 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantization Strategies for Latent Diffusion Models
Paper and Code
Dec 09, 2023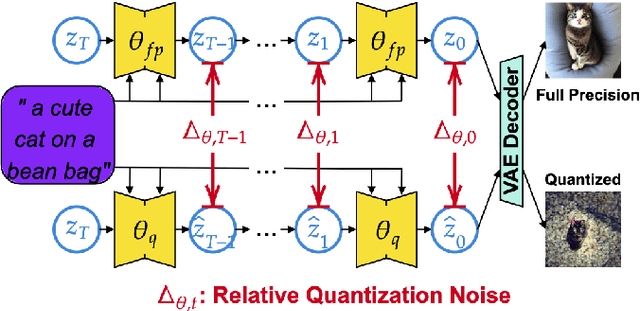



Latent Diffusion Models (LDMs) capture the dynamic evolution of latent variables over time, blending patterns and multimodality in a generative system. Despite the proficiency of LDM in various applications, such as text-to-image generation, facilitated by robust text encoders and a variational autoencoder, the critical need to deploy large generative models on edge devices compels a search for more compact yet effective alternatives. Post Training Quantization (PTQ), a method to compress the operational size of deep learning models, encounters challenges when applied to LDM due to temporal and structural complexities. This study proposes a quantization strategy that efficiently quantize LDMs, leveraging Signal-to-Quantization-Noise Ratio (SQNR) as a pivotal metric for evaluation. By treating the quantization discrepancy as relative noise and identifying sensitive part(s) of a model, we propose an efficient quantization approach encompassing both global and local strategies. The global quantization process mitigates relative quantization noise by initiating higher-precision quantization on sensitive blocks, while local treatments address specific challenges in quantization-sensitive and time-sensitive modules. The outcomes of our experiments reveal that the implementation of both global and local treatments yields a highly efficient and effective Post Training Quantization (PTQ) of LDMs.