 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis on Quantizing Diffusion Transformers
Jun 16, 2024


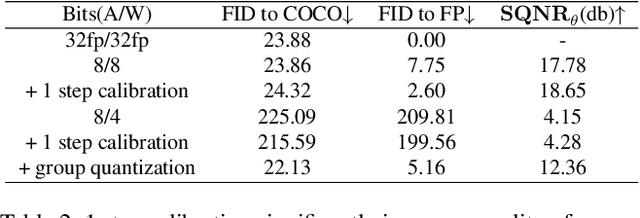
Diffusion Models (DMs) utilize an iterative denoising process to transform random noise into synthetic data. Initally proposed with a UNet structure, DMs excel at producing images that are virtually indistinguishable with or without conditioned text prompts. Later transformer-only structure is composed with DMs to achieve better performance. Though Latent Diffusion Models (LDMs) reduce the computational requirement by denoising in a latent space, it is extremely expensive to inference images for any operating devices due to the shear volume of parameters and feature sizes. Post Training Quantization (PTQ) offers an immediate remedy for a smaller storage size and more memory-efficient computation during inferencing. Prior works address PTQ of DMs on UNet structures have addressed the challenges in calibrating parameters for both activations and weights via moderate optimization. In this work, we pioneer an efficient PTQ on transformer-only structure without any optimization. By analysing challenges in quantizing activations and weights for diffusion transformers, we propose a single-step sampling calibration on activations and adapt group-wise quantization on weights for low-bit quantization. We demonstrate the efficiency and effectiveness of proposed methods with preliminary experiments on conditional image generation.
Efficient Quantization Strategies for Latent Diffusion Models
Dec 09, 2023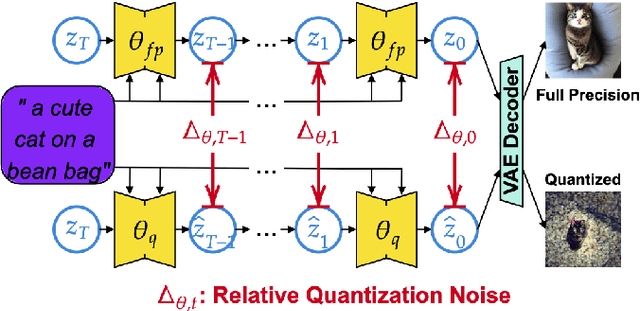



