 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
TransMamba: Flexibly Switching between Transformer and Mamba
Mar 31, 2025Transformers are the cornerstone of modern large language models, but their quadratic computational complexity limits efficiency in long-sequence processing. Recent advancements in Mamba, a state space model (SSM) with linear complexity, offer promising efficiency gains but suffer from unstable contextual learning and multitask generalization. This paper proposes TransMamba, a novel framework that unifies Transformer and Mamba through shared parameter matrices (e.g., QKV and CBx), and thus could dynamically switch between attention and SSM mechanisms at different token lengths and layers. We design the Memory converter to bridge Transformer and Mamba by converting attention outputs into SSM-compatible states, ensuring seamless information flow at TransPoints where the transformation happens. The TransPoint scheduling is also thoroughly explored for further improvements. We conducted extensive experiments demonstrating that TransMamba achieves superior training efficiency and performance compared to baselines, and validated the deeper consistency between Transformer and Mamba paradigms, offering a scalable solution for next-generation sequence modeling.
Scaling Laws for Floating Point Quantization Training
Jan 05, 2025



Low-precision training is considered an effective strategy for reducing both training and downstream inference costs. Previous scaling laws for precision mainly focus on integer quantization, which pay less attention to the constituents in floating-point quantization and thus cannot well fit the LLM losses in this scenario. In contrast, while floating-point quantization training is more commonly implemented in production, the research on it has been relatively superficial. In this paper, we thoroughly explore the effects of floating-point quantization targets, exponent bits, mantissa bits, and the calculation granularity of the scaling factor in floating-point quantization training performance of LLM models. While presenting an accurate floating-point quantization unified scaling law, we also provide valuable suggestions for the community: (1) Exponent bits contribute slightly more to the model performance than mantissa bits. We provide the optimal exponent-mantissa bit ratio for different bit numbers, which is available for future reference by hardware manufacturers; (2) We discover the formation of the critical data size in low-precision LLM training. Too much training data exceeding the critical data size will inversely bring in degradation of LLM performance; (3) The optimal floating-point quantization precision is directly proportional to the computational power, but within a wide computational power range, we estimate that the best cost-performance precision lies between 4-8 bits.
VisLingInstruct: Elevating Zero-Shot Learning in Multi-Modal Language Models with Autonomous Instruction Optimization
Feb 12, 2024This paper presents VisLingInstruct, a novel approach to advancing Multi-Modal Language Models (MMLMs) in zero-shot learning. Current MMLMs show impressive zero-shot abilities in multi-modal tasks, but their performance depends heavily on the quality of instructions. VisLingInstruct tackles this by autonomously evaluating and optimizing instructional texts through In-Context Learning, improving the synergy between visual perception and linguistic expression in MMLMs. Alongside this instructional advancement, we have also optimized the visual feature extraction modules in MMLMs, further augmenting their responsiveness to textual cues. Our comprehensive experiments on MMLMs, based on FlanT5 and Vicuna, show that VisLingInstruct significantly improves zero-shot performance in visual multi-modal tasks. Notably, it achieves a 13.1% and 9% increase in accuracy over the prior state-of-the-art on the TextVQA and HatefulMemes datasets.
Multi-task Paired Masking with Alignment Modeling for Medical Vision-Language Pre-training
May 13, 2023



In recent years, the growing demand for medical imaging diagnosis has brought a significant burden to radiologists. The existing Med-VLP methods provide a solution for automated medical image analysis which learns universal representations from large-scale medical images and reports and benefits downstream tasks without requiring fine-grained annotations. However, the existing methods based on joint image-text reconstruction neglect the importance of cross-modal alignment in conjunction with joint reconstruction, resulting in inadequate cross-modal interaction. In this paper, we propose a unified Med-VLP framework based on Multi-task Paired Masking with Alignment (MPMA) to integrate the cross-modal alignment task into the joint image-text reconstruction framework to achieve more comprehensive cross-modal interaction, while a global and local alignment (GLA) module is designed to assist self-supervised paradigm in obtaining semantic representations with rich domain knowledge. To achieve more comprehensive cross-modal fusion, we also propose a Memory-Augmented Cross-Modal Fusion (MA-CMF) module to fully integrate visual features to assist in the process of report reconstruction. Experimental results show that our approach outperforms previous methods over all downstream tasks, including uni-modal, cross-modal and multi-modal tasks.
