 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNowYouSee Me: Context-Aware Automatic Audio Description
Dec 13, 2024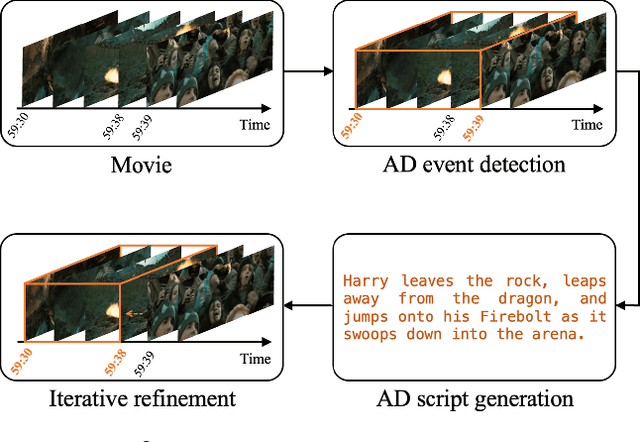
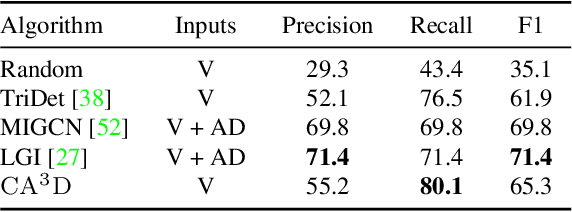
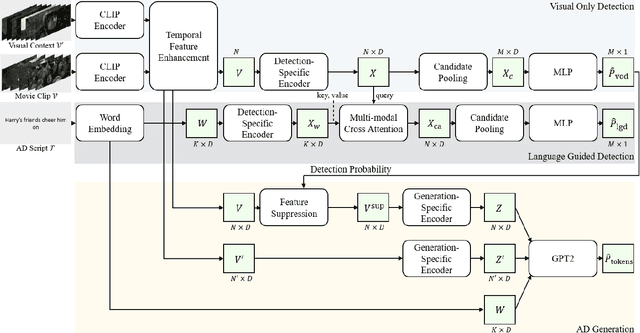

Audio Description (AD) plays a pivotal role as an application system aimed at guaranteeing accessibility in multimedia content, which provides additional narrations at suitable intervals to describe visual elements, catering specifically to the needs of visually impaired audiences. In this paper, we introduce $\mathrm{CA^3D}$, the pioneering unified Context-Aware Automatic Audio Description system that provides AD event scripts with precise locations in the long cinematic content. Specifically, $\mathrm{CA^3D}$ system consists of: 1) a Temporal Feature Enhancement Module to efficiently capture longer term dependencies, 2) an anchor-based AD event detector with feature suppression module that localizes the AD events and extracts discriminative feature for AD generation, and 3) a self-refinement module that leverages the generated output to tweak AD event boundaries from coarse to fine. Unlike conventional methods which rely on metadata and ground truth AD timestamp for AD detection and generation tasks, the proposed $\mathrm{CA^3D}$ is the first end-to-end trainable system that only uses visual cue. Extensive experiments demonstrate that the proposed $\mathrm{CA^3D}$ improves existing architectures for both AD event detection and script generation metrics, establishing the new state-of-the-art performances in the AD automation.
* 10 pages
Video Token Merging for Long-form Video Understanding
Oct 31, 2024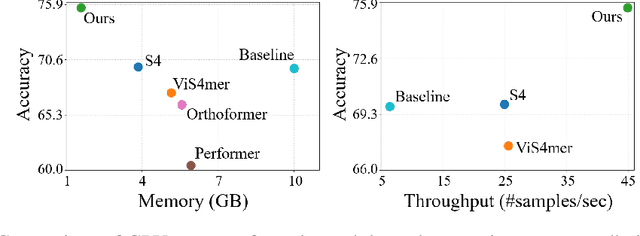
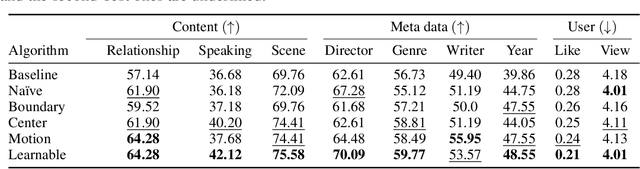
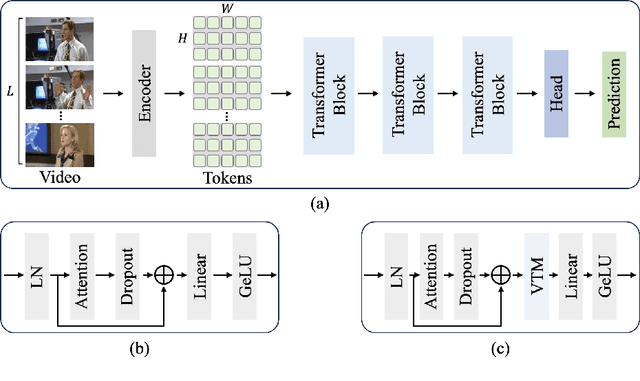
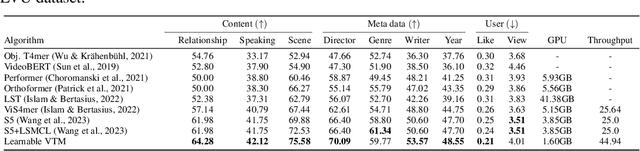
As the scale of data and models for video understanding rapidly expand, handling long-form video input in transformer-based models presents a practical challenge. Rather than resorting to input sampling or token dropping, which may result in information loss, token merging shows promising results when used in collaboration with transformers. However, the application of token merging for long-form video processing is not trivial. We begin with the premise that token merging should not rely solely on the similarity of video tokens; the saliency of tokens should also be considered. To address this, we explore various video token merging strategies for long-form video classification, starting with a simple extension of image token merging, moving to region-concentrated merging, and finally proposing a learnable video token merging (VTM) algorithm that dynamically merges tokens based on their saliency. Extensive experimental results show that we achieve better or comparable performances on the LVU, COIN, and Breakfast datasets. Moreover, our approach significantly reduces memory costs by 84% and boosts throughput by approximately 6.89 times compared to baseline algorithms.
