 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGSM: A Foundation-model-like Semi-generalist Sensing Model
Jun 15, 2024

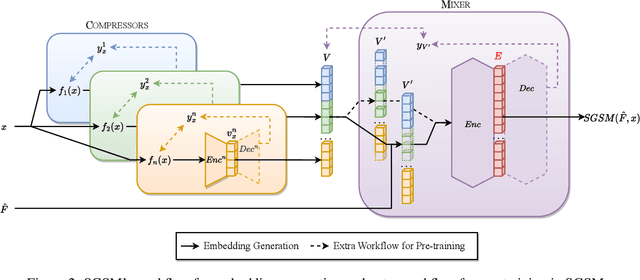

The significance of intelligent sensing systems is growing in the realm of smart services. These systems extract relevant signal features and generate informative representations for particular tasks. However, building the feature extraction component for such systems requires extensive domain-specific expertise or data. The exceptionally rapid development of foundation models is likely to usher in newfound abilities in such intelligent sensing. We propose a new scheme for sensing model, which we refer to as semi-generalist sensing model (SGSM). SGSM is able to semiautomatically solve various tasks using relatively less task-specific labeled data compared to traditional systems. Built through the analysis of the common theoretical model, SGSM can depict different modalities, such as the acoustic and Wi-Fi signal. Experimental results on such two heterogeneous sensors illustrate that SGSM functions across a wide range of scenarios, thereby establishing its broad applicability. In some cases, SGSM even achieves better performance than sensor-specific specialized solutions. Wi-Fi evaluations indicate a 20\% accuracy improvement when applying SGSM to an existing sensing model.
URHand: Universal Relightable Hands
Jan 10, 2024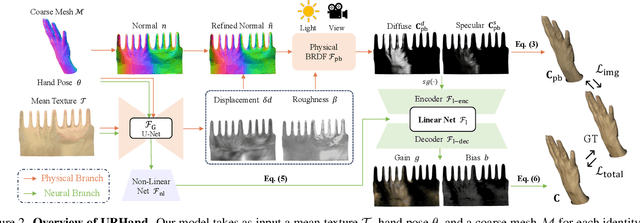
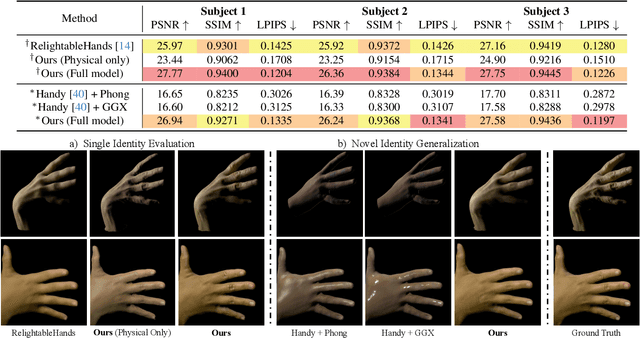
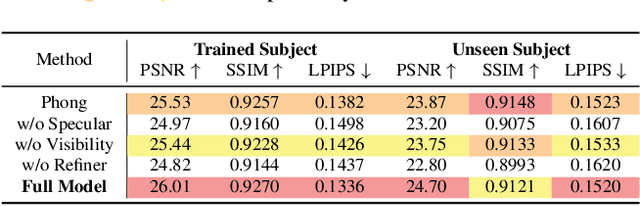
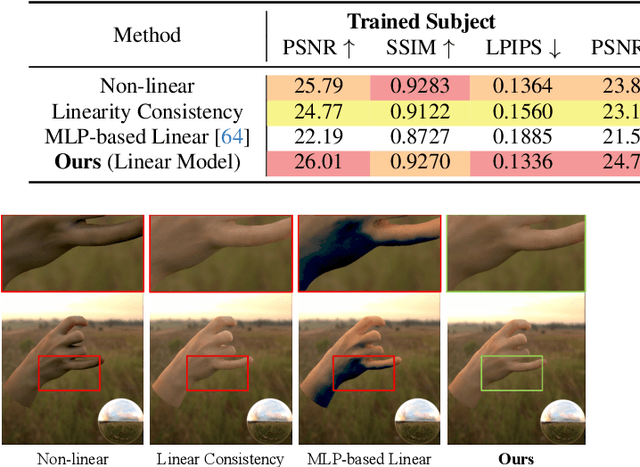
Existing photorealistic relightable hand models require extensive identity-specific observations in different views, poses, and illuminations, and face challenges in generalizing to natural illuminations and novel identities. To bridge this gap, we present URHand, the first universal relightable hand model that generalizes across viewpoints, poses, illuminations, and identities. Our model allows few-shot personalization using images captured with a mobile phone, and is ready to be photorealistically rendered under novel illuminations. To simplify the personalization process while retaining photorealism, we build a powerful universal relightable prior based on neural relighting from multi-view images of hands captured in a light stage with hundreds of identities. The key challenge is scaling the cross-identity training while maintaining personalized fidelity and sharp details without compromising generalization under natural illuminations. To this end, we propose a spatially varying linear lighting model as the neural renderer that takes physics-inspired shading as input feature. By removing non-linear activations and bias, our specifically designed lighting model explicitly keeps the linearity of light transport. This enables single-stage training from light-stage data while generalizing to real-time rendering under arbitrary continuous illuminations across diverse identities. In addition, we introduce the joint learning of a physically based model and our neural relighting model, which further improves fidelity and generalization. Extensive experiments show that our approach achieves superior performance over existing methods in terms of both quality and generalizability. We also demonstrate quick personalization of URHand from a short phone scan of an unseen identity.
