 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation with Temporal-Consistent Self-Training for 3D Hand-Object Joint Reconstruction
Paper and Code
Dec 21, 2020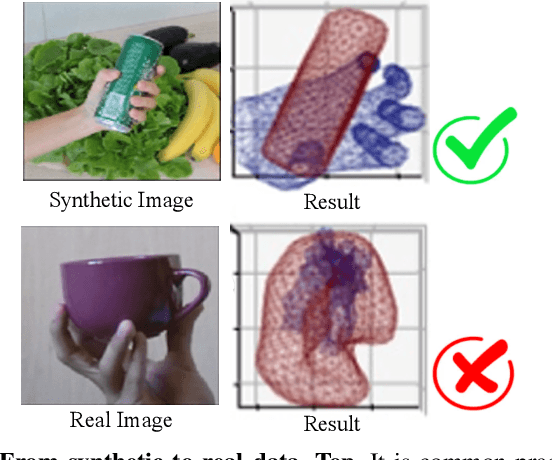
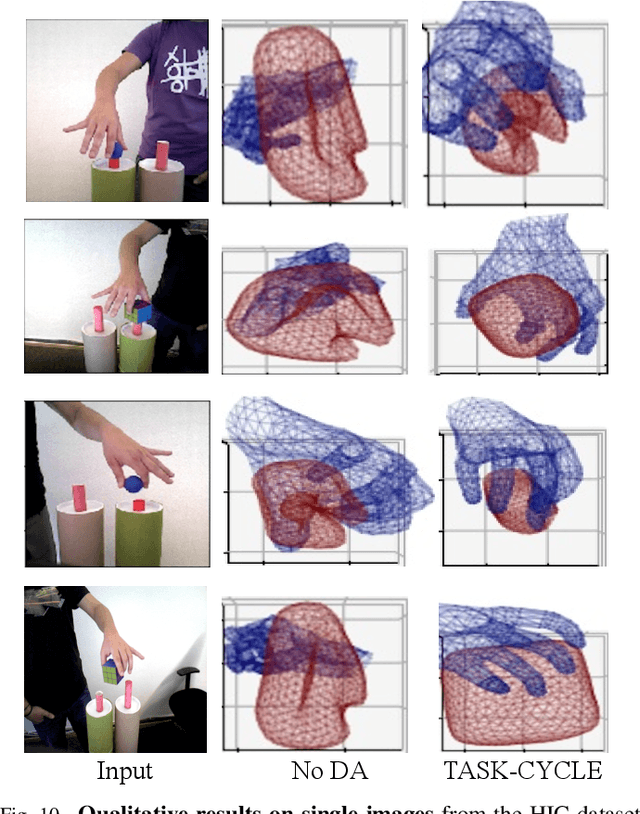
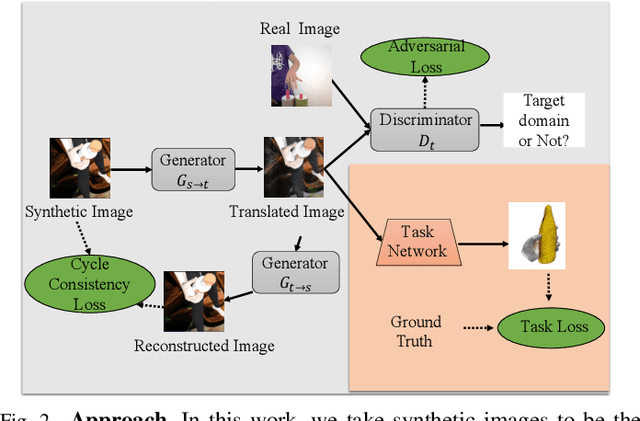
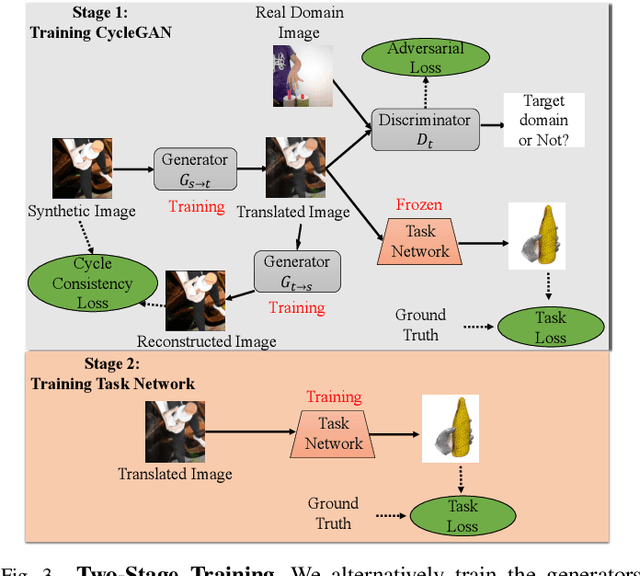
Deep learning-solutions for hand-object 3D pose and shape estimation are now very effective when an annotated dataset is available to train them to handle the scenarios and lighting conditions they will encounter at test time. Unfortunately, this is not always the case, and one often has to resort to training them on synthetic data, which does not guarantee that they will work well in real situations. In this paper, we introduce an effective approach to addressing this challenge by exploiting 3D geometric constraints within a cycle generative adversarial network (CycleGAN) to perform domain adaptation. Furthermore, in contrast to most existing works, which fail to leverage the rich temporal information available in unlabeled real videos as a source of supervision, we propose to enforce short- and long-term temporal consistency to fine-tune the domain-adapted model in a self-supervised fashion. We will demonstrate that our approach outperforms state-of-the-art 3D hand-object joint reconstruction methods on three widely-used benchmarks and will make our code publicly available.