Latent Diffusion Models (LDMs) capture the dynamic evolution of latent variables over time, blending patterns and multimodality in a generative system. Despite the proficiency of LDM in various applications, such as text-to-image generation, facilitated by robust text encoders and a variational autoencoder, the critical need to deploy large generative models on edge devices compels a search for more compact yet effective alternatives. Post Training Quantization (PTQ), a method to compress the operational size of deep learning models, encounters challenges when applied to LDM due to temporal and structural complexities. This study proposes a quantization strategy that efficiently quantize LDMs, leveraging Signal-to-Quantization-Noise Ratio (SQNR) as a pivotal metric for evaluation. By treating the quantization discrepancy as relative noise and identifying sensitive part(s) of a model, we propose an efficient quantization approach encompassing both global and local strategies. The global quantization process mitigates relative quantization noise by initiating higher-precision quantization on sensitive blocks, while local treatments address specific challenges in quantization-sensitive and time-sensitive modules. The outcomes of our experiments reveal that the implementation of both global and local treatments yields a highly efficient and effective Post Training Quantization (PTQ) of LDMs.
Stable and Causal Inference for Discriminative Self-supervised Deep Visual Representations
Aug 16, 2023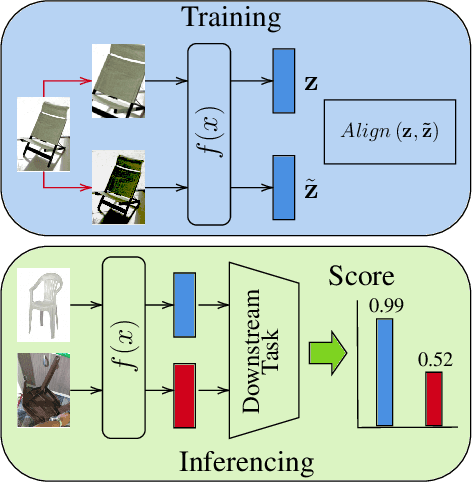
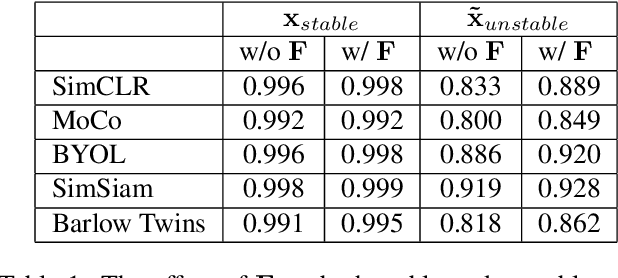
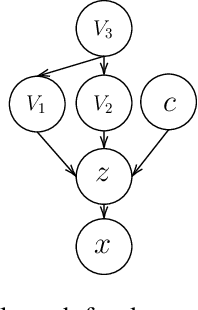
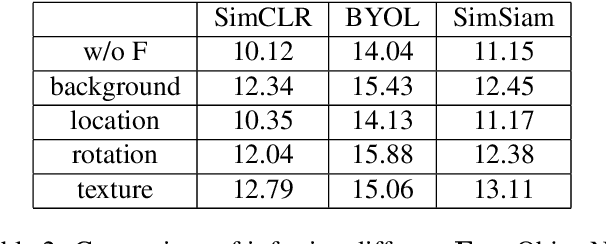
In recent years, discriminative self-supervised methods have made significant strides in advancing various visual tasks. The central idea of learning a data encoder that is robust to data distortions/augmentations is straightforward yet highly effective. Although many studies have demonstrated the empirical success of various learning methods, the resulting learned representations can exhibit instability and hinder downstream performance. In this study, we analyze discriminative self-supervised methods from a causal perspective to explain these unstable behaviors and propose solutions to overcome them. Our approach draws inspiration from prior works that empirically demonstrate the ability of discriminative self-supervised methods to demix ground truth causal sources to some extent. Unlike previous work on causality-empowered representation learning, we do not apply our solutions during the training process but rather during the inference process to improve time efficiency. Through experiments on both controlled image datasets and realistic image datasets, we show that our proposed solutions, which involve tempering a linear transformation with controlled synthetic data, are effective in addressing these issues.
More Generalized and Personalized Unsupervised Representation Learning In A Distributed System
Nov 11, 2022Discriminative unsupervised learning methods such as contrastive learning have demonstrated the ability to learn generalized visual representations on centralized data. It is nonetheless challenging to adapt such methods to a distributed system with unlabeled, private, and heterogeneous client data due to user styles and preferences. Federated learning enables multiple clients to collectively learn a global model without provoking any privacy breach between local clients. On the other hand, another direction of federated learning studies personalized methods to address the local heterogeneity. However, work on solving both generalization and personalization without labels in a decentralized setting remains unfamiliar. In this work, we propose a novel method, FedStyle, to learn a more generalized global model by infusing local style information with local content information for contrastive learning, and to learn more personalized local models by inducing local style information for downstream tasks. The style information is extracted by contrasting original local data with strongly augmented local data (Sobel filtered images). Through extensive experiments with linear evaluations in both IID and non-IID settings, we demonstrate that FedStyle outperforms both the generalization baseline methods and personalization baseline methods in a stylized decentralized setting. Through comprehensive ablations, we demonstrate our design of style infusion and stylized personalization improve performance significantly.
Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization
Jul 02, 2021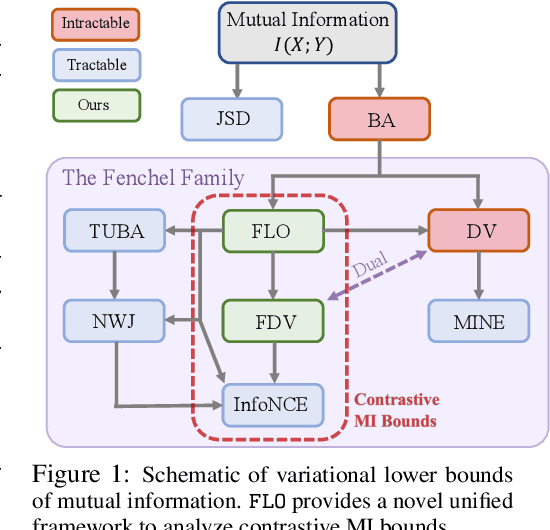
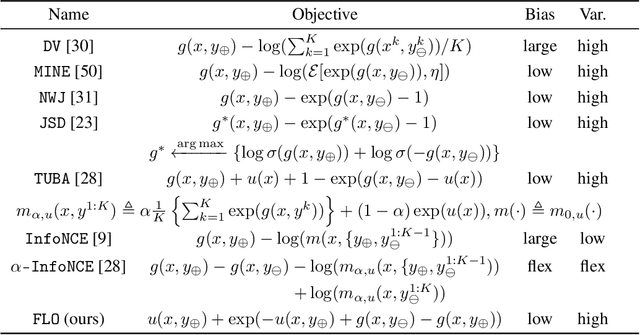
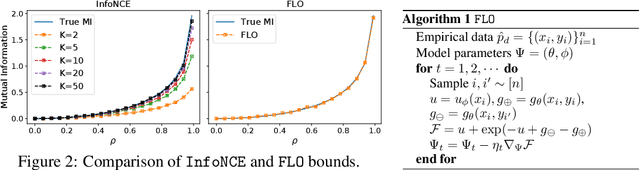