* 21 pages, NeurIPS 2024
MFP: Making Full Use of Probability Maps for Interactive Image Segmentation
Apr 29, 2024In recent interactive segmentation algorithms, previous probability maps are used as network input to help predictions in the current segmentation round. However, despite the utilization of previous masks, useful information contained in the probability maps is not well propagated to the current predictions. In this paper, to overcome this limitation, we propose a novel and effective algorithm for click-based interactive image segmentation, called MFP, which attempts to make full use of probability maps. We first modulate previous probability maps to enhance their representations of user-specified objects. Then, we feed the modulated probability maps as additional input to the segmentation network. We implement the proposed MFP algorithm based on the ResNet-34, HRNet-18, and ViT-B backbones and assess the performance extensively on various datasets. It is demonstrated that MFP meaningfully outperforms the existing algorithms using identical backbones. The source codes are available at \href{https://github.com/cwlee00/MFP}{https://github.com/cwlee00/MFP}.
Moving Window Regression: A Novel Approach to Ordinal Regression
Mar 24, 2022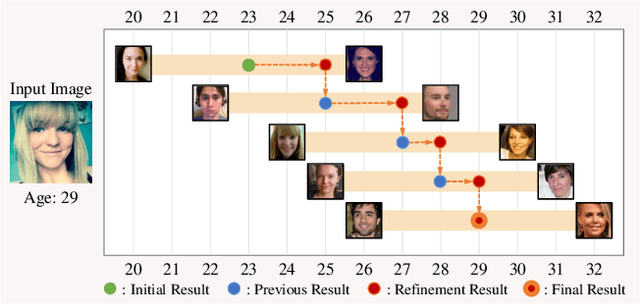
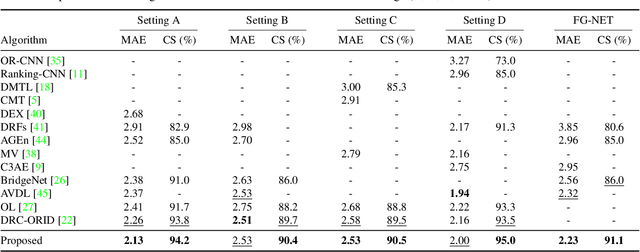
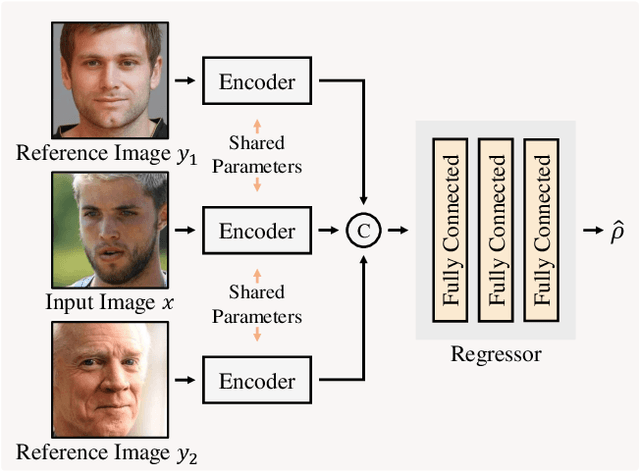
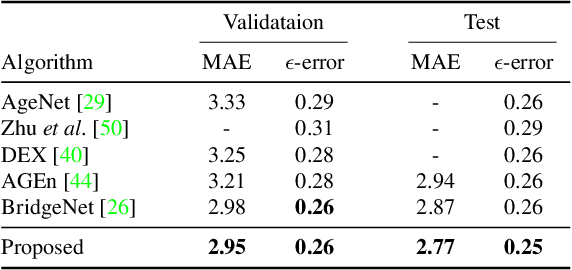
A novel ordinal regression algorithm, called moving window regression (MWR), is proposed in this paper. First, we propose the notion of relative rank ($\rho$-rank), which is a new order representation scheme for input and reference instances. Second, we develop global and local relative regressors ($\rho$-regressors) to predict $\rho$-ranks within entire and specific rank ranges, respectively. Third, we refine an initial rank estimate iteratively by selecting two reference instances to form a search window and then estimating the $\rho$-rank within the window. Extensive experiments results show that the proposed algorithm achieves the state-of-the-art performances on various benchmark datasets for facial age estimation and historical color image classification. The codes are available at https://github.com/nhshin-mcl/MWR.