 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-structured multi-stage principal component analysis (TMPCA): theory and applications
Paper and Code
Oct 07, 2018
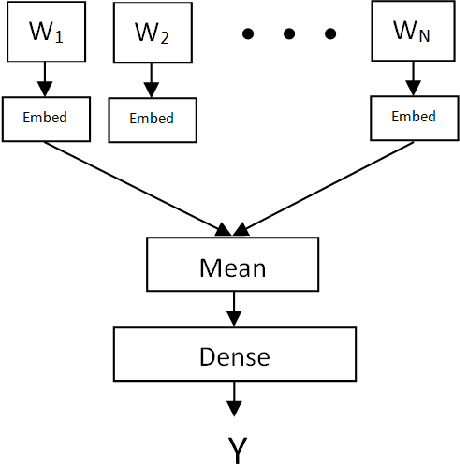
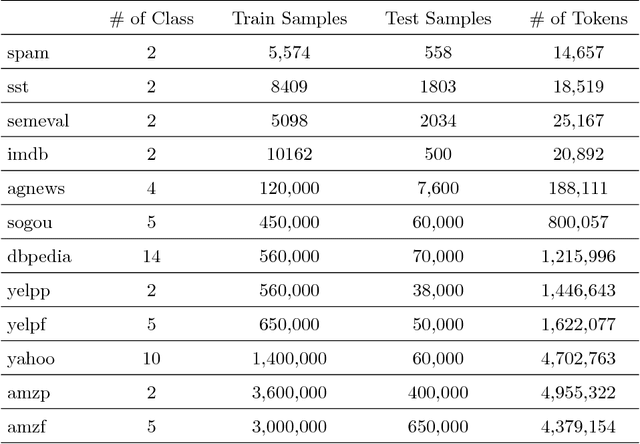
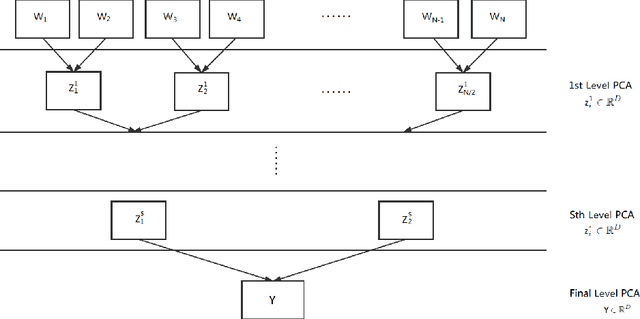
A PCA based sequence-to-vector (seq2vec) dimension reduction method for the text classification problem, called the tree-structured multi-stage principal component analysis (TMPCA) is presented in this paper. Theoretical analysis and applicability of TMPCA are demonstrated as an extension to our previous work (Su, Huang & Kuo). Unlike conventional word-to-vector embedding methods, the TMPCA method conducts dimension reduction at the sequence level without labeled training data. Furthermore, it can preserve the sequential structure of input sequences. We show that TMPCA is computationally efficient and able to facilitate sequence-based text classification tasks by preserving strong mutual information between its input and output mathematically. It is also demonstrated by experimental results that a dense (fully connected) network trained on the TMPCA preprocessed data achieves better performance than state-of-the-art fastText and other neural-network-based solutions.