 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Sign Bits of DCT Coefficients in Digital Images as an Optimization Problem
Nov 02, 2022Recovering unknown, missing, damaged, distorted or lost information in DCT coefficients is a common task in multiple applications of digital image processing, including image compression, selective image encryption, and image communications. This paper investigates recovery of a special type of information in DCT coefficients of digital images: sign bits. This problem can be modelled as a mixed integer linear programming (MILP) problem, which is NP-hard in general. To efficiently solve the problem, we propose two approximation methods: 1) a relaxation-based method that convert the MILP problem to a linear programming (LP) problem; 2) a divide-and-conquer method which splits the target image into sufficiently small regions, each of which can be more efficiently solved as an MILP problem, and then conducts a global optimization phase as a smaller MILP problem or an LP problem to maximize smoothness across different regions. To the best of our knowledge, we are the first who considered how to use global optimization to recover sign bits of DCT coefficients. We considered how the proposed methods can be applied to JPEG-encoded images and conducted extensive experiments to validate the performances of our proposed methods. The experimental results showed that the proposed methods worked well, especially when the number of unknown sign bits per DCT block is not too large. Compared with other existing methods, which are all based on simple error-concealment strategies, our proposed methods outperformed them with a substantial margin, both according to objective quality metrics (PSNR and SSIM) and also our subjective evaluation. Our work has a number of profound implications, e.g., more sign bits can be discarded to develop more efficient image compression methods, and image encryption methods based on sign bit encryption can be less secure than we previously understood.
Constructing Multilayer Perceptrons as Piecewise Low-Order Polynomial Approximators: A Signal Processing Approach
Oct 15, 2020


The construction of a multilayer perceptron (MLP) as a piecewise low-order polynomial approximator using a signal processing approach is presented in this work. The constructed MLP contains one input, one intermediate and one output layers. Its construction includes the specification of neuron numbers and all filter weights. Through the construction, a one-to-one correspondence between the approximation of an MLP and that of a piecewise low-order polynomial is established. Comparison between piecewise polynomial and MLP approximations is made. Since the approximation capability of piecewise low-order polynomials is well understood, our findings shed light on the universal approximation capability of an MLP.
