 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALM: A Dataset and Baseline for Learning Multi-subject Hand Prior
Nov 07, 2025

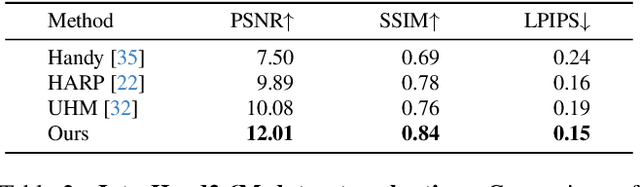
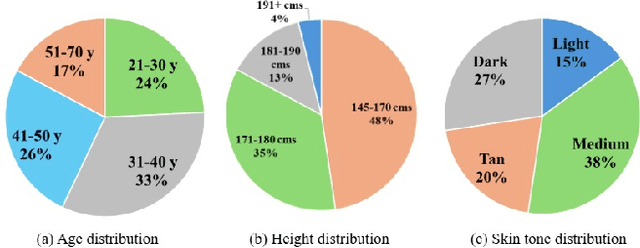
The ability to grasp objects, signal with gestures, and share emotion through touch all stem from the unique capabilities of human hands. Yet creating high-quality personalized hand avatars from images remains challenging due to complex geometry, appearance, and articulation, particularly under unconstrained lighting and limited views. Progress has also been limited by the lack of datasets that jointly provide accurate 3D geometry, high-resolution multiview imagery, and a diverse population of subjects. To address this, we present PALM, a large-scale dataset comprising 13k high-quality hand scans from 263 subjects and 90k multi-view images, capturing rich variation in skin tone, age, and geometry. To show its utility, we present a baseline PALM-Net, a multi-subject prior over hand geometry and material properties learned via physically based inverse rendering, enabling realistic, relightable single-image hand avatar personalization. PALM's scale and diversity make it a valuable real-world resource for hand modeling and related research.
X-MIC: Cross-Modal Instance Conditioning for Egocentric Action Generalization
Mar 28, 2024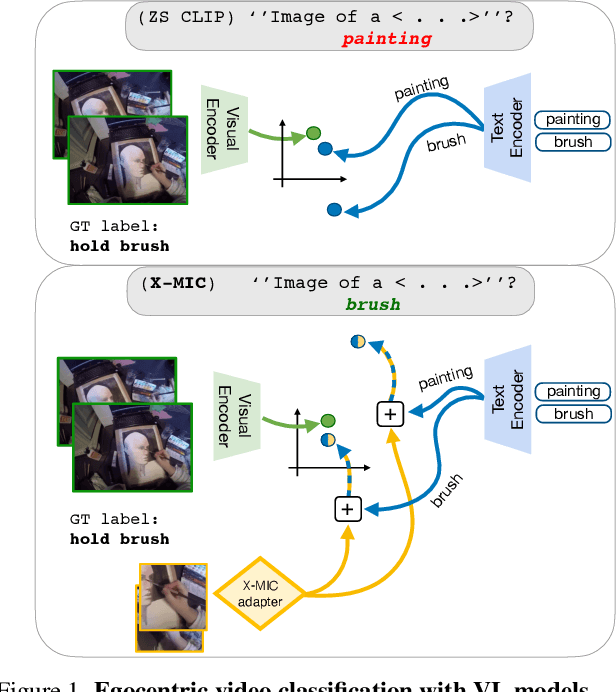
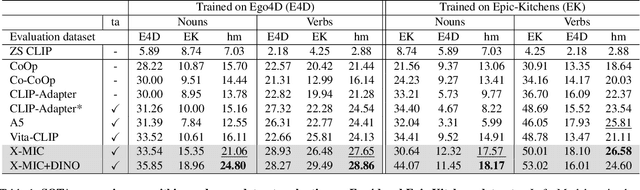
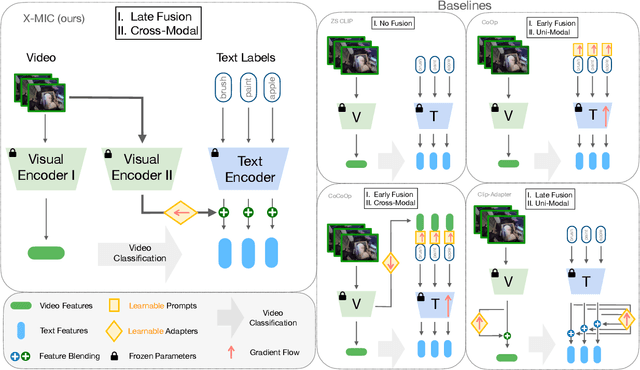
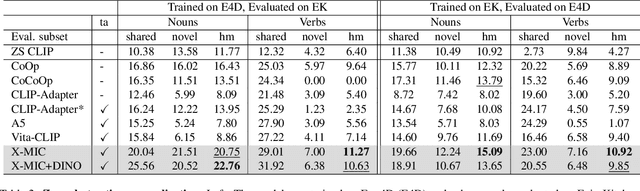
Lately, there has been growing interest in adapting vision-language models (VLMs) to image and third-person video classification due to their success in zero-shot recognition. However, the adaptation of these models to egocentric videos has been largely unexplored. To address this gap, we propose a simple yet effective cross-modal adaptation framework, which we call X-MIC. Using a video adapter, our pipeline learns to align frozen text embeddings to each egocentric video directly in the shared embedding space. Our novel adapter architecture retains and improves generalization of the pre-trained VLMs by disentangling learnable temporal modeling and frozen visual encoder. This results in an enhanced alignment of text embeddings to each egocentric video, leading to a significant improvement in cross-dataset generalization. We evaluate our approach on the Epic-Kitchens, Ego4D, and EGTEA datasets for fine-grained cross-dataset action generalization, demonstrating the effectiveness of our method. Code is available at https://github.com/annusha/xmic
DiffH2O: Diffusion-Based Synthesis of Hand-Object Interactions from Textual Descriptions
Mar 26, 2024



