 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Unsupervised Multi-modal Neural Machine Translation
Nov 28, 2018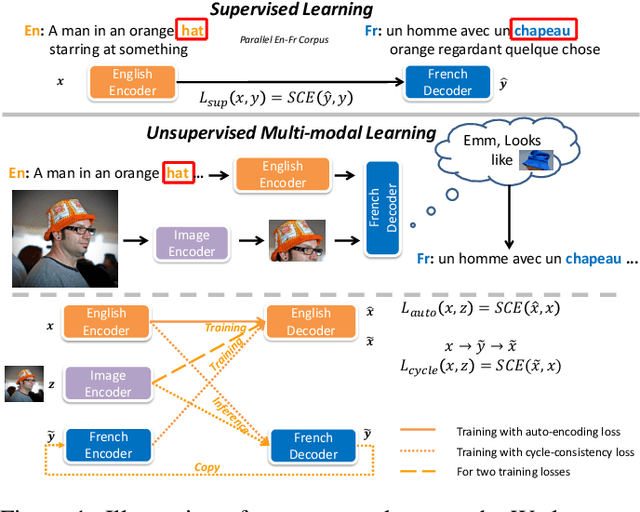
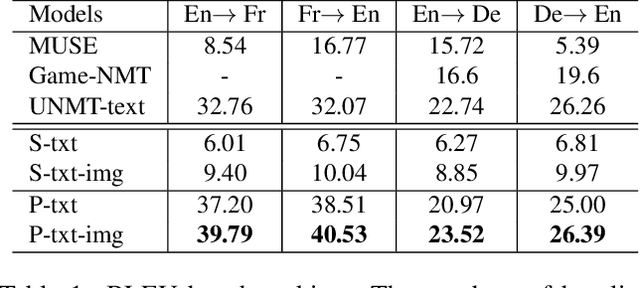
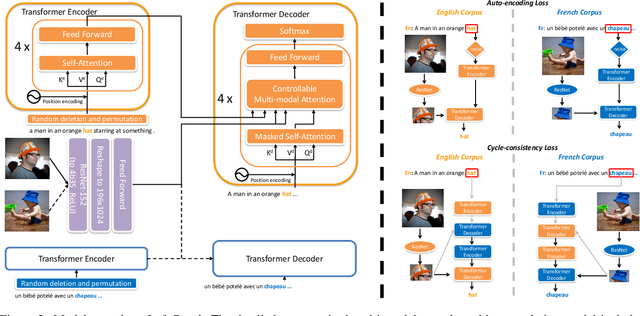

Unsupervised neural machine translation (UNMT) has recently achieved remarkable results with only large monolingual corpora in each language. However, the uncertainty of associating target with source sentences makes UNMT theoretically an ill-posed problem. This work investigates the possibility of utilizing images for disambiguation to improve the performance of UNMT. Our assumption is intuitively based on the invariant property of image, i.e., the description of the same visual content by different languages should be approximately similar. We propose an unsupervised multi-modal machine translation (UMNMT) framework based on the language translation cycle consistency loss conditional on the image, targeting to learn the bidirectional multi-modal translation simultaneously. Through an alternate training between multi-modal and uni-modal, our inference model can translate with or without the image. On the widely used Multi30K dataset, the experimental results of our approach are significantly better than those of the text-only UNMT on the 2016 test dataset.