From Two-Class Linear Discriminant Analysis to Interpretable Multilayer Perceptron Design
Sep 09, 2020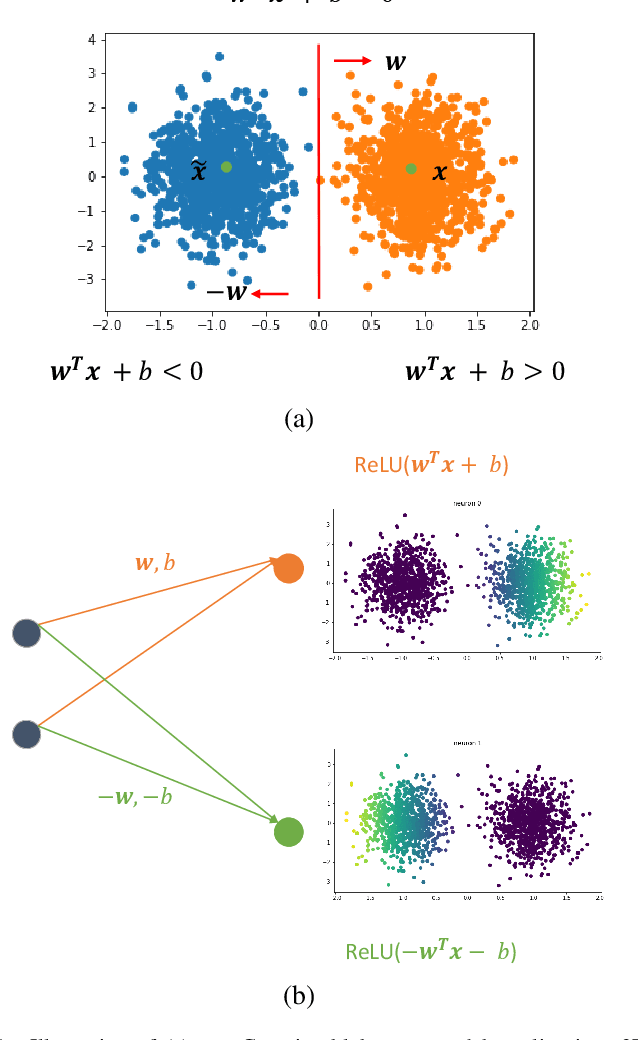
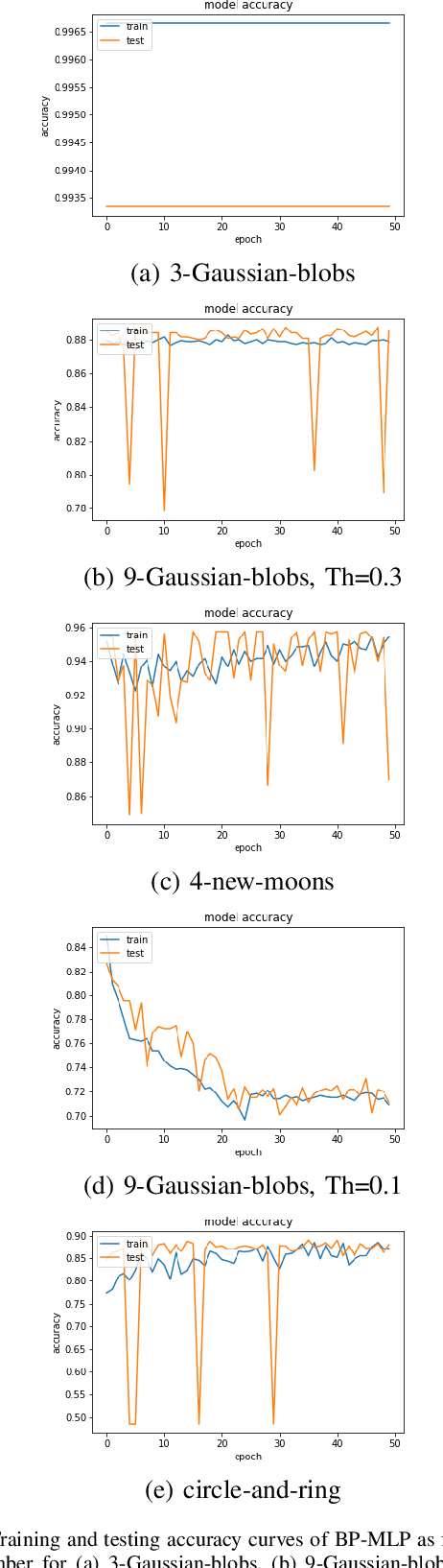
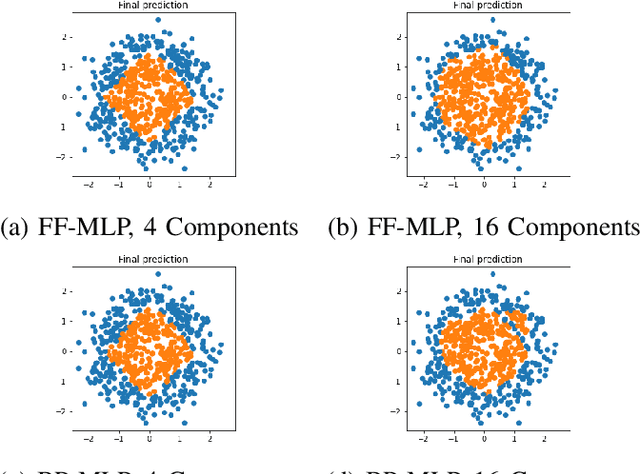
A closed-form solution exists in two-class linear discriminant analysis (LDA), which discriminates two Gaussian-distributed classes in a multi-dimensional feature space. In this work, we interpret the multilayer perceptron (MLP) as a generalization of a two-class LDA system so that it can handle an input composed by multiple Gaussian modalities belonging to multiple classes. Besides input layer $l_{in}$ and output layer $l_{out}$, the MLP of interest consists of two intermediate layers, $l_1$ and $l_2$. We propose a feedforward design that has three stages: 1) from $l_{in}$ to $l_1$: half-space partitionings accomplished by multiple parallel LDAs, 2) from $l_1$ to $l_2$: subspace isolation where one Gaussian modality is represented by one neuron, 3) from $l_2$ to $l_{out}$: class-wise subspace mergence, where each Gaussian modality is connected to its target class. Through this process, we present an automatic MLP design that can specify the network architecture (i.e., the layer number and the neuron number at a layer) and all filter weights in a feedforward one-pass fashion. This design can be generalized to an arbitrary distribution by leveraging the Gaussian mixture model (GMM). Experiments are conducted to compare the performance of the traditional backpropagation-based MLP (BP-MLP) and the new feedforward MLP (FF-MLP).
Tree-structured multi-stage principal component analysis (TMPCA): theory and applications
Oct 07, 2018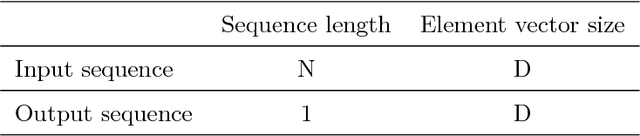
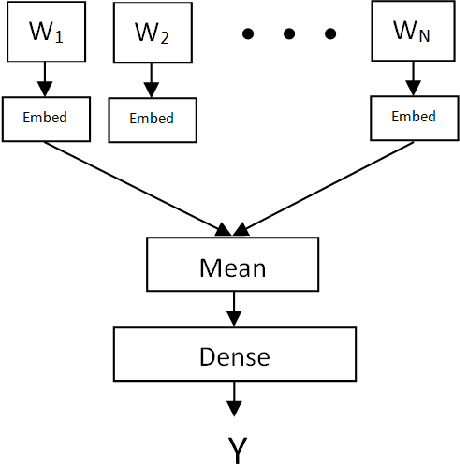
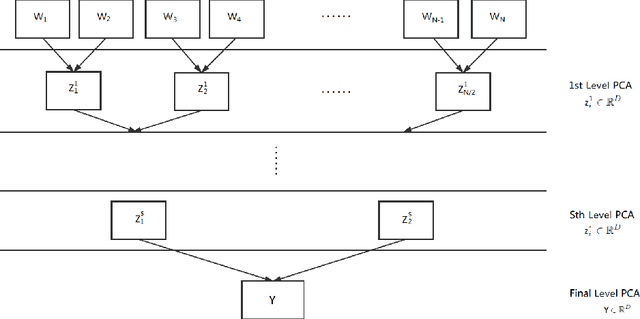
A PCA based sequence-to-vector (seq2vec) dimension reduction method for the text classification problem, called the tree-structured multi-stage principal component analysis (TMPCA) is presented in this paper. Theoretical analysis and applicability of TMPCA are demonstrated as an extension to our previous work (Su, Huang & Kuo). Unlike conventional word-to-vector embedding methods, the TMPCA method conducts dimension reduction at the sequence level without labeled training data. Furthermore, it can preserve the sequential structure of input sequences. We show that TMPCA is computationally efficient and able to facilitate sequence-based text classification tasks by preserving strong mutual information between its input and output mathematically. It is also demonstrated by experimental results that a dense (fully connected) network trained on the TMPCA preprocessed data achieves better performance than state-of-the-art fastText and other neural-network-based solutions.