Generating natural hand-object interactions in 3D is challenging as the resulting hand and object motions are expected to be physically plausible and semantically meaningful. Furthermore, generalization to unseen objects is hindered by the limited scale of available hand-object interaction datasets. We propose DiffH2O, a novel method to synthesize realistic, one or two-handed object interactions from provided text prompts and geometry of the object. The method introduces three techniques that enable effective learning from limited data. First, we decompose the task into a grasping stage and a text-based interaction stage and use separate diffusion models for each. In the grasping stage, the model only generates hand motions, whereas in the interaction phase both hand and object poses are synthesized. Second, we propose a compact representation that tightly couples hand and object poses. Third, we propose two different guidance schemes to allow more control of the generated motions: grasp guidance and detailed textual guidance. Grasp guidance takes a single target grasping pose and guides the diffusion model to reach this grasp at the end of the grasping stage, which provides control over the grasping pose. Given a grasping motion from this stage, multiple different actions can be prompted in the interaction phase. For textual guidance, we contribute comprehensive text descriptions to the GRAB dataset and show that they enable our method to have more fine-grained control over hand-object interactions. Our quantitative and qualitative evaluation demonstrates that the proposed method outperforms baseline methods and leads to natural hand-object motions. Moreover, we demonstrate the practicality of our framework by utilizing a hand pose estimate from an off-the-shelf pose estimator for guidance, and then sampling multiple different actions in the interaction stage.
DIG: Draping Implicit Garment over the Human Body
Sep 24, 2022
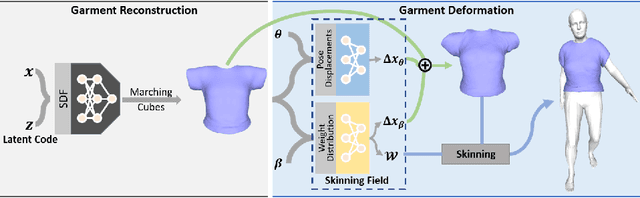

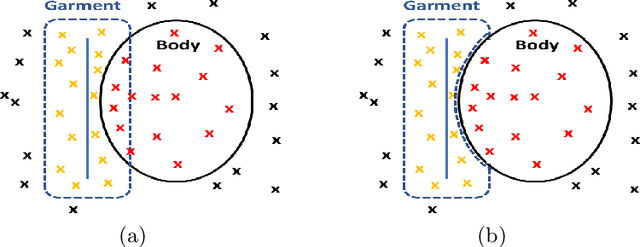
Existing data-driven methods for draping garments over human bodies, despite being effective, cannot handle garments of arbitrary topology and are typically not end-to-end differentiable. To address these limitations, we propose an end-to-end differentiable pipeline that represents garments using implicit surfaces and learns a skinning field conditioned on shape and pose parameters of an articulated body model. To limit body-garment interpenetrations and artifacts, we propose an interpenetration-aware pre-processing strategy of training data and a novel training loss that penalizes self-intersections while draping garments. We demonstrate that our method yields more accurate results for garment reconstruction and deformation with respect to state of the art methods. Furthermore, we show that our method, thanks to its end-to-end differentiability, allows to recover body and garments parameters jointly from image observations, something that previous work could not do.
