experiments demonstrate that the proposed decoupled architecture better preserves fine boundaries without parameter fine-tuning and achieves highly competitive performance on standard benchmark datasets. Code is available at https://github.com/Autumnair007/ModuSeg.
Reconstructing Spiking Neural Networks Using a Single Neuron with Autapses
Mar 25, 2026Spiking neural networks (SNNs) are promising for neuromorphic computing, but high-performing models still rely on dense multilayer architectures with substantial communication and state-storage costs. Inspired by autapses, we propose time-delayed autapse SNN (TDA-SNN), a framework that reconstructs SNNs with a single leaky integrate-and-fire neuron and a prototype-learning-based training strategy. By reorganizing internal temporal states, TDA-SNN can realize reservoir, multilayer perceptron, and convolution-like spiking architectures within a unified framework. Experiments on sequential, event-based, and image benchmarks show competitive performance in reservoir and MLP settings, while convolutional results reveal a clear space--time trade-off. Compared with standard SNNs, TDA-SNN greatly reduces neuron count and state memory while increasing per-neuron information capacity, at the cost of additional temporal latency in extreme single-neuron settings. These findings highlight the potential of temporally multiplexed single-neuron models as compact computational units for brain-inspired computing.
Exploring Token-Level Augmentation in Vision Transformer for Semi-Supervised Semantic Segmentation
Mar 04, 2025Semi-supervised semantic segmentation has witnessed remarkable advancements in recent years. However, existing algorithms are based on convolutional neural networks and directly applying them to Vision Transformers poses certain limitations due to conceptual disparities. To this end, we propose TokenMix, a data augmentation technique specifically designed for semi-supervised semantic segmentation with Vision Transformers. TokenMix aligns well with the global attention mechanism by mixing images at the token level, enhancing learning capability for contexutual information among image patches. We further incorporate image augmentation and feature augmentation to promote the diversity of augmentation. Moreover, to enhance consistency regularization, we propose a dual-branch framework where each branch applies both image augmentation and feature augmentation to the input image. We conduct extensive experiments across multiple benchmark datasets, including Pascal VOC 2012, Cityscapes, and COCO. Results suggest that the proposed method outperforms state-of-the-art algorithms with notably observed accuracy improvement, especially under the circumstance of limited fine annotations.
CorrCLIP: Reconstructing Correlations in CLIP with Off-the-Shelf Foundation Models for Open-Vocabulary Semantic Segmentation
Nov 15, 2024Open-vocabulary semantic segmentation aims to assign semantic labels to each pixel without relying on a predefined set of categories. Contrastive Language-Image Pre-training (CLIP) demonstrates outstanding zero-shot classification capabilities but struggles with the pixel-wise segmentation task as the captured inter-patch correlations correspond to no specific visual concepts. Despite previous CLIP-based works improving inter-patch correlations by self-self attention, they still face the inherent limitation that image patches tend to have high similarity to outlier ones. In this work, we introduce CorrCLIP, a training-free approach for open-vocabulary semantic segmentation, which reconstructs significantly coherent inter-patch correlations utilizing foundation models. Specifically, it employs the Segment Anything Model (SAM) to define the scope of patch interactions, ensuring that patches interact only with semantically similar ones. Furthermore, CorrCLIP obtains an understanding of an image's semantic layout via self-supervised models to determine concrete similarity values between image patches, which addresses the similarity irregularity problem caused by the aforementioned restricted patch interaction regime. Finally, CorrCLIP reuses the region masks produced by SAM to update the segmentation map. As a training-free method, CorrCLIP achieves a notable improvement across eight challenging benchmarks regarding the averaged mean Intersection over Union, boosting it from 44.4% to 51.0%.