Drivable Avatar Clothing: Faithful Full-Body Telepresence with Dynamic Clothing Driven by Sparse RGB-D Input
Oct 11, 2023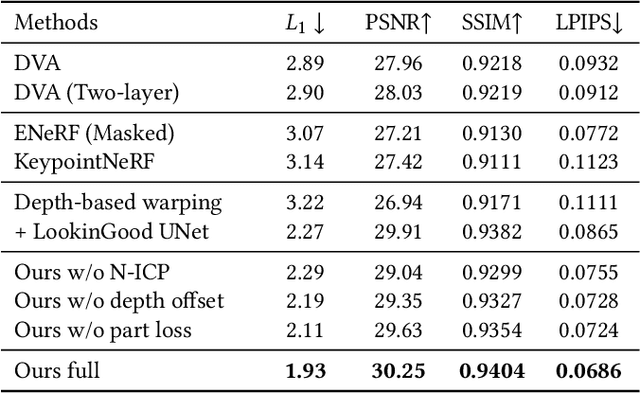


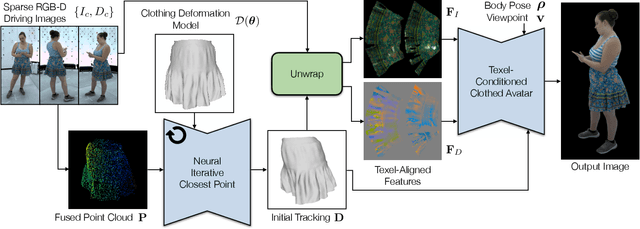
Clothing is an important part of human appearance but challenging to model in photorealistic avatars. In this work we present avatars with dynamically moving loose clothing that can be faithfully driven by sparse RGB-D inputs as well as body and face motion. We propose a Neural Iterative Closest Point (N-ICP) algorithm that can efficiently track the coarse garment shape given sparse depth input. Given the coarse tracking results, the input RGB-D images are then remapped to texel-aligned features, which are fed into the drivable avatar models to faithfully reconstruct appearance details. We evaluate our method against recent image-driven synthesis baselines, and conduct a comprehensive analysis of the N-ICP algorithm. We demonstrate that our method can generalize to a novel testing environment, while preserving the ability to produce high-fidelity and faithful clothing dynamics and appearance.
Grouped Knowledge Distillation for Deep Face Recognition
Apr 10, 2023



Compared with the feature-based distillation methods, logits distillation can liberalize the requirements of consistent feature dimension between teacher and student networks, while the performance is deemed inferior in face recognition. One major challenge is that the light-weight student network has difficulty fitting the target logits due to its low model capacity, which is attributed to the significant number of identities in face recognition. Therefore, we seek to probe the target logits to extract the primary knowledge related to face identity, and discard the others, to make the distillation more achievable for the student network. Specifically, there is a tail group with near-zero values in the prediction, containing minor knowledge for distillation. To provide a clear perspective of its impact, we first partition the logits into two groups, i.e., Primary Group and Secondary Group, according to the cumulative probability of the softened prediction. Then, we reorganize the Knowledge Distillation (KD) loss of grouped logits into three parts, i.e., Primary-KD, Secondary-KD, and Binary-KD. Primary-KD refers to distilling the primary knowledge from the teacher, Secondary-KD aims to refine minor knowledge but increases the difficulty of distillation, and Binary-KD ensures the consistency of knowledge distribution between teacher and student. We experimentally found that (1) Primary-KD and Binary-KD are indispensable for KD, and (2) Secondary-KD is the culprit restricting KD at the bottleneck. Therefore, we propose a Grouped Knowledge Distillation (GKD) that retains the Primary-KD and Binary-KD but omits Secondary-KD in the ultimate KD loss calculation. Extensive experimental results on popular face recognition benchmarks demonstrate the superiority of proposed GKD over state-of-the-art methods.