Drivable Volumetric Avatars using Texel-Aligned Features
Jul 20, 2022
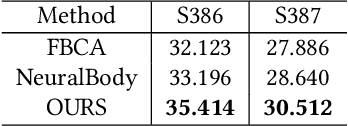
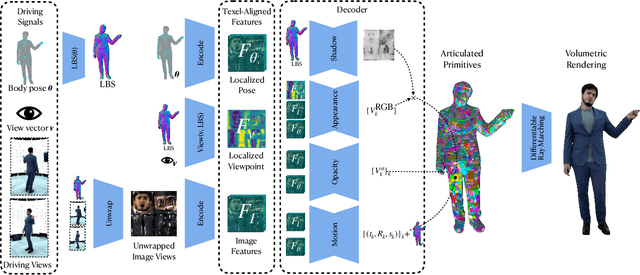
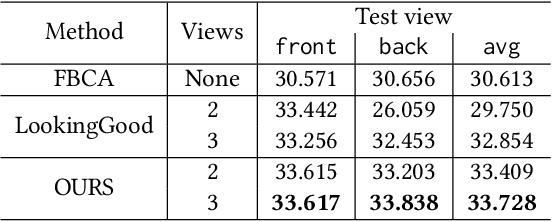
Photorealistic telepresence requires both high-fidelity body modeling and faithful driving to enable dynamically synthesized appearance that is indistinguishable from reality. In this work, we propose an end-to-end framework that addresses two core challenges in modeling and driving full-body avatars of real people. One challenge is driving an avatar while staying faithful to details and dynamics that cannot be captured by a global low-dimensional parameterization such as body pose. Our approach supports driving of clothed avatars with wrinkles and motion that a real driving performer exhibits beyond the training corpus. Unlike existing global state representations or non-parametric screen-space approaches, we introduce texel-aligned features -- a localised representation which can leverage both the structural prior of a skeleton-based parametric model and observed sparse image signals at the same time. Another challenge is modeling a temporally coherent clothed avatar, which typically requires precise surface tracking. To circumvent this, we propose a novel volumetric avatar representation by extending mixtures of volumetric primitives to articulated objects. By explicitly incorporating articulation, our approach naturally generalizes to unseen poses. We also introduce a localized viewpoint conditioning, which leads to a large improvement in generalization of view-dependent appearance. The proposed volumetric representation does not require high-quality mesh tracking as a prerequisite and brings significant quality improvements compared to mesh-based counterparts. In our experiments, we carefully examine our design choices and demonstrate the efficacy of our approach, outperforming the state-of-the-art methods on challenging driving scenarios.
