 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Self-Supervised Audio-Visual Representations for Sound Recommendations
Dec 10, 2024We propose a novel self-supervised approach for learning audio and visual representations from unlabeled videos, based on their correspondence. The approach uses an attention mechanism to learn the relative importance of convolutional features extracted at different resolutions from the audio and visual streams and uses the attention features to encode the audio and visual input based on their correspondence. We evaluated the representations learned by the model to classify audio-visual correlation as well as to recommend sound effects for visual scenes. Our results show that the representations generated by the attention model improves the correlation accuracy compared to the baseline, by 18% and the recommendation accuracy by 10% for VGG-Sound, which is a public video dataset. Additionally, audio-visual representations learned by training the attention model with cross-modal contrastive learning further improves the recommendation performance, based on our evaluation using VGG-Sound and a more challenging dataset consisting of gameplay video recordings.
DiffSign: AI-Assisted Generation of Customizable Sign Language Videos With Enhanced Realism
Dec 05, 2024



The proliferation of several streaming services in recent years has now made it possible for a diverse audience across the world to view the same media content, such as movies or TV shows. While translation and dubbing services are being added to make content accessible to the local audience, the support for making content accessible to people with different abilities, such as the Deaf and Hard of Hearing (DHH) community, is still lagging. Our goal is to make media content more accessible to the DHH community by generating sign language videos with synthetic signers that are realistic and expressive. Using the same signer for a given media content that is viewed globally may have limited appeal. Hence, our approach combines parametric modeling and generative modeling to generate realistic-looking synthetic signers and customize their appearance based on user preferences. We first retarget human sign language poses to 3D sign language avatars by optimizing a parametric model. The high-fidelity poses from the rendered avatars are then used to condition the poses of synthetic signers generated using a diffusion-based generative model. The appearance of the synthetic signer is controlled by an image prompt supplied through a visual adapter. Our results show that the sign language videos generated using our approach have better temporal consistency and realism than signing videos generated by a diffusion model conditioned only on text prompts. We also support multimodal prompts to allow users to further customize the appearance of the signer to accommodate diversity (e.g. skin tone, gender). Our approach is also useful for signer anonymization.
Image Captioning with Integrated Bottom-Up and Multi-level Residual Top-Down Attention for Game Scene Understanding
Jun 16, 2019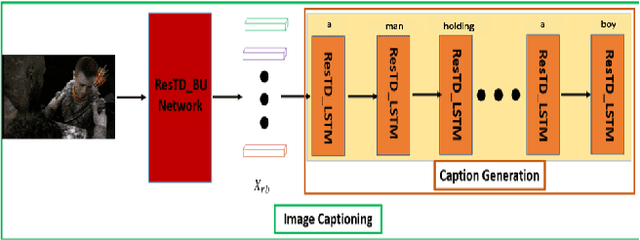

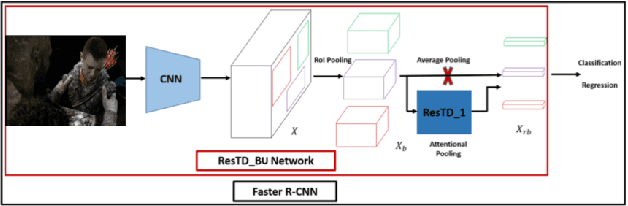
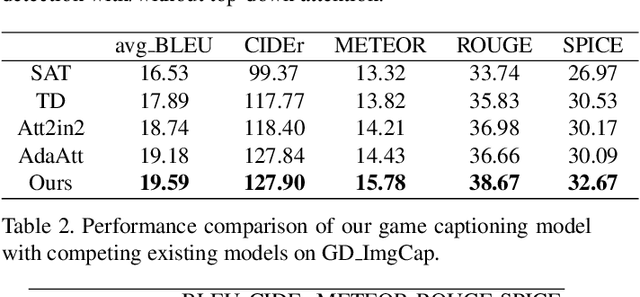
Image captioning has attracted considerable attention in recent years. However, little work has been done for game image captioning which has some unique characteristics and requirements. In this work we propose a novel game image captioning model which integrates bottom-up attention with a new multi-level residual top-down attention mechanism. Firstly, a lower-level residual top-down attention network is added to the Faster R-CNN based bottom-up attention network to address the problem that the latter may lose important spatial information when extracting regional features. Secondly, an upper-level residual top-down attention network is implemented in the caption generation network to better fuse the extracted regional features for subsequent caption prediction. We create two game datasets to evaluate the proposed model. Extensive experiments show that our proposed model outperforms existing baseline models.