 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Paper and Code

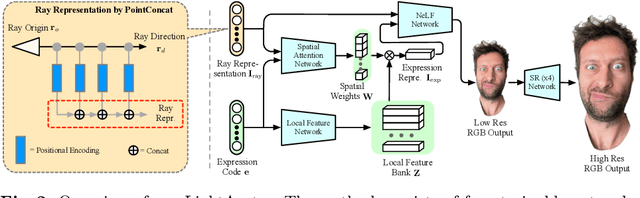


Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.