 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Paired Masking with Alignment Modeling for Medical Vision-Language Pre-training
May 13, 2023



In recent years, the growing demand for medical imaging diagnosis has brought a significant burden to radiologists. The existing Med-VLP methods provide a solution for automated medical image analysis which learns universal representations from large-scale medical images and reports and benefits downstream tasks without requiring fine-grained annotations. However, the existing methods based on joint image-text reconstruction neglect the importance of cross-modal alignment in conjunction with joint reconstruction, resulting in inadequate cross-modal interaction. In this paper, we propose a unified Med-VLP framework based on Multi-task Paired Masking with Alignment (MPMA) to integrate the cross-modal alignment task into the joint image-text reconstruction framework to achieve more comprehensive cross-modal interaction, while a global and local alignment (GLA) module is designed to assist self-supervised paradigm in obtaining semantic representations with rich domain knowledge. To achieve more comprehensive cross-modal fusion, we also propose a Memory-Augmented Cross-Modal Fusion (MA-CMF) module to fully integrate visual features to assist in the process of report reconstruction. Experimental results show that our approach outperforms previous methods over all downstream tasks, including uni-modal, cross-modal and multi-modal tasks.
Learning Efficient, Explainable and Discriminative Representations for Pulmonary Nodules Classification
Jan 19, 2021
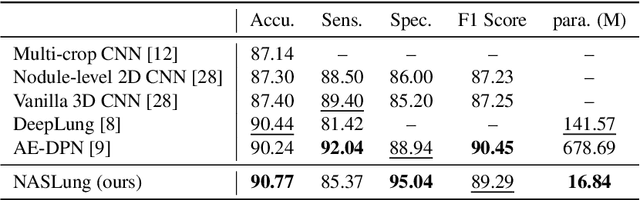
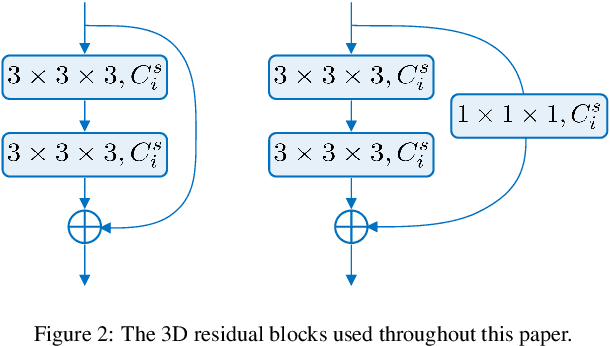
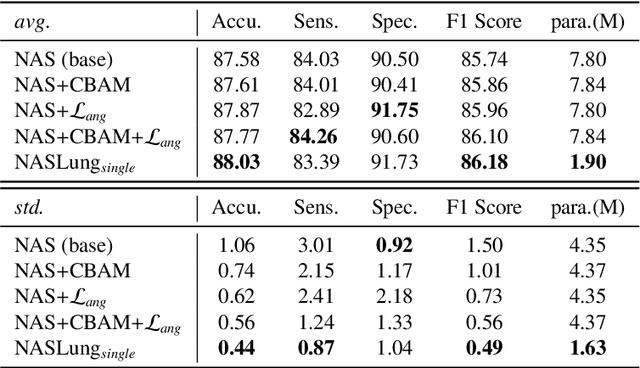
Automatic pulmonary nodules classification is significant for early diagnosis of lung cancers. Recently, deep learning techniques have enabled remarkable progress in this field. However, these deep models are typically of high computational complexity and work in a black-box manner. To combat these challenges, in this work, we aim to build an efficient and (partially) explainable classification model. Specially, we use \emph{neural architecture search} (NAS) to automatically search 3D network architectures with excellent accuracy/speed trade-off. Besides, we use the convolutional block attention module (CBAM) in the networks, which helps us understand the reasoning process. During training, we use A-Softmax loss to learn angularly discriminative representations. In the inference stage, we employ an ensemble of diverse neural networks to improve the prediction accuracy and robustness. We conduct extensive experiments on the LIDC-IDRI database. Compared with previous state-of-the-art, our model shows highly comparable performance by using less than 1/40 parameters. Besides, empirical study shows that the reasoning process of learned networks is in conformity with physicians' diagnosis. Related code and results have been released at: https://github.com/fei-hdu/NAS-Lung.