 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Incomplete is Contrastive Learning? An Inter-intra Variant Dual Representation Method for Self-supervised Video Recognition
Paper and Code

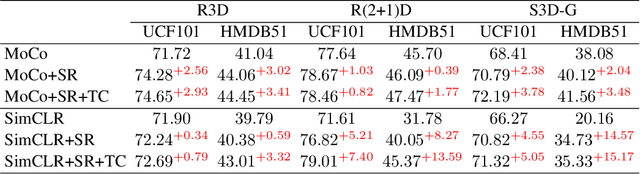
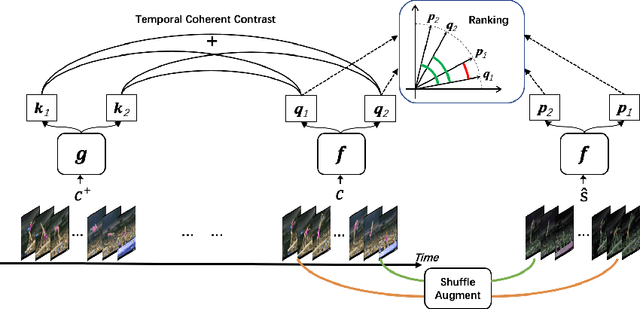
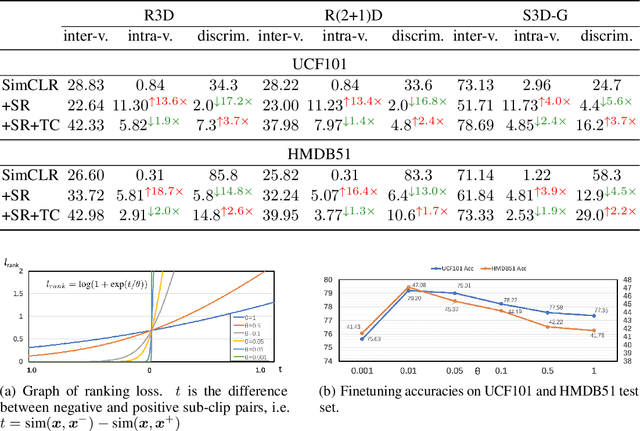
Contrastive learning applied to self-supervised representation learning has seen a resurgence in deep models. In this paper, we find that existing contrastive learning based solutions for self-supervised video recognition focus on inter-variance encoding but ignore the intra-variance existing in clips within the same video. We thus propose to learn dual representations for each clip which (\romannumeral 1) encode intra-variance through a shuffle-rank pretext task; (\romannumeral 2) encode inter-variance through a temporal coherent contrastive loss. Experiment results show that our method plays an essential role in balancing inter and intra variances and brings consistent performance gains on multiple backbones and contrastive learning frameworks. Integrated with SimCLR and pretrained on Kinetics-400, our method achieves $\textbf{82.0\%}$ and $\textbf{51.2\%}$ downstream classification accuracy on UCF101 and HMDB51 test sets respectively and $\textbf{46.1\%}$ video retrieval accuracy on UCF101, outperforming both pretext-task based and contrastive learning based counterparts.