What Makes Pre-trained Language Models Better Zero/Few-shot Learners?
Sep 30, 2022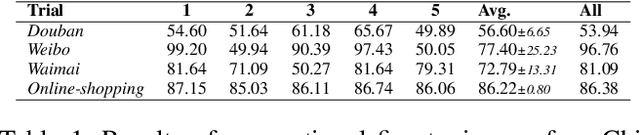

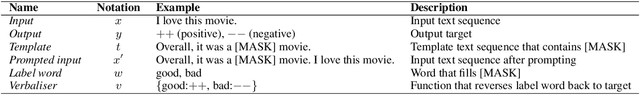
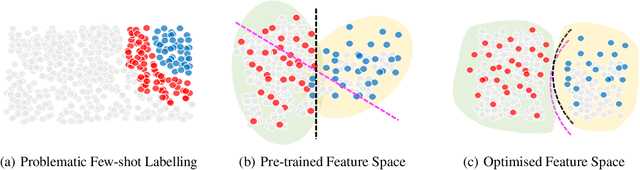
In this paper, we propose a theoretical framework to explain the efficacy of prompt learning in zero/few-shot scenarios. First, we prove that conventional pre-training and fine-tuning paradigm fails in few-shot scenarios due to overfitting the unrepresentative labelled data. We then detail the assumption that prompt learning is more effective because it empowers pre-trained language model that is built upon massive text corpora, as well as domain-related human knowledge to participate more in prediction and thereby reduces the impact of limited label information provided by the small training set. We further hypothesize that language discrepancy can measure the quality of prompting. Comprehensive experiments are performed to verify our assumptions. More remarkably, inspired by the theoretical framework, we propose an annotation-agnostic template selection method based on perplexity, which enables us to ``forecast'' the prompting performance in advance. This approach is especially encouraging because existing work still relies on development set to post-hoc evaluate templates. Experiments show that this method leads to significant prediction benefits compared to state-of-the-art zero-shot methods.
Learning Efficient, Explainable and Discriminative Representations for Pulmonary Nodules Classification
Jan 19, 2021
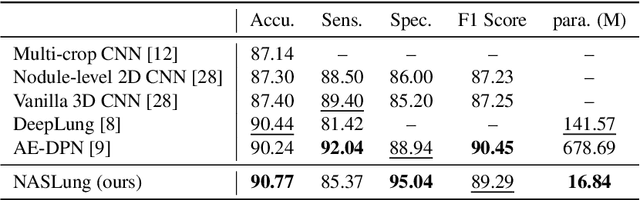
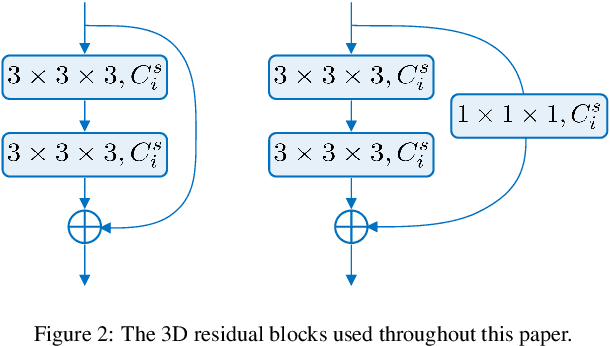
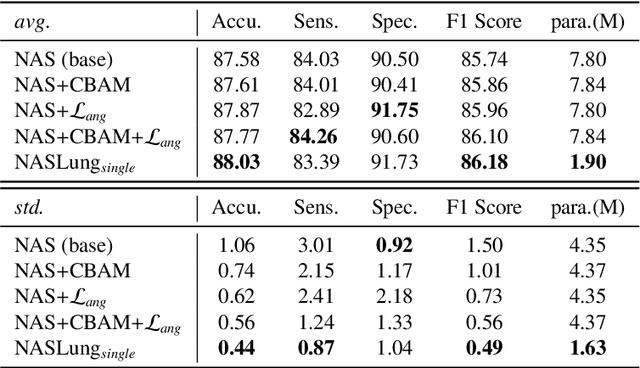
Automatic pulmonary nodules classification is significant for early diagnosis of lung cancers. Recently, deep learning techniques have enabled remarkable progress in this field. However, these deep models are typically of high computational complexity and work in a black-box manner. To combat these challenges, in this work, we aim to build an efficient and (partially) explainable classification model. Specially, we use \emph{neural architecture search} (NAS) to automatically search 3D network architectures with excellent accuracy/speed trade-off. Besides, we use the convolutional block attention module (CBAM) in the networks, which helps us understand the reasoning process. During training, we use A-Softmax loss to learn angularly discriminative representations. In the inference stage, we employ an ensemble of diverse neural networks to improve the prediction accuracy and robustness. We conduct extensive experiments on the LIDC-IDRI database. Compared with previous state-of-the-art, our model shows highly comparable performance by using less than 1/40 parameters. Besides, empirical study shows that the reasoning process of learned networks is in conformity with physicians' diagnosis. Related code and results have been released at: https://github.com/fei-hdu/NAS-Lung.