EK-Net:Real-time Scene Text Detection with Expand Kernel Distance
Jan 22, 2024



Recently, scene text detection has received significant attention due to its wide application. However, accurate detection in complex scenes of multiple scales, orientations, and curvature remains a challenge. Numerous detection methods adopt the Vatti clipping (VC) algorithm for multiple-instance training to address the issue of arbitrary-shaped text. Yet we identify several bias results from these approaches called the "shrinked kernel". Specifically, it refers to a decrease in accuracy resulting from an output that overly favors the text kernel. In this paper, we propose a new approach named Expand Kernel Network (EK-Net) with expand kernel distance to compensate for the previous deficiency, which includes three-stages regression to complete instance detection. Moreover, EK-Net not only realize the precise positioning of arbitrary-shaped text, but also achieve a trade-off between performance and speed. Evaluation results demonstrate that EK-Net achieves state-of-the-art or competitive performance compared to other advanced methods, e.g., F-measure of 85.72% at 35.42 FPS on ICDAR 2015, F-measure of 85.75% at 40.13 FPS on CTW1500.
Boosting Semantic Segmentation from the Perspective of Explicit Class Embeddings
Aug 24, 2023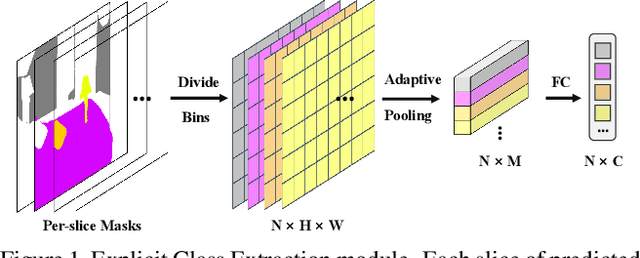
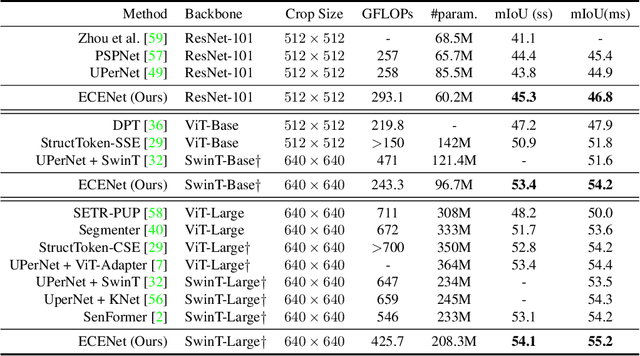
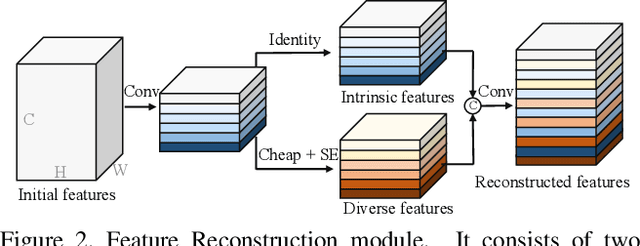
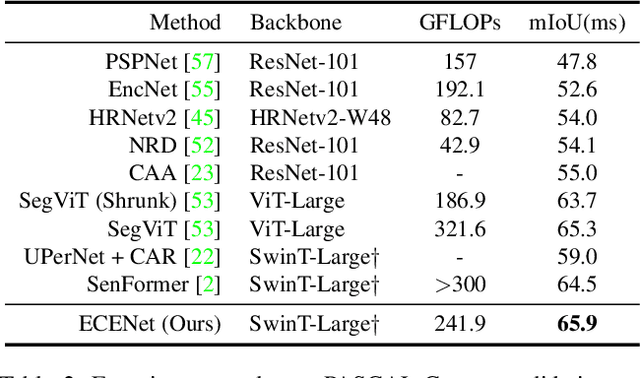
Semantic segmentation is a computer vision task that associates a label with each pixel in an image. Modern approaches tend to introduce class embeddings into semantic segmentation for deeply utilizing category semantics, and regard supervised class masks as final predictions. In this paper, we explore the mechanism of class embeddings and have an insight that more explicit and meaningful class embeddings can be generated based on class masks purposely. Following this observation, we propose ECENet, a new segmentation paradigm, in which class embeddings are obtained and enhanced explicitly during interacting with multi-stage image features. Based on this, we revisit the traditional decoding process and explore inverted information flow between segmentation masks and class embeddings. Furthermore, to ensure the discriminability and informativity of features from backbone, we propose a Feature Reconstruction module, which combines intrinsic and diverse branches together to ensure the concurrence of diversity and redundancy in features. Experiments show that our ECENet outperforms its counterparts on the ADE20K dataset with much less computational cost and achieves new state-of-the-art results on PASCAL-Context dataset. The code will be released at https://gitee.com/mindspore/models and https://github.com/Carol-lyh/ECENet.