Tree-structured multi-stage principal component analysis (TMPCA): theory and applications
Oct 07, 2018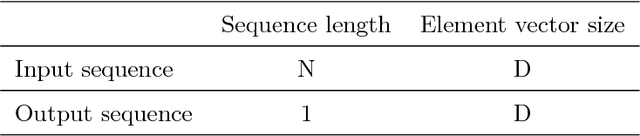
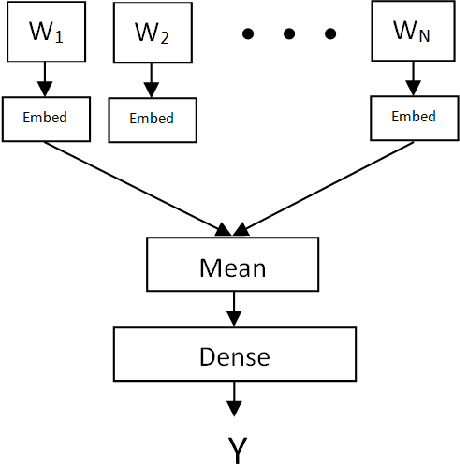
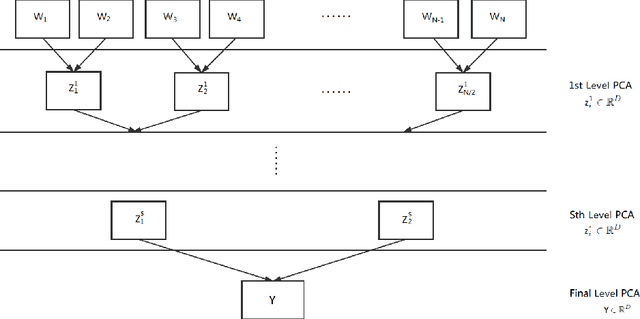
A PCA based sequence-to-vector (seq2vec) dimension reduction method for the text classification problem, called the tree-structured multi-stage principal component analysis (TMPCA) is presented in this paper. Theoretical analysis and applicability of TMPCA are demonstrated as an extension to our previous work (Su, Huang & Kuo). Unlike conventional word-to-vector embedding methods, the TMPCA method conducts dimension reduction at the sequence level without labeled training data. Furthermore, it can preserve the sequential structure of input sequences. We show that TMPCA is computationally efficient and able to facilitate sequence-based text classification tasks by preserving strong mutual information between its input and output mathematically. It is also demonstrated by experimental results that a dense (fully connected) network trained on the TMPCA preprocessed data achieves better performance than state-of-the-art fastText and other neural-network-based solutions.
On Extended Long Short-term Memory and Dependent Bidirectional Recurrent Neural Network
Sep 16, 2018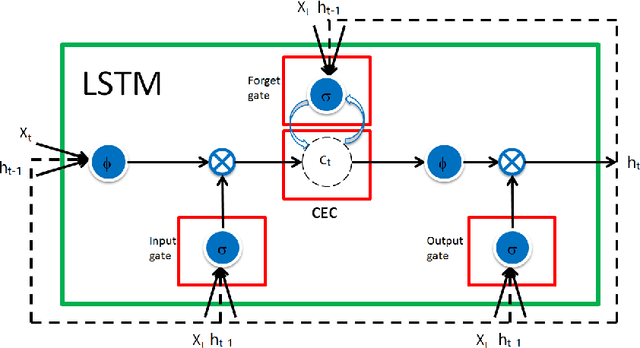

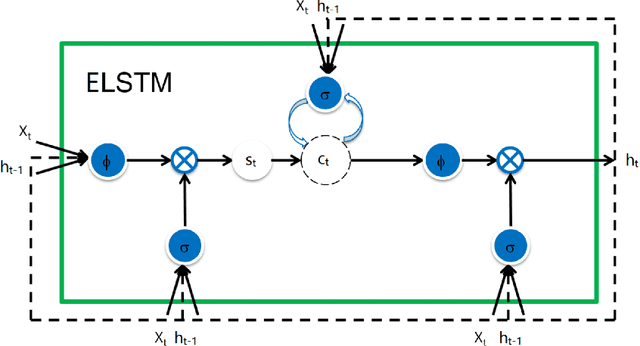

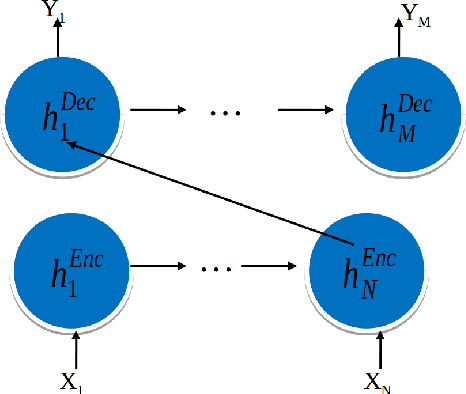
In this work, we analyze how memory forms in recurrent neural networks (RNN) and, based on the analysis, how to increase their memory capabilities in a mathematical rigorous way. Here, we define memory as a function that maps previous elements in a sequence to the current output. Our investigation concludes that the three RNN cells: simple RNN (SRN), long short-term memory (LSTM) and gated recurrent unit (GRU) all suffer memory decay as a function of the distance between the output to the