DeepMesh: Differentiable Iso-Surface Extraction
Jun 20, 2021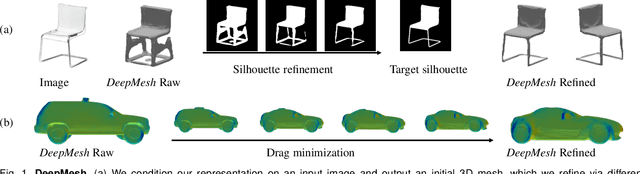
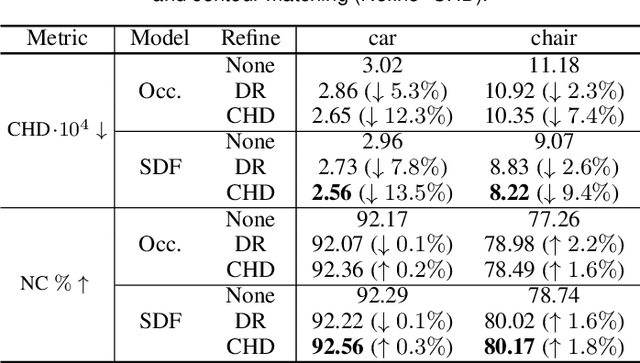
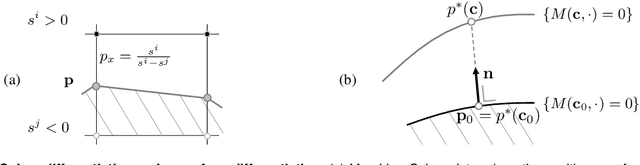
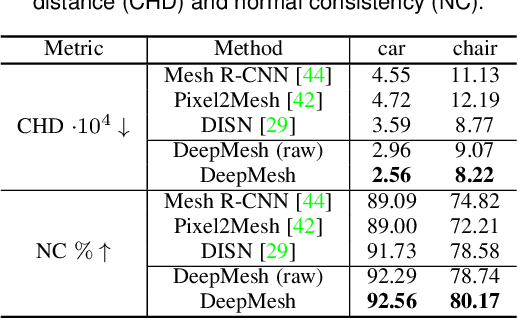
Geometric Deep Learning has recently made striking progress with the advent of continuous Deep Implicit Fields. They allow for detailed modeling of watertight surfaces of arbitrary topology while not relying on a 3D Euclidean grid, resulting in a learnable parameterization that is unlimited in resolution. Unfortunately, these methods are often unsuitable for applications that require an explicit mesh-based surface representation because converting an implicit field to such a representation relies on the Marching Cubes algorithm, which cannot be differentiated with respect to the underlying implicit field. In this work, we remove this limitation and introduce a differentiable way to produce explicit surface mesh representations from Deep Implicit Fields. Our key insight is that by reasoning on how implicit field perturbations impact local surface geometry, one can ultimately differentiate the 3D location of surface samples with respect to the underlying deep implicit field. We exploit this to define DeepMesh -- end-to-end differentiable mesh representation that can vary its topology. We use two different applications to validate our theoretical insight: Single view 3D Reconstruction via Differentiable Rendering and Physically-Driven Shape Optimization. In both cases our end-to-end differentiable parameterization gives us an edge over state-of-the-art algorithms.
Sketch2Mesh: Reconstructing and Editing 3D Shapes from Sketches
Apr 01, 2021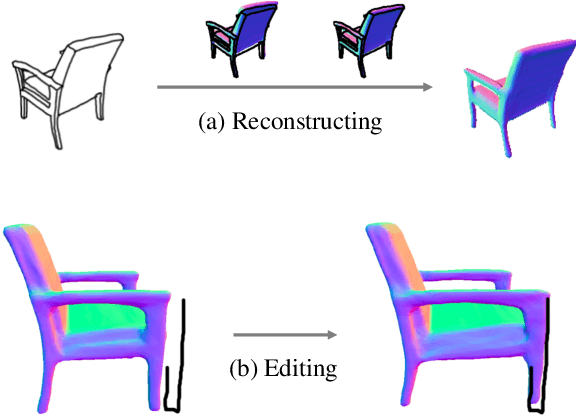

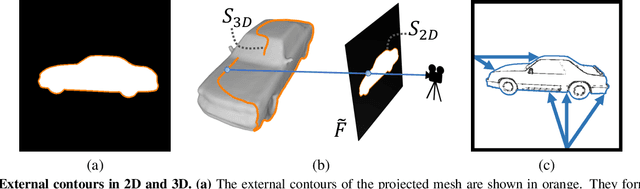
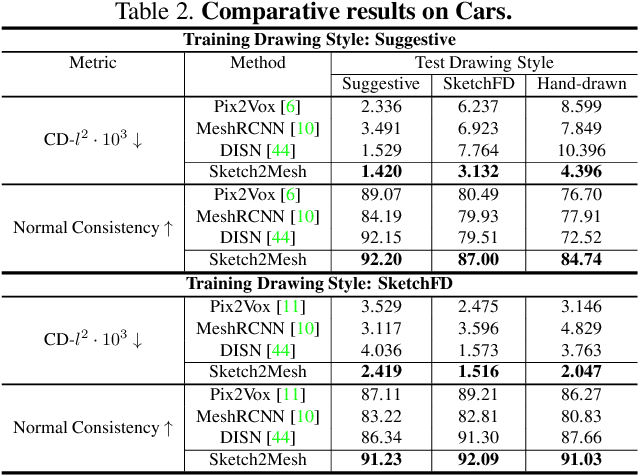
Reconstructing 3D shape from 2D sketches has long been an open problem because the sketches only provide very sparse and ambiguous information. In this paper, we use an encoder/decoder architecture for the sketch to mesh translation. This enables us to leverage its latent parametrization to represent and refine a 3D mesh so that its projections match the external contours outlined in the sketch. We will show that this approach is easy to deploy, robust to style changes, and effective. Furthermore, it can be used for shape refinement given only single pen strokes. We compare our approach to state-of-the-art methods on sketches -- both hand-drawn and synthesized -- and demonstrate that we outperform them.