Category Feature Transformer for Semantic Segmentation
Aug 10, 2023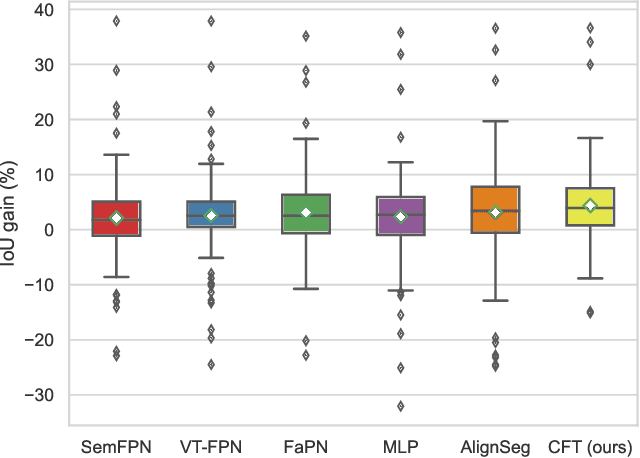
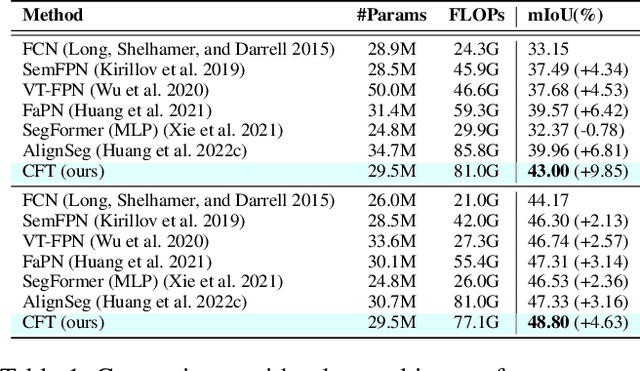
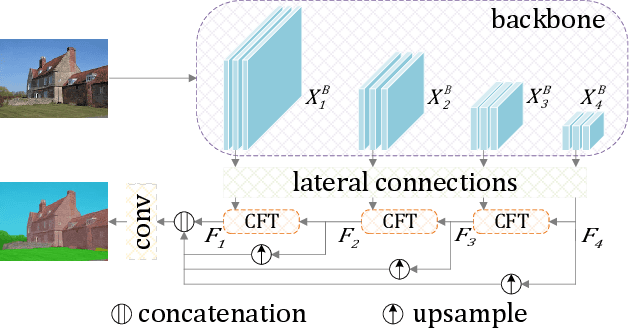
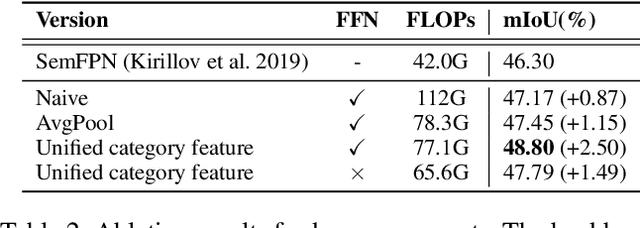
Aggregation of multi-stage features has been revealed to play a significant role in semantic segmentation. Unlike previous methods employing point-wise summation or concatenation for feature aggregation, this study proposes the Category Feature Transformer (CFT) that explores the flow of category embedding and transformation among multi-stage features through the prevalent multi-head attention mechanism. CFT learns unified feature embeddings for individual semantic categories from high-level features during each aggregation process and dynamically broadcasts them to high-resolution features. Integrating the proposed CFT into a typical feature pyramid structure exhibits superior performance over a broad range of backbone networks. We conduct extensive experiments on popular semantic segmentation benchmarks. Specifically, the proposed CFT obtains a compelling 55.1% mIoU with greatly reduced model parameters and computations on the challenging ADE20K dataset.