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
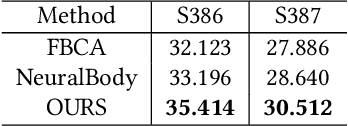
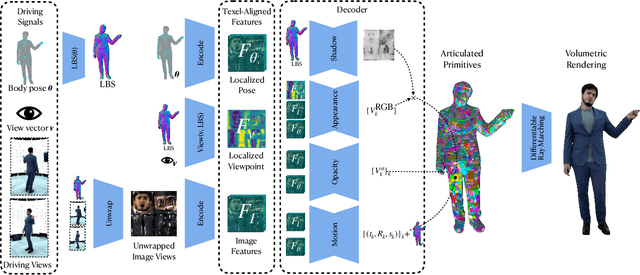
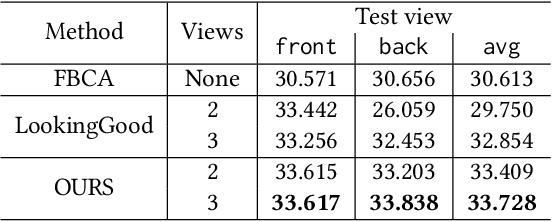
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.
Geometry-aware Single-image Full-body Human Relighting
Jul 12, 2022
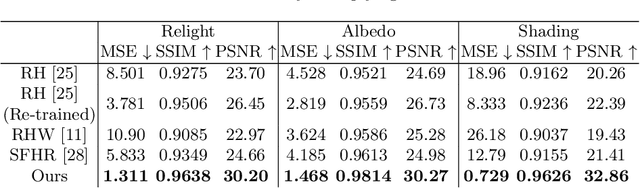
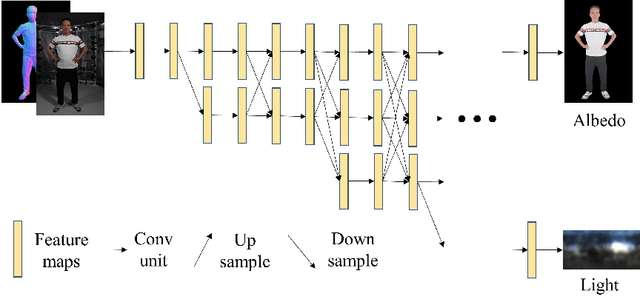
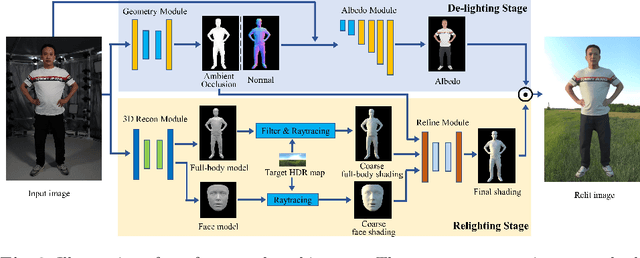
Single-image human relighting aims to relight a target human under new lighting conditions by decomposing the input image into albedo, shape and lighting. Although plausible relighting results can be achieved, previous methods suffer from both the entanglement between albedo and lighting and the lack of hard shadows, which significantly decrease the realism. To tackle these two problems, we propose a geometry-aware single-image human relighting framework that leverages single-image geometry reconstruction for joint deployment of traditional graphics rendering and neural rendering techniques. For the de-lighting, we explore the shortcomings of UNet architecture and propose a modified HRNet, achieving better disentanglement between albedo and lighting. For the relighting, we introduce a ray tracing-based per-pixel lighting representation that explicitly models high-frequency shadows and propose a learning-based shading refinement module to restore realistic shadows (including hard cast shadows) from the ray-traced shading maps. Our framework is able to generate photo-realistic high-frequency shadows such as cast shadows under challenging lighting conditions. Extensive experiments demonstrate that our proposed method outperforms previous methods on both synthetic and real images.