Successful applications of InfoNCE and its variants have popularized the use of contrastive variational mutual information (MI) estimators in machine learning. While featuring superior stability, these estimators crucially depend on costly large-batch training, and they sacrifice bound tightness for variance reduction. To overcome these limitations, we revisit the mathematics of popular variational MI bounds from the lens of unnormalized statistical modeling and convex optimization. Our investigation not only yields a new unified theoretical framework encompassing popular variational MI bounds but also leads to a novel, simple, and powerful contrastive MI estimator named as FLO. Theoretically, we show that the FLO estimator is tight, and it provably converges under stochastic gradient descent. Empirically, our FLO estimator overcomes the limitations of its predecessors and learns more efficiently. The utility of FLO is verified using an extensive set of benchmarks, which also reveals the trade-offs in practical MI estimation.
Proactive Pseudo-Intervention: Causally Informed Contrastive Learning For Interpretable Vision Models
Dec 06, 2020

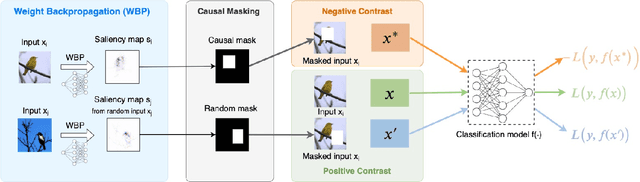
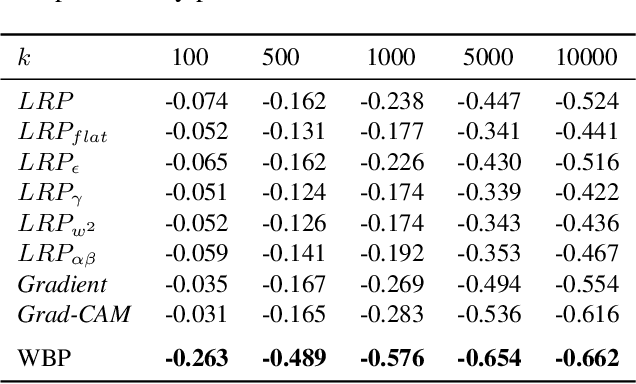
Deep neural networks have shown significant promise in comprehending complex visual signals, delivering performance on par or even superior to that of human experts. However, these models often lack a mechanism for interpreting their predictions, and in some cases, particularly when the sample size is small, existing deep learning solutions tend to capture spurious correlations that compromise model generalizability on unseen inputs. In this work, we propose a contrastive causal representation learning strategy that leverages proactive interventions to identify causally-relevant image features, called Proactive Pseudo-Intervention (PPI). This approach is complemented with a causal salience map visualization module, i.e., Weight Back Propagation (WBP), that identifies important pixels in the raw input image, which greatly facilitates the interpretability of predictions. To validate its utility, our model is benchmarked extensively on both standard natural images and challenging medical image datasets. We show this new contrastive causal representation learning model consistently improves model performance relative to competing solutions, particularly for out-of-domain predictions or when dealing with data integration from heterogeneous sources. Further, our causal saliency maps are more succinct and meaningful relative to their non-causal counterparts.
Object Detection as a Positive-Unlabeled Problem
Feb 11, 2020



As with other deep learning methods, label quality is important for learning modern convolutional object detectors. However, the potentially large number and wide diversity of object instances that can be found in complex image scenes makes constituting complete annotations a challenging task; objects missing annotations can be observed in a variety of popular object detection datasets. These missing annotations can be problematic, as the standard cross-entropy loss employed to train object detection models treats classification as a positive-negative (PN) problem: unlabeled regions are implicitly assumed to be background. As such, any object missing a bounding box results in a confusing learning signal, the effects of which we observe empirically. To remedy this, we propose treating object detection as a positive-unlabeled (PU) problem, which removes the assumption that unlabeled regions must be negative. We demonstrate that our proposed PU classification loss outperforms the standard PN loss on PASCAL VOC and MS COCO across a range of label missingness, as well as on Visual Genome and DeepLesion with full labels.