Unsupervised Domain Adaptation with Temporal-Consistent Self-Training for 3D Hand-Object Joint Reconstruction
Dec 21, 2020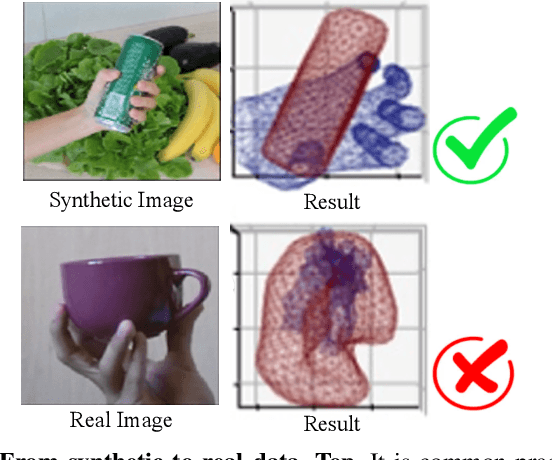
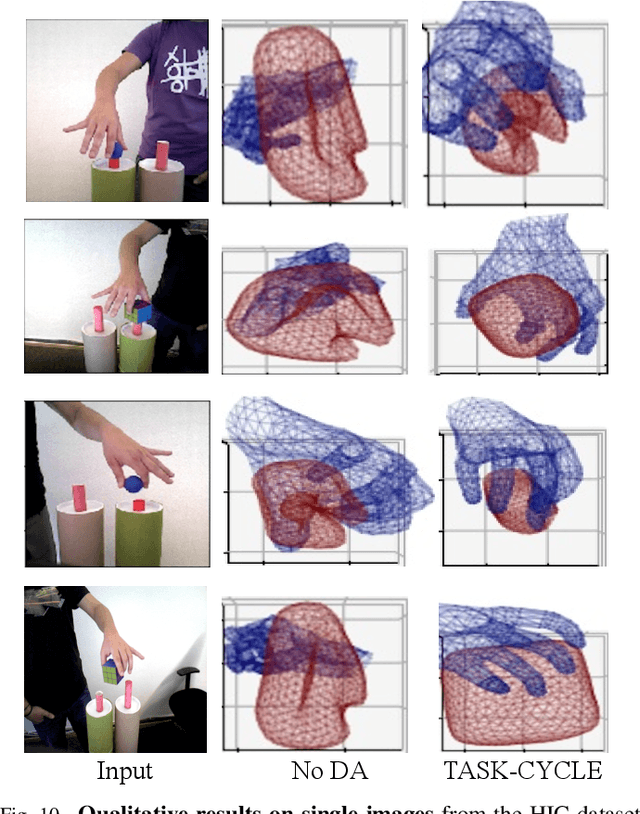
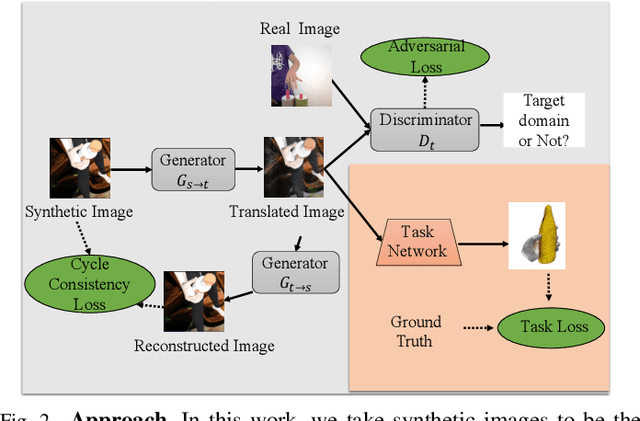
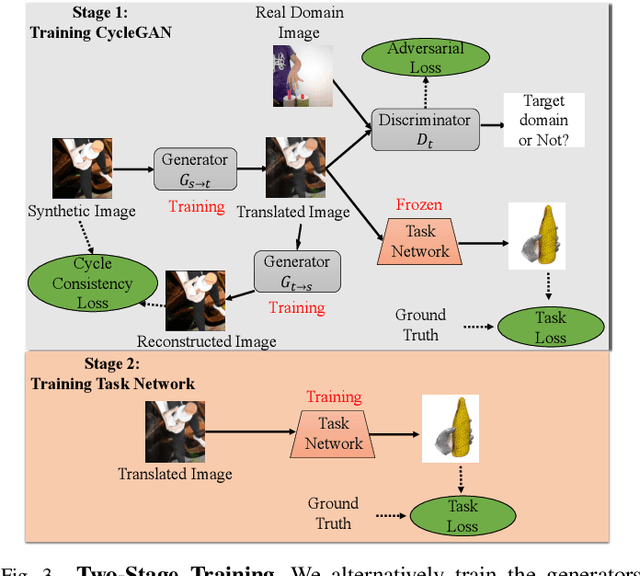
Deep learning-solutions for hand-object 3D pose and shape estimation are now very effective when an annotated dataset is available to train them to handle the scenarios and lighting conditions they will encounter at test time. Unfortunately, this is not always the case, and one often has to resort to training them on synthetic data, which does not guarantee that they will work well in real situations. In this paper, we introduce an effective approach to addressing this challenge by exploiting 3D geometric constraints within a cycle generative adversarial network (CycleGAN) to perform domain adaptation. Furthermore, in contrast to most existing works, which fail to leverage the rich temporal information available in unlabeled real videos as a source of supervision, we propose to enforce short- and long-term temporal consistency to fine-tune the domain-adapted model in a