Dynamic Token Pruning in Plain Vision Transformers for Semantic Segmentation
Aug 02, 2023



Vision transformers have achieved leading performance on various visual tasks yet still suffer from high computational complexity. The situation deteriorates in dense prediction tasks like semantic segmentation, as high-resolution inputs and outputs usually imply more tokens involved in computations. Directly removing the less attentive tokens has been discussed for the image classification task but can not be extended to semantic segmentation since a dense prediction is required for every patch. To this end, this work introduces a Dynamic Token Pruning (DToP) method based on the early exit of tokens for semantic segmentation. Motivated by the coarse-to-fine segmentation process by humans, we naturally split the widely adopted auxiliary-loss-based network architecture into several stages, where each auxiliary block grades every token's difficulty level. We can finalize the prediction of easy tokens in advance without completing the entire forward pass. Moreover, we keep $k$ highest confidence tokens for each semantic category to uphold the representative context information. Thus, computational complexity will change with the difficulty of the input, akin to the way humans do segmentation. Experiments suggest that the proposed DToP architecture reduces on average $20\% - 35\%$ of computational cost for current semantic segmentation methods based on plain vision transformers without accuracy degradation.
SegViT: Semantic Segmentation with Plain Vision Transformers
Oct 12, 2022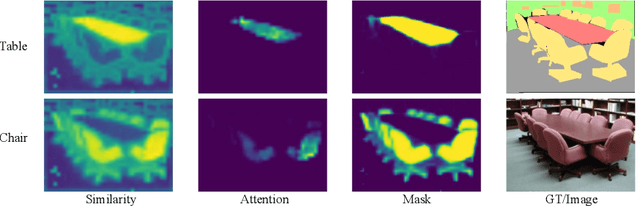
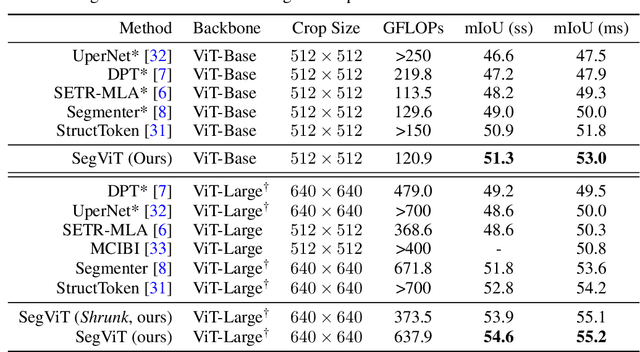
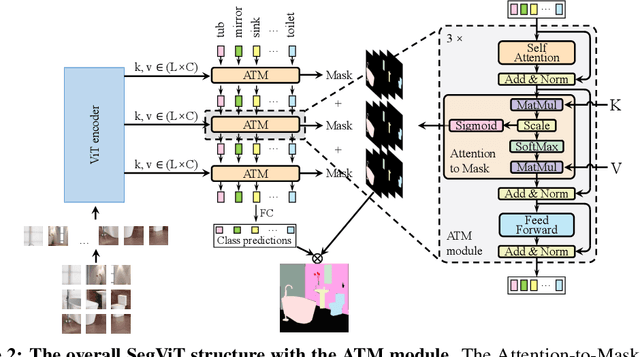
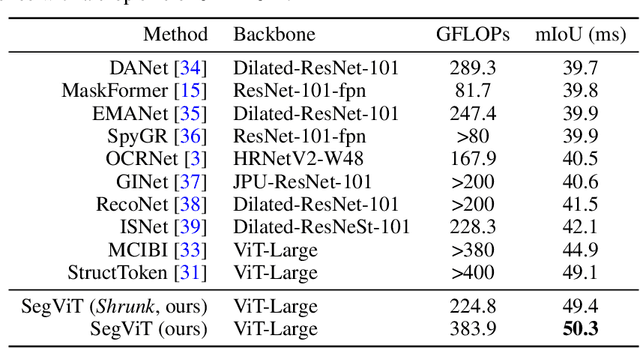
We explore the capability of plain Vision Transformers (ViTs) for semantic segmentation and propose the SegVit. Previous ViT-based segmentation networks usually learn a pixel-level representation from the output of the ViT. Differently, we make use of the fundamental component -- attention mechanism, to generate masks for semantic segmentation. Specifically, we propose the Attention-to-Mask (ATM) module, in which the similarity maps between a set of learnable class tokens and the spatial feature maps are transferred to the segmentation masks. Experiments show that our proposed SegVit using the ATM module outperforms its counterparts using the plain ViT backbone on the ADE20K dataset and achieves new state-of-the-art performance on COCO-Stuff-10K and PASCAL-Context datasets. Furthermore, to reduce the computational cost of the ViT backbone, we propose query-based down-sampling (QD) and query-based up-sampling (QU) to build a Shrunk structure. With the proposed Shrunk structure, the model can save up to $40\%$ computations while maintaining competitive performance.
