 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-guided Chained Context Aggregation for Semantic Segmentation
Paper and Code
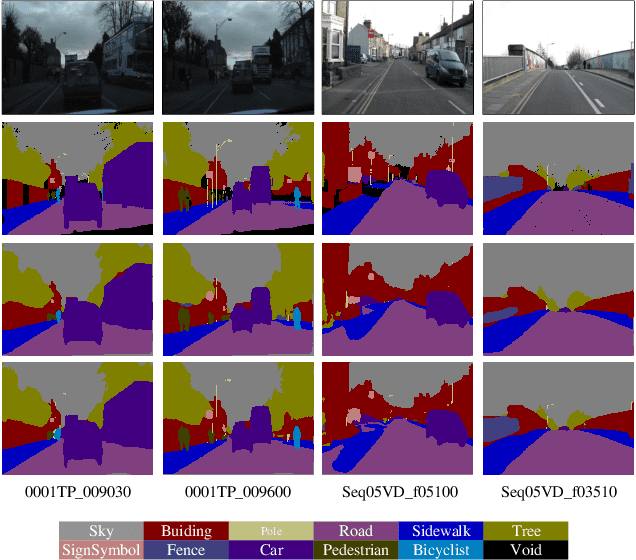
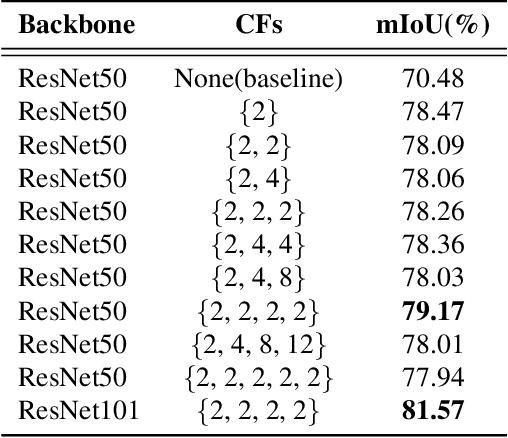
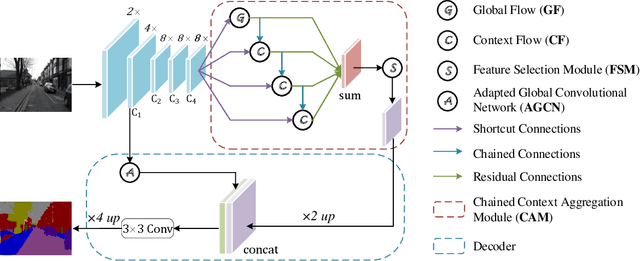

Recent breakthroughs in semantic segmentation methods based on Fully Convolutional Networks (FCNs) have aroused great research interest. One of the critical issues is how to aggregate multi-scale contextual information effectively to obtain reliable results. To address this problem, we propose a novel paradigm called the Chained Context Aggregation Module (CAM). CAM gains features of various spatial scales through chain-connected ladder-style information flows. The features are then guided by Flow Guidance Connections to interact and fuse in a two-stage process, which we refer to as pre-fusion and re-fusion. We further adopt attention models in CAM to productively recombine and select those fused features to refine performance. Based on these developments, we construct the Chained Context Aggregation Network (CANet), which employs a two-step decoder to recover precise spatial details of prediction maps. We conduct extensive experiments on three challenging datasets, including Pascal VOC 2012, CamVid and SUN-RGBD. Results evidence that our CANet achieves state-of-the-art performance. Codes will be available on the publication of this paper.