self-supervised fashion. We will demonstrate that our approach outperforms state-of-the-art 3D hand-object joint reconstruction methods on three widely-used benchmarks and will make our code publicly available.
UCLID-Net: Single View Reconstruction in Object Space
Jun 16, 2020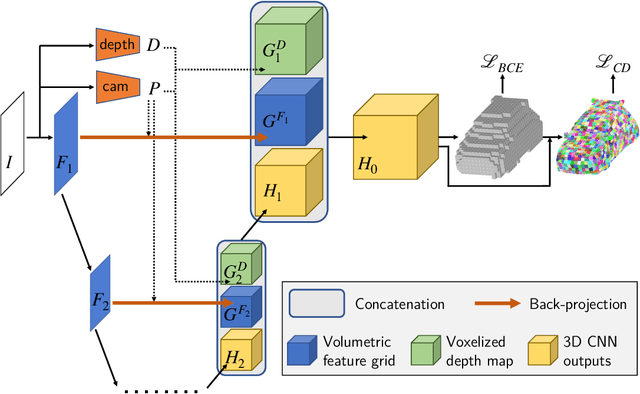

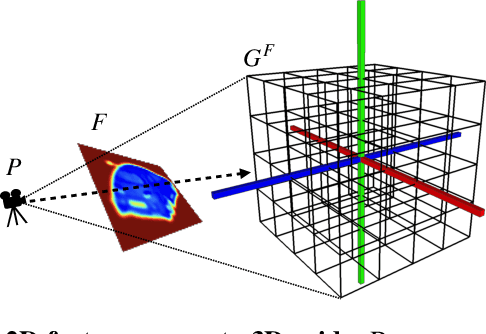

Most state-of-the-art deep geometric learning single-view reconstruction approaches rely on encoder-decoder architectures that output either shape parametrizations or implicit representations. However, these representations rarely preserve the Euclidean structure of the 3D space objects exist in. In this paper, we show that building a geometry preserving 3-dimensional latent space helps the network concurrently learn global shape regularities and local reasoning in the object coordinate space and, as a result, boosts performance. We demonstrate both on ShapeNet synthetic images, which are often used for benchmarking purposes, and on real-world images that our approach outperforms state-of-the-art ones. Furthermore, the single-view pipeline naturally extends to multi-view reconstruction, which we also show.