Attention-guided Chained Context Aggregation for Semantic Segmentation
Feb 27, 2020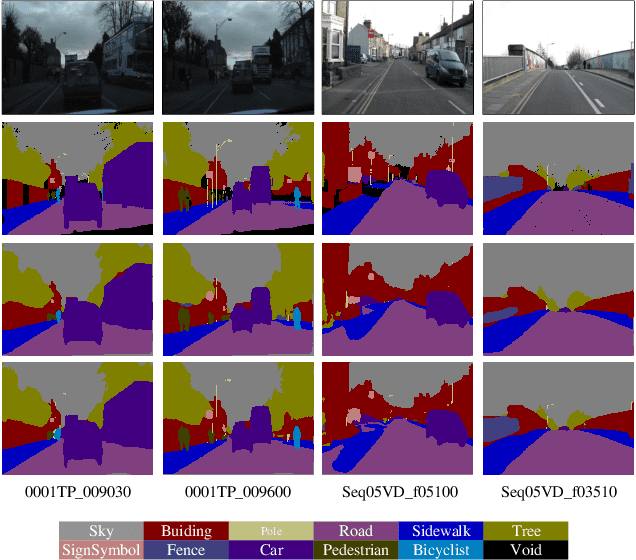
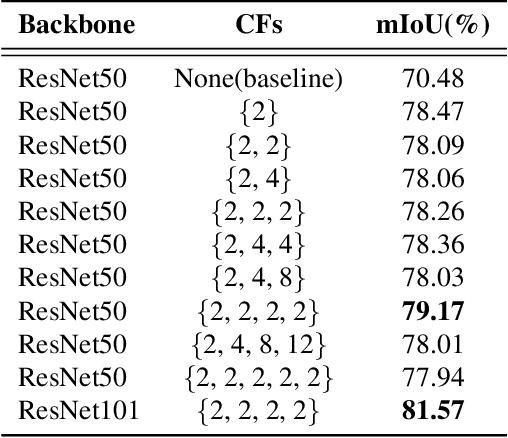
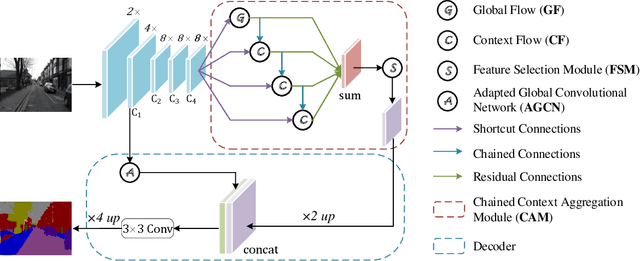

Recent breakthroughs in semantic segmentation methods based on Fully Convolutional Networks (FCNs) have aroused great research interest. One of the critical issues is how to aggregate multi-scale contextual information effectively to obtain reliable results. To address this problem, we propose a novel paradigm called the Chained Context Aggregation Module (CAM). CAM gains features of various spatial scales through chain-connected ladder-style information flows. The features are then guided by Flow Guidance Connections to interact and fuse in a two-stage process, which we refer to as pre-fusion and re-fusion. We further adopt attention models in CAM to productively recombine and select those fused features to refine performance. Based on these developments, we construct the Chained Context Aggregation Network (CANet), which employs a two-step decoder to recover precise spatial details of prediction maps. We conduct extensive experiments on three challenging datasets, including Pascal VOC 2012, CamVid and SUN-RGBD. Results evidence that our CANet achieves state-of-the-art performance. Codes will be available on the publication of this paper.