input. To overcome this limitation by design, we introduce trainable scaling factors which act like an attention mechanism to increase the memory response to the semantic inputs if there is a memory decay and to decrease the response if memory decay of the noises is not fast enough. We call the new design extended LSTM (ELSTM). Next, we present a dependent bidirectional recurrent neural network (DBRNN), which is more robust to previous erroneous predictions. Extensive experiments are carried out on different language tasks to demonstrate the superiority of our proposed ELSTM and DBRNN solutions. In dependency parsing (DP), our proposed ELTSM has achieved up to 30% increase of labeled attachment score (LAS) as compared to LSTM and GRU. Our proposed models also outperformed other state-of-the-art models such as bi-attention and convolutional sequence to sequence (convseq2seq) by close to 10% LAS.
Efficient Text Classification Using Tree-structured Multi-linear Principal Component Analysis
Feb 24, 2018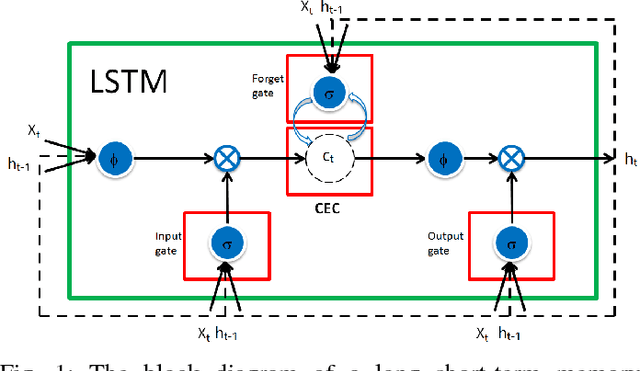
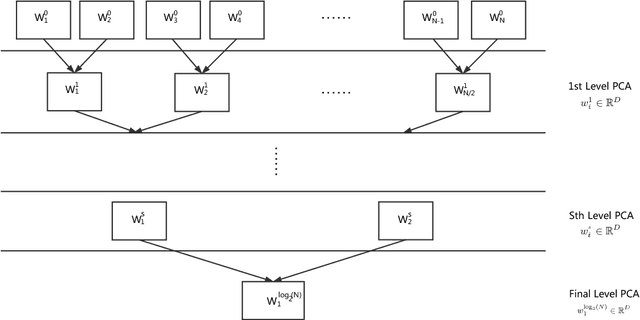

A novel text data dimension reduction technique, called the tree-structured multi-linear principal component anal- ysis (TMPCA), is proposed in this work. Being different from traditional text dimension reduction methods that deal with the word-level representation, the TMPCA technique reduces the dimension of input sequences and sentences to simplify the following text classification tasks. It is shown mathematically and experimentally that the TMPCA tool demands much lower complexity (and, hence, less computing power) than the ordinary principal component analysis (PCA). Furthermore, it is demon- strated by experimental results that the support vector machine (SVM) method applied to the TMPCA-processed data achieves commensurable or better performance than the state-of-the-art recurrent neural network (RNN) approach.