MeshSDF: Differentiable Iso-Surface Extraction
Jun 06, 2020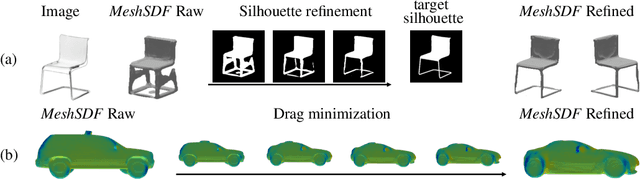
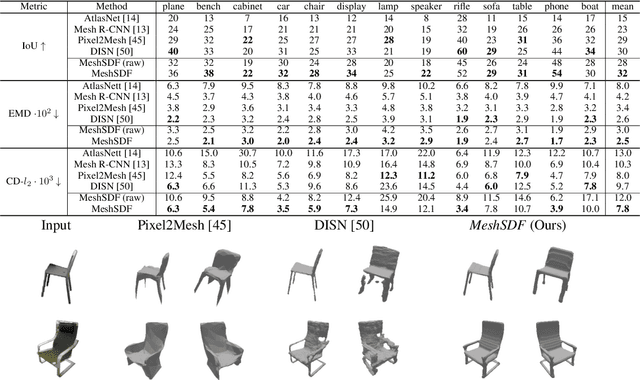
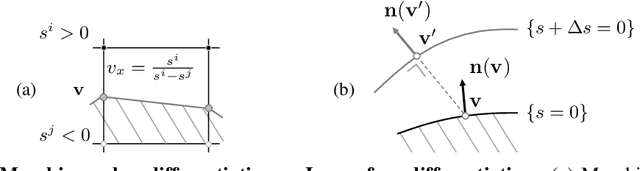
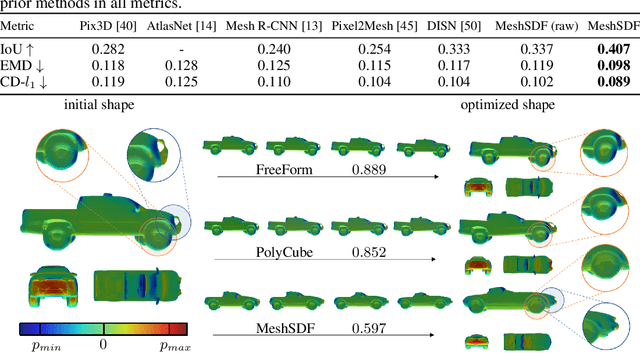
Geometric Deep Learning has recently made striking progress with the advent of continuous Deep Implicit Fields. They allow for detailed modeling of watertight surfaces of arbitrary topology while not relying on a 3D Euclidean grid, resulting in a learnable parameterization that is not limited in resolution. Unfortunately, these methods are often not suitable for applications that require an explicit mesh-based surface representation because converting an implicit field to such a representation relies on the Marching Cubes algorithm, which cannot be differentiated with respect to the underlying implicit field. In this work, we remove this limitation and introduce a differentiable way to produce explicit surface mesh representations from Deep Signed Distance Functions. Our key insight is that by reasoning on how implicit field perturbations impact local surface geometry, one can ultimately differentiate the 3D location of surface samples with respect to the underlying deep implicit field. We exploit this to define MeshSDF, an end-to-end differentiable mesh representation which can vary its topology. We use two different applications to validate our theoretical insight: Single-View Reconstruction via Differentiable Rendering and Physically-Driven Shape Optimization. In both cases our differentiable parameterization gives us an edge over state-of-the-art algorithms.