Probabilistic Group Testing under Sum Observations: A Parallelizable 2-Approximation for Entropy Loss
Sep 23, 2015
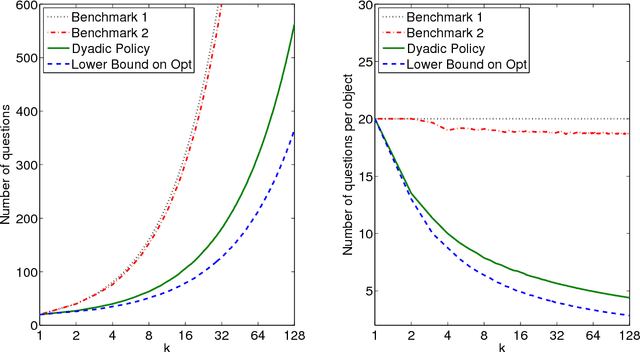
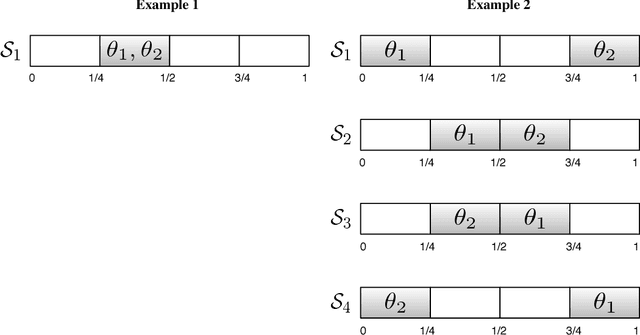
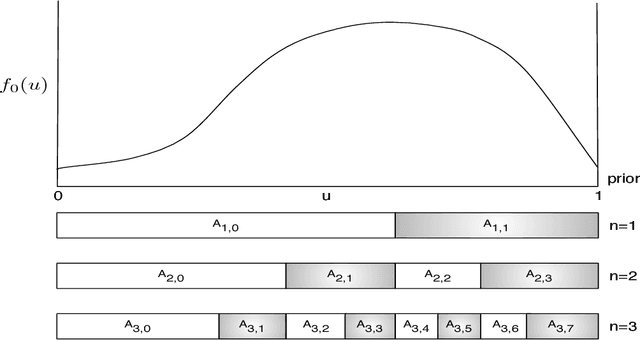
We consider the problem of group testing with sum observations and noiseless answers, in which we aim to locate multiple objects by querying the number of objects in each of a sequence of chosen sets. We study a probabilistic setting with entropy loss, in which we assume a joint Bayesian prior density on the locations of the objects and seek to choose the sets queried to minimize the expected entropy of the Bayesian posterior distribution after a fixed number of questions. We present a new non-adaptive policy, called the dyadic policy, show it is optimal among non-adaptive policies, and is within a factor of two of optimal among adaptive policies. This policy is quick to compute, its nonadaptive nature makes it easy to parallelize, and our bounds show it performs well even when compared with adaptive policies. We also study an adaptive greedy policy, which maximizes the one-step expected reduction in entropy, and show that it performs at least as well as the dyadic policy, offering greater query efficiency but reduced parallelism. Numerical experiments demonstrate that both procedures outperform a divide-and-conquer benchmark policy from the literature, called sequential bifurcation, and show how these procedures may be applied in a stylized computer vision problem.