NeuralHOFusion: Neural Volumetric Rendering under Human-object Interactions
Mar 28, 2022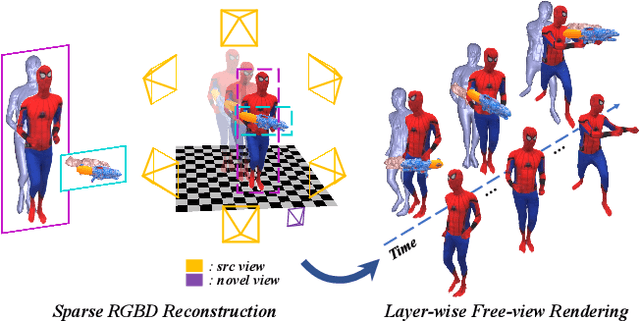
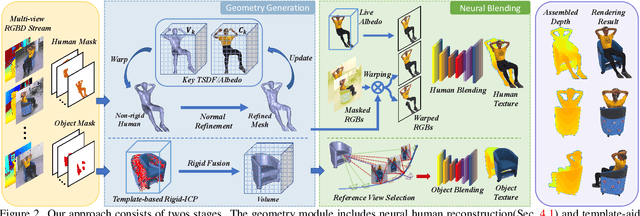
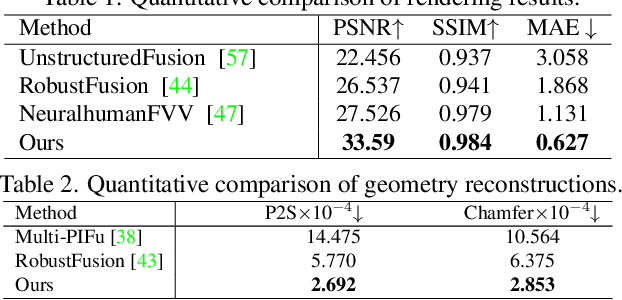
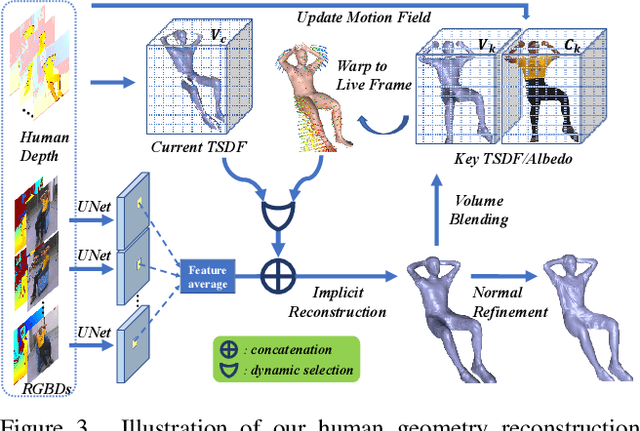
4D modeling of human-object interactions is critical for numerous applications. However, efficient volumetric capture and rendering of complex interaction scenarios, especially from sparse inputs, remain challenging. In this paper, we propose NeuralHOFusion, a neural approach for volumetric human-object capture and rendering using sparse consumer RGBD sensors. It marries traditional non-rigid fusion with recent neural implicit modeling and blending advances, where the captured humans and objects are layerwise disentangled. For geometry modeling, we propose a neural implicit inference scheme with non-rigid key-volume fusion, as well as a template-aid robust object tracking pipeline. Our scheme enables detailed and complete geometry generation under complex interactions and occlusions. Moreover, we introduce a layer-wise human-object texture rendering scheme, which combines volumetric and image-based rendering in both spatial and temporal domains to obtain photo-realistic results. Extensive experiments demonstrate the effectiveness and efficiency of our approach in synthesizing photo-realistic free-view results under complex human-object interactions.
Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
May 06, 2021


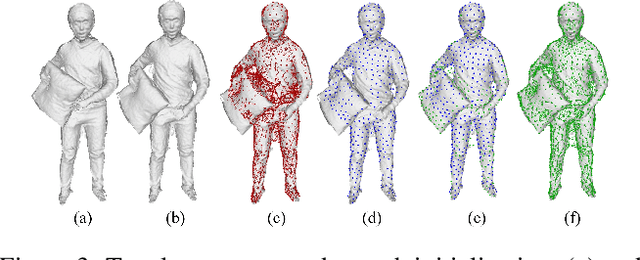
Human volumetric capture is a long-standing topic in computer vision and computer graphics. Although high-quality results can be achieved using sophisticated off-line systems, real-time human volumetric capture of complex scenarios, especially using light-weight setups, remains challenging. In this paper, we propose a human volumetric capture method that combines temporal volumetric fusion and deep implicit functions. To achieve high-quality and temporal-continuous reconstruction, we propose dynamic sliding fusion to fuse neighboring depth observations together with topology consistency. Moreover, for detailed and complete surface generation, we propose detail-preserving deep implicit functions for RGBD input which can not only preserve the geometric details on the depth inputs but also generate more plausible texturing results. Results and experiments show that our method outperforms existing methods in terms of view sparsity, generalization capacity, reconstruction quality, and run-time efficiency.
HumanGPS: Geodesic PreServing Feature for Dense Human Correspondences
Mar 29, 2021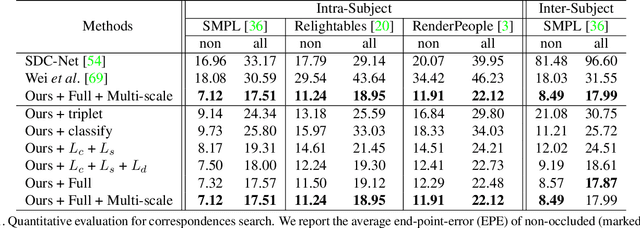

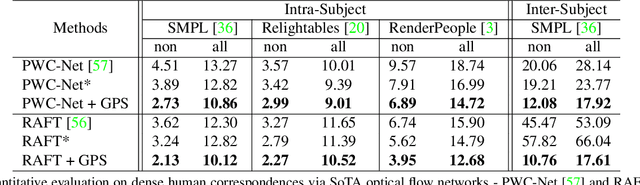
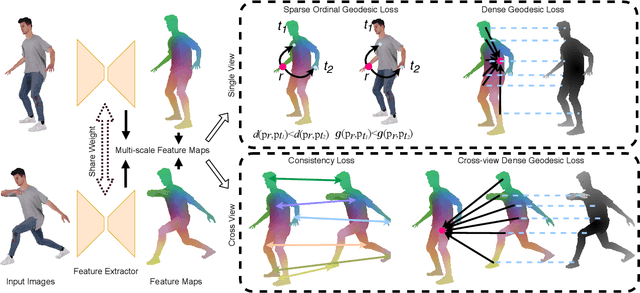
In this paper, we address the problem of building dense correspondences between human images under arbitrary camera viewpoints and body poses. Prior art either assumes small motion between frames or relies on local descriptors, which cannot handle large motion or visually ambiguous body parts, e.g., left vs. right hand. In contrast, we propose a deep learning framework that maps each pixel to a feature space, where the feature distances reflect the geodesic distances among pixels as if they were projected onto the surface of a 3D human scan. To this end, we introduce novel loss functions to push features apart according to their geodesic distances on the surface. Without any semantic annotation, the proposed embeddings automatically learn to differentiate visually similar parts and align different subjects into an unified feature space. Extensive experiments show that the learned embeddings can produce accurate correspondences between images with remarkable generalization capabilities on both intra and inter subjects.
POSEFusion: Pose-guided Selective Fusion for Single-view Human Volumetric Capture
Mar 29, 2021


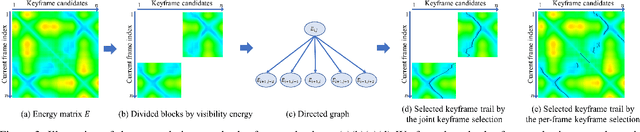
We propose POse-guided SElective Fusion (POSEFusion), a single-view human volumetric capture method that leverages tracking-based methods and tracking-free inference to achieve high-fidelity and dynamic 3D reconstruction. By contributing a novel reconstruction framework which contains pose-guided keyframe selection and robust implicit surface fusion, our method fully utilizes the advantages of both tracking-based methods and tracking-free inference methods, and finally enables the high-fidelity reconstruction of dynamic surface details even in the invisible regions. We formulate the keyframe selection as a dynamic programming problem to guarantee the temporal continuity of the reconstructed sequence. Moreover, the novel robust implicit surface fusion involves an adaptive blending weight to preserve high-fidelity surface details and an automatic collision handling method to deal with the potential self-collisions. Overall, our method enables high-fidelity and dynamic capture in both visible and invisible regions from a single RGBD camera, and the results and experiments show that our method outperforms state-of-the-art methods.