 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Extended Long Short-term Memory and Dependent Bidirectional Recurrent Neural Network
Paper and Code
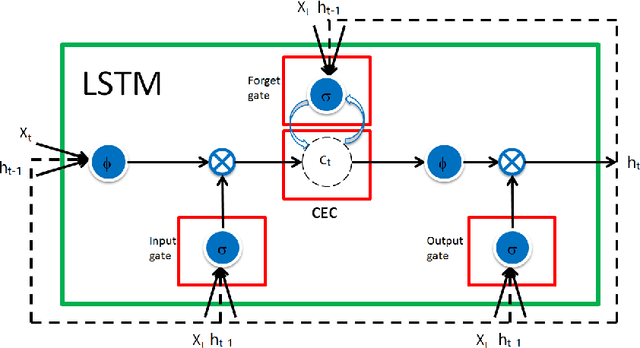

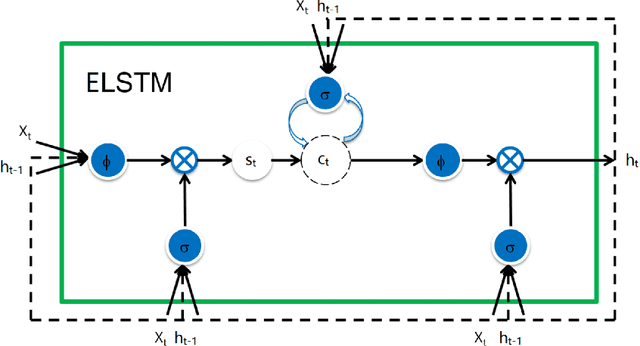

In this work, we analyze how memory forms in recurrent neural networks (RNN) and, based on the analysis, how to increase their memory capabilities in a mathematical rigorous way. Here, we define memory as a function that maps previous elements in a sequence to the current output. Our investigation concludes that the three RNN cells: simple RNN (SRN), long short-term memory (LSTM) and gated recurrent unit (GRU) all suffer memory decay as a function of the distance between the output to the input. To overcome this limitation by design, we introduce trainable scaling factors which act like an attention mechanism to increase the memory response to the semantic inputs if there is a memory decay and to decrease the response if memory decay of the noises is not fast enough. We call the new design extended LSTM (ELSTM). Next, we present a dependent bidirectional recurrent neural network (DBRNN), which is more robust to previous erroneous predictions. Extensive experiments are carried out on different language tasks to demonstrate the superiority of our proposed ELSTM and DBRNN solutions. In dependency parsing (DP), our proposed ELTSM has achieved up to 30% increase of labeled attachment score (LAS) as compared to LSTM and GRU. Our proposed models also outperformed other state-of-the-art models such as bi-attention and convolutional sequence to sequence (convseq2seq) by close to 10% LAS.